一种标准知识库的快速生成方法及系统与流程
本发明涉及知识库生成,特别是一种标准知识库的快速生成方法及系统。
背景技术:
1、在数字电网转型的浪潮中,电力制度标准的不断增加是迈向智能电网的必然步骤,传统电网面临的挑战和需求推动了制定更为细致和全面的标准,以确保数字化转型能够顺利进行,同时满足未来电力系统的复杂需求,标准化变得尤为重要,以确保各个环节都能够按照规定的要求运行,提高电网的可靠性和鲁棒性。新的标准涵盖了从电源发电到电能传输、分配和最终利用的方方面面,以确保整个系统的协调运行,电力制度标准的提高是数字电网转型的必然产物,它不仅为电力系统的安全、稳定运行提供了保障,也促使了更多创新技术的应用和电力服务的优化。
2、传统的知识库和知识检索已无法适应目前制度标准的快速检索查询,当前一般是使用知识图谱描述,将电力领域繁杂的领域知识关联起来,使概念、实体之间的关系更加清晰,但是生成知识库的过程中生成模型在训练时是通过大量的文本数据学习得来的,这意味着它也可能学到了一些不准确、过时或者具有误导性的信息。如果模型在训练数据中接触到了不准确的信息,它可能在生成答案时传递这些错误;此外,生成模型通常是基于表面级别的文本统计模式生成答案,而缺乏深层次的理解。这可能导致模型在处理复杂问题或需要深刻理解语境的情况下产生不准确或者模糊的答案。
技术实现思路
1、鉴于现有的知识检索库存在不准确信息并对已有数据干扰和数据失真的问题,提出了本发明。
2、因此,本发明所要解决的问题在于如何在知识检索时减少数据干扰和数据失真。
3、为解决上述技术问题,本发明提供如下技术方案:
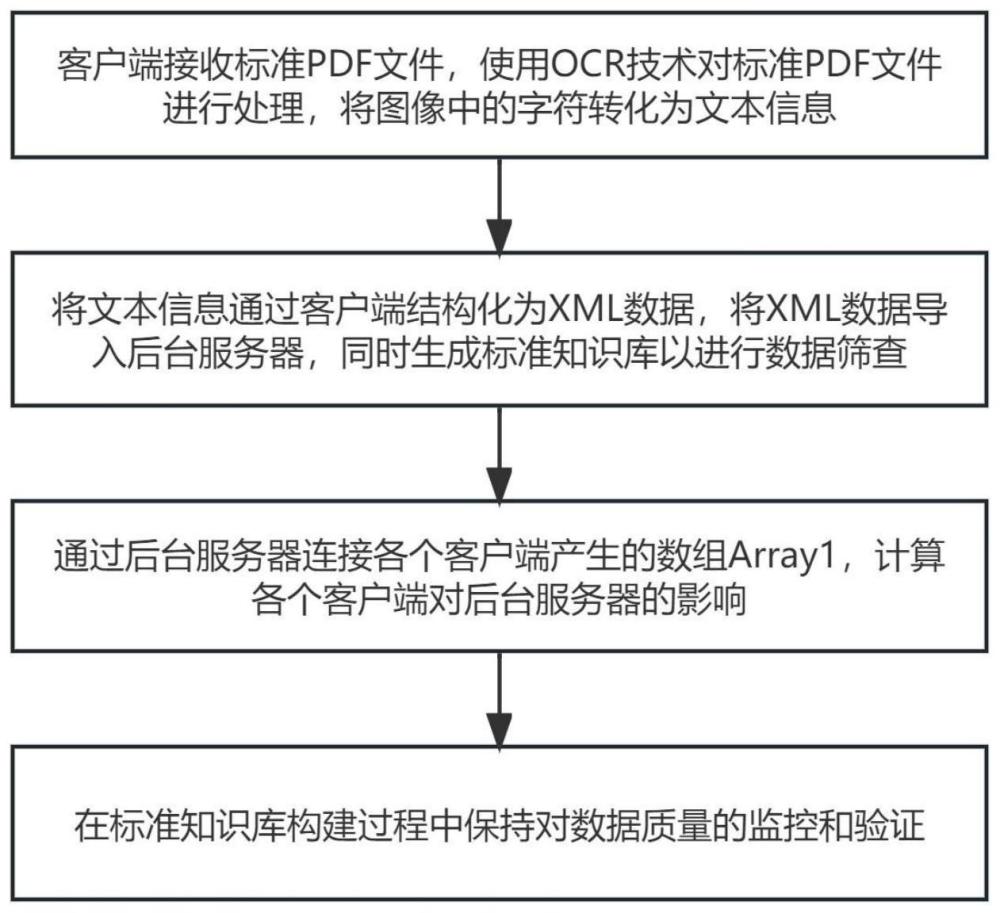
4、第一方面,本发明实施例提供了一种标准知识库的快速生成方法,其包括,通过客户端接收标准pdf文件,使用ocr技术对标准pdf文件进行处理,以将图像中的字符转化为文本信息;将文本信息通过客户端结构化为xml数据,将xml数据导入后台服务器,同时生成标准知识库以进行数据筛查;通过后台服务器连接各个客户端产生的数组array1,计算各个客户端对后台服务器的影响,并在标准知识库构建过程中保持对数据质量的监控和验证,以减小数据失真的风险。
5、作为本发明所述标准知识库的快速生成方法的一种优选方案,其中:所述同时生成标准知识库以进行数据筛查包括以下步骤:将xml数据解析为文本信息,对文本信息进行预处理以获得第一文本;从第一文本中抽取关键信息,并对抽取关键信息进行结构化,以获得结构化文本;将结构化文本构建的数据库作为标准知识库。
6、作为本发明所述标准知识库的快速生成方法的一种优选方案,其中:所述数据库包括关系型数据库、图数据库、文档数据库;所述抽取关键信息包括文本分词、实体抽取和关系抽取;所述预处理包括去除噪声、处理缺失值和标准化格式;所述将xml数据导入后台服务器包括以下步骤:将文本信息通过客户端结构化为xml数据时的时间记为转换时间t1,同时将xml数据传输到后台服务器的时间记为传输时间t2,则将t1到t2的时间段记为导入时段;当xmlse(j,1)≤xmlse(j,m)时,则将从第1次到第m次传输的xml数据中大于xmlse(j,m)的xml数据总数量作为第j个客户端的累积导入量,同时将xml数据对应的传输时刻记为累积导入时刻;当xmlse(j,1)>xmlse(j,m)时,则将从第1次到第m次获取的xml数据中小于xmlse(j,m)的xml数据总数量作为第j个客户端的累积导入量,同时将xml数据对应的导入时刻记为累积导入时刻;其中,xmlse(j,m)为后台服务器连接的第j个客户端在导入时段内第m次传输的xml数据,j为客户端的序号。
