一种数字人生成方法及系统与流程
本发明涉及计算机视觉和计算机图形学,特别涉及一种数字人生成方法及系统。
背景技术:
1、随着aigc的快速发展,数字人已经广泛应用于多个领域,例如直播、客服和播报等。这些数字人具备逼真的外貌、肢体动作和声音,以及与人类相似的语音发音习惯和语言理解能力,可以进行互动式对话、回答问题、提供建议等,已经能够很好地满足当前的需求
2、在进行二维数字人驱动时,通常采用文本驱动,即用户输入一段文字,数字人根据输入文本进行口部动画生成,而肢体姿态动画则由用户自主选择,最后通过连续的姿态动画拼接为一段数字人视频,常用于数字人播报等无交互的制作场景。
3、在二维数字人实时交互场景,如直播、智能客服等,文本通常是预置的。然而,由于无人对数字人进行操作,姿态动画无法与文本相匹配,常采用下述两种方法进行解决:姿态保持静态只有嘴部动画;随机动作,动作之间通常是完成了第一个动作后回复为原始状态再开始第二个动作。但是这两种方法难以保证文本语义与动作的匹配,导致人机交互体验较差。
技术实现思路
1、本发明的目的在于针对上述现有技术的不足,提供一种数字人生成方法及系统,以解决现有技术中的方法没有保证文本语义与动作的匹配,导致人机交互体验较差的问题。
2、本发明具体提供如下技术方案:一种数字人生成方法,包括如下步骤:
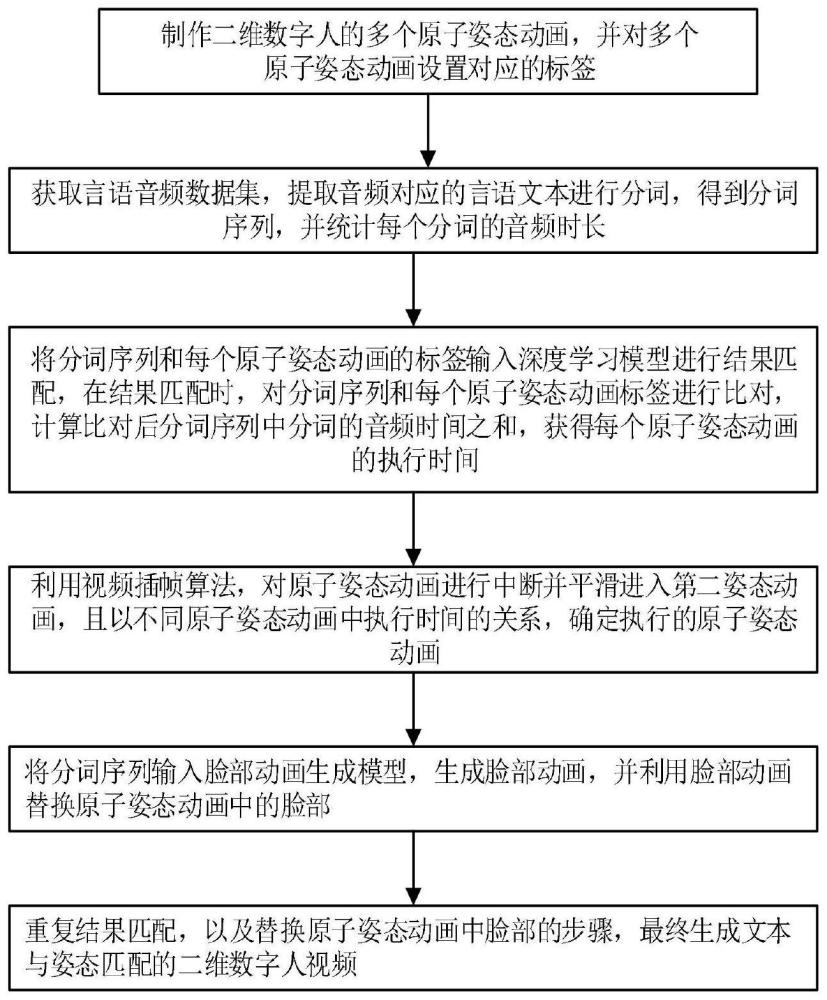
3、制作目标二维数字人的多个原子姿态动画,并对多个所述原子姿态动画设置对应的标签;
4、获取言语音频数据集,并从所述言语音频数据集中提取音频对应的言语文本进行分词,得到分词序列,并统计每个分词的音频时间;
5、将所述分词序列和每个原子姿态动画的标签输入深度学习模型进行结果匹配,在所述结果匹配时,对分词序列和每个原子姿态动画标签进行比对,计算比对后分词序列中分词的音频时间之和,获得每个原子姿态动画的执行时间;
6、利用视频插帧算法,对第一原子姿态动画进行中断并平滑进入第二原子姿态动画,且以两种不同原子姿态动画中执行时间的关系,确定需要执行的原子姿态动画;
7、将所述分词序列输入脸部动画生成模型,生成脸部动画,并利用所述脸部动画替换已确定需要执行原子姿态动画中的脸部;
8、重复所述结果匹配,以及替换已确定需要执行原子姿态动画中脸部的步骤,最终生成文本与姿态匹配的目标二维数字人视频。
9、优选的,所述制作目标二维数字人的多个原子姿态动画,并对多个所述原子姿态动画设置对应的标签,其中多个原子姿态动画为{a1,a2,…,an},所述标签为{p1,p2,…,pn}、{n1,n2,…,nn},其中n、m为自然数,p和n标签代表原子姿态动画的使用场景。
10、优选的,所述对分词序列和每个原子姿态动画标签进行比对,计算比对后分词序列中分词的音频时间之和,获得每个原子姿态动画的执行时间,包括如下步骤:
11、若对深度学习模型输入一个分词,所述深度学习模型输出为对应的一个原子姿态动画标签;
12、若一个所述原子姿态动画标签对应某段话中的多个分词时,计算分词音频时间之和,获得原子姿态动画的执行时间ta。
