AI服务器及损耗仿真方法与流程
本申请涉及服务器技术,尤其涉及一种ai服务器及损耗仿真方法。
背景技术:
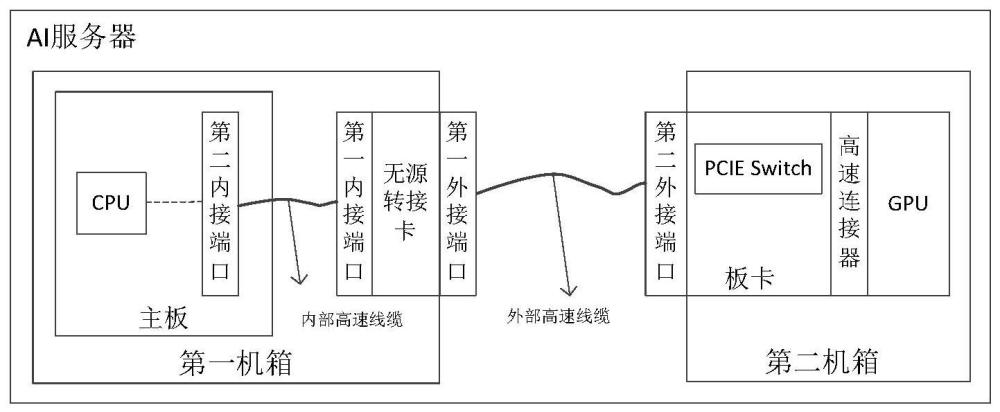
1、随着聊天机器人程序(chat generative pre-trained transformer,chat gpt)的发展,集成了最强大算力显示芯片(graphics processing unit,gpu)模组(h100/h800)的人工智能(artificial intelligence,ai)服务器一时供不应求。常见的,ai服务器主要由两个中央处理器(central processing unit,cpu)通过4个交换芯片pcie switch去调用8个gpu。
2、对于上述ai服务器,gpu与cpu间的高速互联,往往通过加装retimer卡来实现。具体的,retimer卡的内接端口通过内部高速线缆连接装载了cpu的主板,外接端口通过外部高速线缆连接装载了pcie switch的板卡,装载了pcie switch的板卡又与gpu模组连接,从而实现了cpu和gpu的高速互联。
3、在上述高速互联方式中,若要使ai服务器逐渐稳定,需要对retimer卡的均衡参数进行大量的调试,而retimer卡的均衡参数又很难调试,导致有些ai服务器可能需要半年以上的调试才能稳定,从而造成资源浪费。
技术实现思路
1、本申请提供一种ai服务器及损耗仿真方法,用以提供一种高速互联方案,有效节省资源。
2、一方面,本申请提供一种人工智能ai服务器,包括第一机箱和第二机箱,所述第一机箱内设置有装载了中央处理器cpu的主板,所述第二机箱内设置有显示芯片gpu、装载了交换芯片pcie switch的板卡;其中,所述pcie switch用于使所述gpu和所述cpu通信,所述板卡与所述gpu通过高速连接器连接;
3、所述ai服务器还包括位于所述第一机箱内的无源转接卡、内部高速线缆和位于所述第一机箱和所述第二机箱间的外部高速线缆,所述内部高速线缆的一端与所述无源转接卡的第一内接端口连接,另一端与所述主板上的第二内接端口连接;所述外部高速线缆的一端与所述无源转接卡的第一外接端口连接,另一端与所述板卡的第二外接端口连接,使所述cpu和所述gpu互联,且使所述cpu到所述gpu的链路损耗不超规范值。
4、在一种可能实现的方式中,所述第二内接端口与所述cpu通过pcb走线连接,且所述第二内接端口和所述第一内接端口的类型相同。
5、在一种可能实现的方式中,所述第一内接端口和所述第二内接端口均为mcio端口,所述内部高速线缆为mcio-mcio线缆。
6、在一种可能实现的方式中,所述第一外接端口固定在所述第一机箱上与所述第二机箱相对的侧壁,所述第二外接端口固定在所述第二机箱上与所述第二机箱相对的侧壁,且所述第一外接端口和所述第二外接端口的类型相同。
7、在一种可能实现的方式中,所述第一外接端口和所述第二外接端口均为cdfp端口,所述外部高速线缆为cdfp-cdfp线缆。
8、在一种可能实现的方式中,所述无源转接卡中,所述第一内接端口和所述第一外接端口均有至少两个,所述第一内接端口与对应的所述第一外接端口通过八对差分线连接,以适配所述内部高速线缆和所述外部高速线缆。
9、在一种可能实现的方式中,所述差分线的走线长度均不超过预设长度,所述预设长度用于使所述cpu到所述gpu的链路损耗不超所述规范值。
10、在一种可能实现的方式中,所述主板、所述无源转接卡和所述板卡的板材均为第一预设损耗等级的印制电路板pcb,所述第一内接端口、所述第二内接端口、所述第一外接端口和所述第二外接端口的损耗均不超过预设损耗;所述内部高速线缆和所述外部高速线缆均为损耗为第二预设损耗等级的线材;所述第一预设损耗等级、所述预设损耗及所述第二预设损耗等级均用于使所述cpu到所述gpu的链路损耗不超所述规范值。
11、第二方面,本申请提供一种损耗仿真方法,应用于上述第一方面任一项所述的ai服务器,所述方法包括:
12、获取仿真信息,所述仿真信息包括pcb板材等级信息、pcb走线长度信息和线缆长度和线材信息;其中,所述pcb板材等级信息用于指示所述主板、所述无源转接卡和所述板卡的板材损耗等级,所述pcb走线长度用于指示所述主板、所述无源转接卡和所述板卡上关于所述cpu至所述gpu的链路部分的走线长度;
13、基于所述仿真信息进行仿真,得到仿真结果,并基于所述仿真结果确定总损耗;所述仿真结果用于指示所述仿真信息各部分分别对应的损耗。
14、第三方面,本申请提供一种损耗仿真装置,包括:
