一种粤语词组分词处理方法及系统与流程
本发明涉及自然语言处理领域,尤其涉及一种粤语词组分词处理方法及系统。
背景技术:
1、现有针对自然语言处理技术的应用多种多样,但现有的分词技术都是针对普通话进行处理,对于粤语文本无法进行分词。
2、因此,亟需一种粤语词组分词处理策略,从而解决无法对粤语文本进行分词的问题。
技术实现思路
1、本发明实施例提供一种粤语词组分词处理方法及系统,以解决无法对粤语文本进行分词的问题。
2、为了解决上述问题,本发明一实施例提供一种粤语词组分词处理方法,包括:
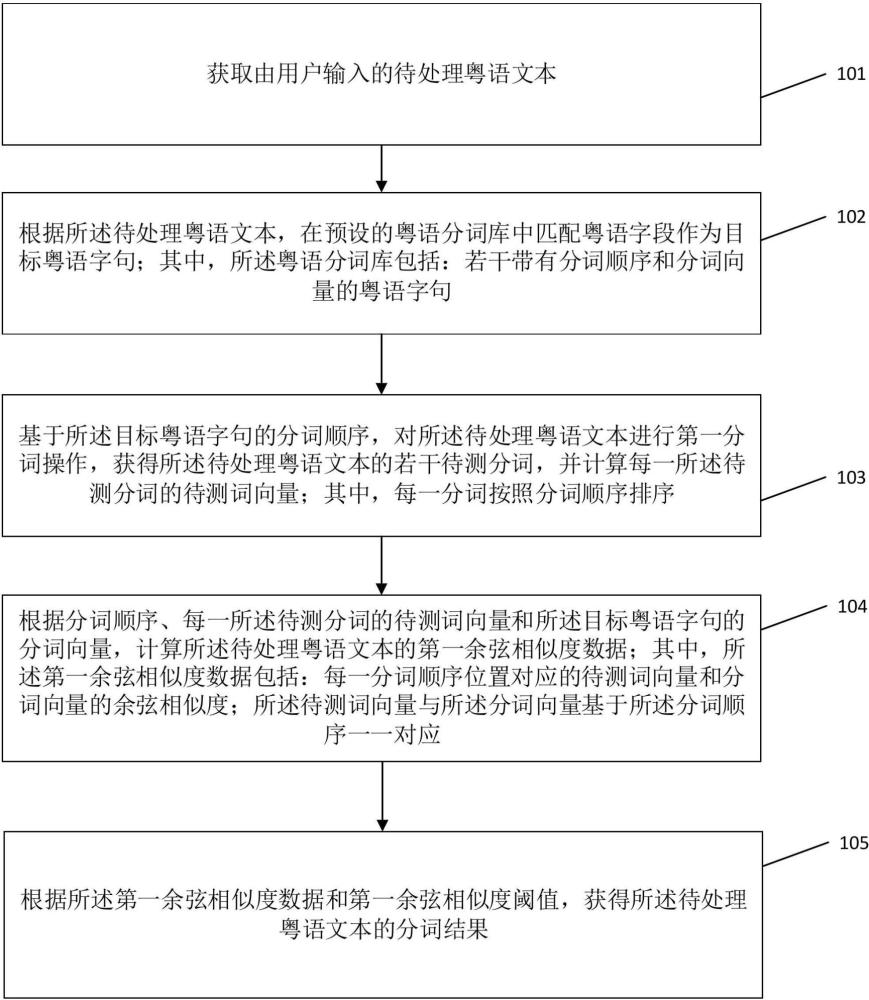
3、获取由用户输入的待处理粤语文本;
4、根据所述待处理粤语文本,在预设的粤语分词库中匹配粤语字段作为目标粤语字句;其中,所述粤语分词库包括:若干带有分词顺序和分词向量的粤语字句;
5、基于所述目标粤语字句的分词顺序,对所述待处理粤语文本进行第一分词操作,获得所述待处理粤语文本的若干待测分词,并计算每一所述待测分词的待测词向量;其中,每一分词按照分词顺序排序;
6、根据分词顺序、每一所述待测分词的待测词向量和所述目标粤语字句的分词向量,计算所述待处理粤语文本的第一余弦相似度数据;其中,所述第一余弦相似度数据包括:每一分词顺序位置对应的待测词向量和分词向量的余弦相似度;所述待测词向量与所述分词向量基于所述分词顺序一一对应;
7、根据所述第一余弦相似度数据和第一余弦相似度阈值,获得所述待处理粤语文本的分词结果。
8、作为上述方案的改进,所述分词结果包括:第一分词结果以及第二分词结果的其中一种或多种;所述根据所述第一余弦相似度数据和第一余弦相似度阈值,确定所述待处理粤语文本的分词结果,包括:
9、对每一分词顺序位置对应的待测词向量和分词向量的余弦相似度与第一余弦相似度阈值进行判断;
10、若当前分词顺序位置对应的余弦相似度大于或等于第一余弦相似度阈值,则确定当前分词顺序对应的待测分词为第一分词结果;
11、若当前分词顺序位置对应的余弦相似度小于第一余弦相似度阈值,则对当前分词顺序对应的待测分词执行第二分词操作,获得第二分词结果。
12、作为上述方案的改进,所述第二分词结果包括:组合分词以及单字分词的其中一种或多种;所述对当前分词顺序对应的待测分词执行第二分词操作,获得第二分词结果,包括:
13、对待测分词的每一字符进行向量计算,获得每一字符对应的向量数据;
14、基于每一向量数据和余弦相似度计算公式,计算第二余弦相似度;其中,所述第二余弦相似度包括:相邻字符之间的余弦相似度;
15、若相邻字符之间的余弦相似度大于或等于第二余弦相似度阈值、且余弦相似度大于或等于第二余弦相似度阈值的相邻字符所组成的分词与粤语词汇数据库中的数据匹配成功,则将相邻字符组合,确定组合分词;其中,所述粤语词汇数据库包括:若干粤语词语;
16、若相邻字符之间的余弦相似度大于或等于第二余弦相似度阈值、且余弦相似度大于或等于第二余弦相似度阈值的相邻字符所组成的分词与粤语词汇数据库中的数据匹配失败,则将相邻字符分开,获得单字分词;
17、若相邻字符之间的余弦相似度小于第二余弦相似度阈值,且字符未与其它字符组合,则将相邻字符分开,获得单字分词。
18、作为上述方案的改进,所述根据所述待处理粤语文本,在预设的粤语分词库中匹配粤语字段作为目标粤语字段,包括:
19、在预设的粤语分词库中,匹配与所述待处理粤语文本的字数相同的粤语字句作为待匹配粤语字句;
20、计算所述待处理粤语文本与所述待匹配粤语字句的相似度,选取相似度大于相似度阈值的待匹配粤语字句作为目标粤语字句。
21、作为上述方案的改进,所述计算所述待处理粤语文本与所述待匹配粤语字句的相似度,包括:
22、计算所述待处理粤语文本的第一向量与所述待匹配粤语字句的第二向量;
23、对所述第一向量和第二向量进行标准化,获得第一标准化向量和第二标准化向量;