7、作为本发明所述标准知识库的快速生成方法的一种优选方案,其中:设置两个空白数组array1和array2;记导入时段内与后台服务器连接各个客户端中累积导入时刻两个时刻之间的所有间隔时长的平均值为t3;若cth时刻在ct~ct+2×t3时间段内,则将ct、ctq和cth对应的累积导入量加入array1中,否则将ct、ctq和cth对应的累积导入量加入array2中;其中,ct为各个xml数据的导入时刻标记时刻,ctq为ct后一个标记时刻,cth为ctq后一个标记时刻。
8、作为本发明所述标准知识库的快速生成方法的一种优选方案,其中:所述数据筛查包括,在r范围中扫描所有array1(r),若
9、array2mean≥array1(r)≥array2min时,且array1(r)<array2min+bdrate×array1max,则将array1(r)在客户端传输xml数据中对应的xml数据剔除;在r范围中扫描所有array1(r),若array2mean<array1(r)<array2max时,且
10、array1(r)≥array1min+bdrate×array2max,则将array1(r)在客户端传输xml数据中对应的xml数据剔除;其中,array1(r)为array1数组中第r个元素,r为序号。
11、作为本发明所述标准知识库的快速生成方法的一种优选方案,其中:数据筛查的相关公式如下:
12、
13、其中,bdrate为数组array1的异常累积导入比,array1mean为array1数组的平均值,array1min为array1数组的最小值,array1max为array1数组的最大值,array2max为array2数组的最大值,array2mean为array2数组的平均值,array2min为array2数组的最小值,函数exp为计算指数。
14、作为本发明所述标准知识库的快速生成方法的一种优选方案,其中:所述标准知识库包括章条库、图片库、表格库、公式库以及术语库;所述将文本信息通过客户端结构化为xml数据通过使用dom解析器或sax解析器进行手动结构化转换。
15、第二方面,本发明实施例提供了一种标准知识库的快速生成系统,其包括:数据接收单元,用于在客户端接收标准pdf文件;预处理单元,用于使用ocr技术对标准pdf文件进行处理,将图像中的字符转化为文本信息;转化传输单元,用于在客户端将文本信息结构化为xml数据,并将xml数据导入后台服务器;知识库生成单元,用于在后台服务器中生成标准知识库。
16、第三方面,本发明实施例提供了一种计算机设备,包括存储器和处理器,所述存储器存储有计算机程序,其中:所述计算机程序指令被处理器执行时实现如本发明第一方面所述的标准知识库的快速生成方法的步骤。
17、第四方面,本发明实施例提供了一种计算机可读存储介质,其上存储有计算机程序,其中:所述计算机程序指令被处理器执行时实现如本发明第一方面所述的标准知识库的快速生成方法的步骤。
18、本发明有益效果为:本发明通过后台服务器连接各个客户端产生的数组array1准确的计算出各个客户端对后台服务器的影响,并对整个知识库构建过程中保持对数据质量的进行监控和验证,有助于最大程度地保留数据的特征,避免对整个知识库进行重新压缩,将数据进行快速筛查,以减少对已有数据的干扰,从而减小数据失真的风险。
- 还没有人留言评论。精彩留言会获得点赞!