长文档跨语言摘要生成及模型训练方法、装置及相关设备与流程
本技术涉及跨语言摘要生成,更具体的说,是涉及一种长文档跨语言摘要生成及模型训练方法、装置及相关设备。
背景技术:
1、随着全球化不断加深,不同文化之间的交流日益频繁,世界各地的人们需要访问来自不同语言的文本信息。文档跨语言摘要(cross-lingual summarization)可以快速的帮助人们理解非母语的文本信息,提高人们的工作效率,促进不同文化间的交流。
2、实际应用中存在一类文档,称之为长文档。长文档通常是指那些文字内容较多,篇幅相对较长,文档层次结构相对复杂的文档。长文档通常包含10页以上的文档。例如一本科技图书,一篇正规的商业报告,一份软件使用说明书等都是典型的长文档。近年来,深度学习技术和大语言模型的发展使得跨语言摘要领域取得了巨大进展。然而,训练大语言模型往往对训练数据的需求量十分巨大,而某些领域的长文档跨语言摘要的训练数据十分稀少,这使得基于深度学习的长文档跨语言摘要生成方法难以落地应用。
3、传统的跨语言摘要生成方法通常采用pipeline方法,即让模型分别完成单语摘要和机器翻译。根据完成先后顺序的不同又可以分为先摘要后翻译方法和先翻译后摘要方法。
4、传统的pipeline方法存在着许多弊端,例如误差传播严重、依赖于外部的翻译系统、推理速度慢。为此提出了一种端到端的模型训练方法,直接训练一个跨语言摘要模型,但是端到端训练需要大量的训练数据。而某些领域的长文档对应的跨语言摘要难以获取,收集大规模且高质量的跨语言摘要数据是十分困难的。当模型需要被应用于某一特定领域时,如果训练数据中有关该领域的数据非常稀少,那么模型的效果将难以显现。
技术实现思路
1、鉴于上述问题,提出了本技术以便提供一种长文档跨语言摘要生成及模型训练方法、装置及相关设备,以解决现有端到端模型训练方法需要大量训练数据,而特定领域下长文档对应的跨语言摘要难以获取,导致训练的模型效果较差的问题。具体方案如下:
2、第一方面,提供了一种长文档跨语言摘要模型的训练方法,包括:
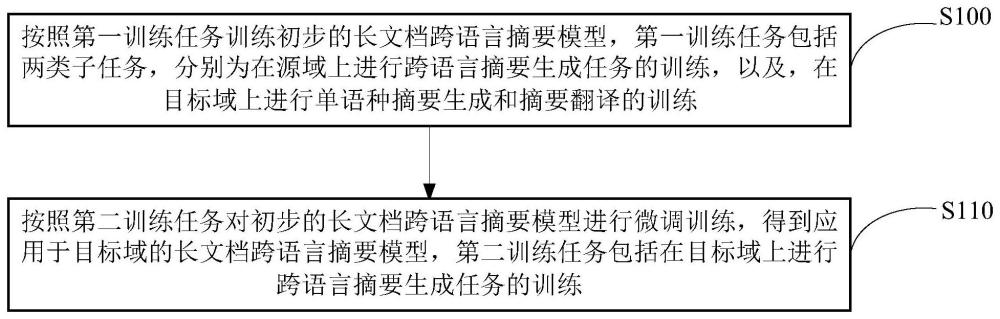
3、按照第一训练任务训练初步的长文档跨语言摘要模型,所述第一训练任务包括两类子任务,分别为在源域上进行跨语言摘要生成任务的训练,以及,在目标域上进行单语种摘要生成和摘要翻译的训练;
4、按照第二训练任务对所述初步的长文档跨语言摘要模型进行微调训练,得到应用于所述目标域的长文档跨语言摘要模型,其中,所述第二训练任务包括在所述目标域上进行跨语言摘要生成任务的训练;
5、所述源域为设定的训练数据量充足的领域,所述目标域为设定的训练数据稀缺的领域。
6、优选地,按照第一训练任务训练初步的长文档跨语言摘要模型的过程,包括:
7、在所述源域和所述目标域上交替地训练长文档跨语言摘要模型,并在交替训练过程按照设定策略调节所述源域上和所述目标域上的训练步数,以平衡两类子任务。
8、优选地,在交替训练过程按照设定策略调节所述源域上和所述目标域上的训练步数的过程,包括:
9、在交替训练过程中,根据交替训练前、后长文档跨语言摘要模型在所述目标域的验证集上计算的困惑度的大小关系,调节后续交替训练过程在所述源域上和所述目标域上的训练步数。
10、优选地,在交替训练过程中,根据交替训练前、后长文档跨语言摘要模型在所述目标域的验证集上计算的困惑度的大小关系,调节后续交替训练过程在所述源域上和所述目标域上的训练步数的过程,包括:
11、在所述源域和所述目标域上迭代多轮训练长文档跨语言摘要模型,每一轮训练过程在所述源域上连续训练λn步,之后在所述目标域上连续训练(1-λ)n步;
12、在每一轮训练过程,在所述源域上连续训练λn步后,在所述目标域的验证集上计算长文档跨语言摘要模型的第一困惑度,在所述目标域上连续训练(1-λ)n步后,在所述目标域的验证集上计算长文档跨语言摘要模型的第二困惑度;