24、通过余弦相似度计算公式,计算所述第一标准化向量和第二标准化向量的余弦相似度,获得所述待处理粤语文本与所述待匹配粤语字句的相似度。
25、作为上述方案的改进,所述获取由用户输入的待处理粤语文本,包括:
26、接收用户输入的文本数据;
27、对所述文本数据进行预处理操作,获得待处理粤语文本;其中,所述预处理操作包括:去除标点符号、繁简体转换和大小写转换的其中一种或多种。
28、作为上述方案的改进,在所述确定所述待处理粤语文本的分词结果之后,还包括:
29、将所述待处理粤语文本和所述分词结果对应的分词顺序和分词向量关联,并存储进所述粤语分词库中,以更新所述粤语分词库。
30、相应的,本发明一实施例还提供了一种粤语词组分词处理系统,包括:数据获取模块、数据匹配模块、第一分词模块、数据计算模块和结果生成模块;
31、所述数据获取模块,用于获取由用户输入的待处理粤语文本;
32、所述数据匹配模块,用于根据所述待处理粤语文本,在预设的粤语分词库中匹配粤语字段作为目标粤语待处理粤语文本的字数;其中,所述粤语分词库包括:若干带有分词顺序和分词向量的粤语字句;
33、所述第一分词模块,用于基于所述目标粤语字句的分词顺序,对所述待处理粤语文本进行第一分词操作,获得所述待处理粤语文本的若干待测分词,并计算每一所述待测分词的待测词向量;其中,每一分词按照分词顺序排序;
34、所述数据计算模块,用于根据分词顺序、每一所述待测分词的待测词向量和所述目标粤语字句的分词向量,计算所述待处理粤语文本的第一余弦相似度数据;其中,所述第一余弦相似度数据包括:每一分词顺序位置对应的待测词向量和分词向量的余弦相似度;所述待测词向量与所述分词向量基于所述分词顺序一一对应;
35、所述结果生成模块,用于根据所述第一余弦相似度数据和第一余弦相似度阈值,获得所述待处理粤语文本的分词结果。
36、相应的,本发明一实施例还提供了一种计算机终端设备,包括处理器、存储器以及存储在所述存储器中且被配置为由所述处理器执行的计算机程序,所述处理器执行所述计算机程序时实现如本发明所述的一种粤语词组分词处理方法。
37、相应的,本发明一实施例还提供了一种计算机可读存储介质,所述计算机可读存储介质包括存储的计算机程序,其中,在所述计算机程序运行时控制所述计算机可读存储介质所在设备执行如本发明所述的一种粤语词组分词处理方法。
38、由上可见,本发明具有如下有益效果:
39、本发明提供了一种粤语词组分词处理方法,获取由用户输入的待处理粤语文本;根据所述待处理粤语文本,在预设的粤语分词库中匹配粤语字段作为目标粤语字句;基于所述目标粤语字句的分词顺序,对所述待处理粤语文本进行第一分词操作,获得所述待处理粤语文本的若干待测分词,并计算每一所述待测分词的待测词向量;根据分词顺序、每一所述待测分词的待测词向量和所述目标粤语字句的分词向量,计算所述待处理粤语文本的第一余弦相似度数据;其中,所述第一余弦相似度数据包括:每一分词顺序位置对应的待测词向量和分词向量的余弦相似度;根据所述第一余弦相似度数据和第一余弦相似度阈值,获得所述待处理粤语文本的分词结果。本发明通过完成分词的粤语分词库对待处理粤语文本进行分词,完成了粤语文本的分词;并在分词完成后获得待测词向量,基于待测词向量和粤语分词库预存的分词向量进行余弦相似度的计算,从而有利于后续对余弦相似度和第一余弦相似度阈值进行分词结果的确定,有利于提高粤语分词的精确度。
40、进一步地,本发明在完成粤语文本的分词后,对每个待测分词和分词向量进行余弦相似度进行计算,通过第一余弦相似度的比较,对于小于第一余弦相似度的待测分词执行第二分词操作,对小于第一余弦相似度的待测分词的字符进行余弦相似度的计算,并结合粤语词汇数据,判断待测分词是组合分词或单字分词,完成了待处理粤语文本的二次分词,大大提高了粤语文本分词的分词准确度。
- 还没有人留言评论。精彩留言会获得点赞!