13、优选的,所述以两种不同原子姿态动画中执行时间的关系,确定需要执行的原子姿态动画,包括如下步骤:
14、获取第一原子姿态动画ai和第二原子姿态动画aj;其中,1≤i、j≤n且i≠j;
15、若tai小于tsi+tli,对动画进行加速,当执行时间结束时显示原子姿态动画ai动画帧2,完成完整姿态动作,然后执行第二原子姿态动画aj;
16、若tai大于tsi+tli+tei,动画执行到第一原子姿态动画ai动画帧2时,增加tai-(tsi+tli+tei)的循环时间,以保证tei结束时原子姿态动画ai执行完成,然后开始执行第二原子姿态动画aj;
17、若tai大于tsi+tli,动画执行到第一原子姿态动画ai动画帧2时,使用视频插帧算法过渡到第二原子姿态动画aj动画帧1,过渡时间为tsj;
18、其中,tai为第一原子姿态动画ai的时间;tsi为第一原子姿态动画ai起始帧到动画帧1的时间;tli为动画帧1到动画帧2的时间;tei为第一原子姿态动画ai动画帧2到结束帧的时间。
19、优选的,所述原子姿态动画包括四个关键帧,即起始帧、动画帧1、动画帧2、结束帧,其中起始帧到动画帧1为动作准备时间,时间为ts,动画帧1到动画帧2为动作执行时间,时间为tl,动画帧2到结束帧为恢复原始姿态过程,时间为te。
20、优选的,所述制作目标二维数字人的多个原子姿态动画之前,制定姿态动画体系,确定数字人具备的姿态动作,所述姿态动作包括打招呼、挥手、向左看。
21、优选的,利用数字人第一个动作后紧随的第二个动作制作所述第二原子姿态动画。
22、优选的,所述脸部动画包括表情动画和嘴部动画。
23、优选的,所述分词序列包括主语、谓语、宾语、定语、状语。
24、优选的,本发明还包括一种数字人生成系统,包括:
25、动画制作模块,用于制作目标二维数字人的多个原子姿态动画,并对多个所述原子姿态动画设置对应的标签;
26、文本与音频处理模块,用于获取言语音频数据集,并从所述言语音频数据集中提取音频对应的言语文本进行分词,得到分词序列,并统计每个分词的音频时间;
27、匹配模块,用于将所述分词序列和每个原子姿态动画的标签输入深度学习模型进行结果匹配,在所述结果匹配时,对分词序列和每个原子姿态动画标签进行比对,计算比对后分词序列中分词的音频时间之和,获得每个原子姿态动画的执行时间;
28、动画执行模块,用于利用视频插帧算法,对第一原子姿态动画进行中断并平滑进入第二原子姿态动画,且以两种不同原子姿态动画中执行时间的关系,确定需要执行的原子姿态动画;
29、脸部动画生成模块,用于将所述分词序列输入脸部动画生成模型,生成脸部动画,并利用所述脸部动画替换已确定需要执行原子姿态动画中的脸部;
30、输出模块,用于重复所述结果匹配,以及替换已确定需要执行原子姿态动画中脸部的步骤,最终生成文本与姿态匹配的目标二维数字人视频。
31、与现有技术相比,本发明具有如下显著优点:
32、本发明通过获取的原子姿态动画和言语音频数据,制作原子姿态动画设置对应的标签和分词序列及分词音频时间,并将标签与分词序列进行结果匹配,从而实现文本与原子姿态动画的匹配,在数字人交互场景,并通过视频插帧算法构建第二原子姿态动画,替换已确定执行原子姿态动画中的脸部,从而数字人可以根据内置文本,针对性进行姿态交互,并通过插帧算法实现姿态动画之间的平滑过渡,增强人机交互体验。
技术特征:
1.一种数字人生成方法,其特征在于,包括如下步骤:
2.如权利要求1所述的一种数字人生成方法,其特征在于,所述制作目标二维数字人的多个原子姿态动画,并对多个所述原子姿态动画设置对应的标签,其中多个原子姿态动画为{a1,a2,…,an},所述标签为{p1,p2,…,pn}、{n1,n2,…,nn},其中n、m为自然数,p和n标签代表原子姿态动画的使用场景。
3.如权利要求2所述的一种数字人生成方法,其特征在于,所述对分词序列和每个原子姿态动画标签进行比对,计算比对后分词序列中分词的音频时间之和,获得每个原子姿态动画的执行时间,包括如下步骤:
4.如权利要求3所述的一种数字人生成方法,其特征在于,所述以两种不同原子姿态动画中执行时间的关系,确定需要执行的原子姿态动画,包括如下步骤:
5.如权利要求1所述的一种数字人生成方法,其特征在于,所述原子姿态动画包括四个关键帧,即起始帧、动画帧1、动画帧2、结束帧,其中起始帧到动画帧1为动作准备时间,时间为ts,动画帧1到动画帧2为动作执行时间,时间为tl,动画帧2到结束帧为恢复原始姿态过程,时间为te。
6.如权利要求1所述的一种数字人生成方法,其特征在于,所述制作目标二维数字人的多个原子姿态动画之前,制定姿态动画体系,确定数字人具备的姿态动作,所述姿态动作包括打招呼、挥手、向左看。
7.如权利要求1所述的一种数字人生成方法,其特征在于,利用数字人第一个动作后紧随的第二个动作制作所述第二原子姿态动画。
8.如权利要求1所述的一种数字人生成方法,其特征在于,所述脸部动画包括表情动画和嘴部动画。
9.如权利要求1所述的一种数字人生成方法,其特征在于,所述分词序列包括主语、谓语、宾语、定语、状语。
10.一种数字人生成系统,其特征在于,包括:
技术总结
本发明公开了一种数字人生成方法及系统,涉及计算机视觉和计算机图形学技术领域,包括步骤:对二维数字人的多个原子姿态动画设置对应的标签;获取言语音频数据集,提取音频对应的言语文本进行分词,得到分词序列,并统计每个分词的音频时间;计算分词音频时间之和获得执行时间;以不同原子姿态动画中执行时间的关系,确定原子姿态动画;将分词序列输入脸部动画生成模型,生成脸部动画,利用脸部动画替换原子姿态动画中的脸部,生成文本与姿态匹配的二维数字人视频。本发明实现文本与原子姿态动画的匹配,数字人可以根据内置文本实时生成的回复,针对性进行姿态交互,并通过插帧算法实现姿态动画之间的平滑过渡,增强人机交互体验。
技术研发人员:李圣京,李韩,庞文刚,许轲扬,蔡闻哲
受保护的技术使用者:联通沃音乐文化有限公司
技术研发日:
技术公布日:2024/3/21
- 还没有人留言评论。精彩留言会获得点赞!