13、计算所述第二困惑度与所述第一困惑度的差值,按照所述差值与λ呈正相关的关系,调整λ的大小,0<λ<1,且当所述差值为0时,λ取值为0.5。
14、优选地,λ的取值范围控制在[0.1,0.9)的范围内。
15、优选地,所述长文档跨语言摘要模型采用由编码器和解码器组成的生成式模型,所述编码器包含注意力层,所述注意力层采用稀疏的自注意力机制。
16、优选地,所述微调训练的过程采用前缀微调的训练方式,包括:
17、提取所述目标域的训练数据中的关键词,作为前缀序列;
18、生成所述前缀序列对应的可学习的嵌入表示,并在按照第二训练任务对初步的长文档跨语言摘要模型进行训练过程,将所述可学习的嵌入表示同时作为编码器和解码器的输入,训练过程更新所述可学习的嵌入表示。
19、第二方面,提供了一种长文档跨语言摘要生成方法,包括:
20、获取目标域下源语言的长文档;
21、将获取的所述长文档输入配置的长文档跨语言摘要模型,得到模型输出的目标语言的摘要;
22、其中,所述长文档跨语言摘要模型为采用前述第一方面中任一项所描述的长文档跨语言摘要模型的训练方法得到。
23、第三方面,提供了一种长文档跨语言摘要模型的训练装置,包括:
24、第一训练单元,用于按照第一训练任务训练初步的长文档跨语言摘要模型,所述第一训练任务包括两类子任务,分别为在源域上进行跨语言摘要生成任务的训练,以及,在目标域上进行单语种摘要生成和摘要翻译的训练;
25、第二训练单元,用于按照第二训练任务对所述初步的长文档跨语言摘要模型进行微调训练,得到应用于所述目标域的长文档跨语言摘要模型,其中,所述第二训练任务包括在所述目标域上进行跨语言摘要生成任务的训练;
26、所述源域为设定的训练数据量充足的领域,所述目标域为设定的训练数据稀缺的领域。
27、第四方面,提供了一种长文档跨语言摘要模型的训练设备,包括:存储器和处理器;
28、所述存储器,用于存储程序;
29、所述处理器,用于执行所述程序,实现本技术前述第一方面中任一项所描述的长文档跨语言摘要模型的训练方法的各个步骤。
30、第五方面,提供了一种存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时,实现本技术前述第一方面中任一项所描述的长文档跨语言摘要模型的训练方法的各个步骤。
31、第六方面,提供了一种计算机程序产品,该计算机程序产品被有形地存储在非瞬态计算机存储介质中并且包括机器可执行指令,该机器可执行指令在由设备执行时实现本技术前述第一方面中任一项所描述的长文档跨语言摘要模型的训练方法的各个步骤。
32、借由上述技术方案,本技术提出了一种基于迁移学习的长文档跨语言摘要模型训练方法,对于模型所要应用于的目标域,在实际场景下该目标域训练数据可能非常稀缺,而一些其他领域下的长文档跨语言摘要对数据可能非常丰富,对于此类领域可以定义为源域,本技术借助迁移学习的思想充分利用源域的丰富训练数据来训练模型。同时,为了保证模型的训练效果,本技术设计了一种独特的训练策略,整个训练过程可以划分为两个阶段,第一阶段按照第一训练任务训练初步的长文档跨语言摘要模型,该第一训练任务包括两类子任务,分别为在源域上进行跨语言摘要生成任务的训练,以及在目标域上进行单语种摘要生成和摘要翻译的训练,通过设计上述第一训练任务,可以使得模型具有初步的跨语言摘要能力,进一步执行第二阶段的训练,在第二阶段按照第二训练任务对前一阶段训练后的长文档跨语言摘要模型进行微调训练,得到最终应用于目标域的长文档跨语言摘要模型。其中,第二训练任务包括在目标域上进行跨语言摘要生成任务的训练,通过设计该第二训练任务,可以增强模型在目标域上端到端的跨语言摘要能力。采用本技术提供的方案,可以解决当目标域长文档跨语言摘要数据稀缺时,模型效果较差的问题,通过迁移学习的方式,以及本技术设计的两阶段的训练任务的组合,可以充分利用源域丰富的训练数据,保证最终训练得到的模型的效果。
- 还没有人留言评论。精彩留言会获得点赞!