15、获取模块,用于获取仿真信息,所述仿真信息包括pcb板材等级信息、pcb走线长度信息和线缆长度和线材信息;其中,所述pcb板材等级信息用于指示所述主板、所述无源转接卡和所述板卡的板材损耗等级,所述pcb走线长度用于指示所述主板、所述无源转接卡和所述板卡上关于所述cpu至所述gpu的链路部分的走线长度;
16、仿真模块,用于基于所述仿真信息进行仿真,得到仿真结果,并基于所述仿真结果确定总损耗;所述仿真结果用于指示所述仿真信息各部分分别对应的损耗。
17、第四方面,本申请提供一种电子设备,包括:至少一个处理器和存储器;
18、所述存储器存储计算机执行指令;
19、所述至少一个处理器执行所述存储器存储的计算机执行指令,使得所述至少一个处理器执行如上第二方面所述的方法。
20、第五方面,本申请提供一种计算机可读存储介质,其上存储有计算机程序,该程序被处理器执行时实现如上第二方面所述的方法。
21、本申请提供一种ai服务器及损耗仿真方法,其中,本申请的ai服务器通过无源转接卡代替retimer卡来实现cpu与gpu的高速互联。具体的,无源转接卡的第一内接端口通过内部高速线缆连接cpu所在主板的第二内接端口,第一外接端口通过外部高速线缆连接pcie switch所在板卡的第二外接端口,从而实现cpu与gpu的高速互联。本申请的ai服务器采用前述方案实现cpu与gpu的高速互联,有效避免了均衡参数调试困难的问题。同时,有效节省了制作成本。
技术特征:
1.一种人工智能ai服务器,其特征在于,包括第一机箱和第二机箱,所述第一机箱内设置有装载了中央处理器cpu的主板,所述第二机箱内设置有显示芯片gpu、装载了交换芯片pcie switch的板卡;其中,所述pcie switch用于使所述gpu和所述cpu通信,所述板卡与所述gpu通过高速连接器连接;
2.根据权利要求1所述的ai服务器,其特征在于,所述第二内接端口与所述cpu通过pcb走线连接,且所述第二内接端口和所述第一内接端口的类型相同。
3.根据权利要求2所述的ai服务器,其特征在于,所述第一内接端口和所述第二内接端口均为mcio端口,所述内部高速线缆为mcio-mcio线缆。
4.根据权利要求2所述的ai服务器,其特征在于,所述第一外接端口固定在所述第一机箱上与所述第二机箱相对的侧壁,所述第二外接端口固定在所述第二机箱上与所述第二机箱相对的侧壁,且所述第一外接端口和所述第二外接端口的类型相同。
5.根据权利要求4所述的ai服务器,其特征在于,所述第一外接端口和所述第二外接端口均为cdfp端口,所述外部高速线缆为cdfp-cdfp线缆。
6.根据权利要求5所述的ai服务器,其特征在于,所述无源转接卡中,所述第一内接端口和所述第一外接端口均有至少两个,所述第一内接端口与对应的所述第一外接端口通过八对差分线连接,以适配所述内部高速线缆和所述外部高速线缆。
7.根据权利要求6所述的ai服务器,其特征在于,所述差分线的走线长度均不超过预设长度,所述预设长度用于使所述cpu到所述gpu的链路损耗不超所述规范值。
8.根据权利要求5所述的ai服务器,其特征在于,所述主板、所述无源转接卡和所述板卡的板材均为第一预设损耗等级的印制电路板pcb,所述第一内接端口、所述第二内接端口、所述第一外接端口和所述第二外接端口的损耗均不超过预设损耗;所述内部高速线缆和所述外部高速线缆均为第二预设损耗等级的线材;所述第一预设损耗等级、所述预设损耗及所述第二预设损耗等级均用于使所述cpu到所述gpu的链路损耗不超所述规范值。
9.一种损耗仿真方法,其特征在于,应用于权利要求1-8任一项所述的ai服务器,所述方法包括:
10.一种电子设备,其特征在于,包括:至少一个处理器和存储器;
技术总结
本申请提供一种AI服务器及损耗仿真方法,其中,AI服务器包括第一机箱和第二机箱,第一机箱内设置有装载了中央处理器CPU的主板,第二机箱内设置有显示芯片GPU、装载了交换芯片PCIe Switch的板卡;其中,PCIe Switch用于使GPU和CPU通信,板卡与GPU通过高速连接器连接;AI服务器还包括无源转接卡、内部高速线缆和外部高速线缆,内部高速线缆一端与无源转接卡的第一内接端口连接,另一端与主板上的第二内接端口连接;外部高速线缆一端与无源转接卡的第一外接端口连接,另一端与板卡的第二外接端口连接,使CPU到GPU的链路损耗不超规范值。本申请的AI服务器,具备成本低、易调试的优势。
技术研发人员:罗世飘
受保护的技术使用者:西安易朴通讯技术有限公司
技术研发日:
技术公布日:2024/3/27
- 还没有人留言评论。精彩留言会获得点赞!