基于MCC加权的最小二乘支持向量回归异常检测方法
本发明属于时序数据异常检测领域,具体涉及一种基于mcc加权的最小二乘支持向量回归异常检测方法。
背景技术:
1、由于核电厂发生严重事故会导致不可估量的后果和持续的影响,因而核电厂相较于普通电厂对于运行安全有着更高的优先级和敏感度。核电机组运行状态实时监测是确保核电厂安全运行的关键措施。通过分析设备传感器记录的大量历史运行时序数据,可以建立有效的异常检测模型,及时发现异常事件的产生,以减少因故障造成的损失。
2、数据驱动方法主要利用机组运行过程中产生的海量历史数据,分析数据之间的潜在关系,建立能够近似逼近真实情况的数学模型,以此监测机组运行的状态,最终达到异常检测的目的。基于数据驱动的方法分为统计分析方法和人工智能方法,其中基于统计分析方法的有:主成分分析法(principal component analysis,pca)、偏最小二乘法(partialleast squares,pls)、费舍尔判别分析法(fisher discriminant analysis,fda)等。基于人工智能方法的有:随机森林(random forest,rf)、支持向量机(support vectormachine,svm)、朴素贝叶斯方法等。这些方法除了需要大量数据之外,还要求所选数据具有代表性的特征以及较高的质量,但工业数据经常会受到环境因素和人为因素的影响,因此基于统计分析的方法只能应用到一些特定的场景。
3、相较于统计分析方法,基于人工智能的方法能够自动从数据中自动学习数据表征,而不需要人工设计或者手动提取数据特征。同时,人工智能方法还可以利用分布式计算和并行处理技术,来提高数据的处理效率和模型泛化的能力。但是统计分析方法和人工智能方法对数据质量都有着较高的要求,当训练数据中包含异常数据时,模型学习的数据特征中就会包含一些错误的特征,导致最终模型的预测结果与真实情况存在一定量的偏差。在核电厂记录的历史数据中,由于数据之间的关系比较复杂以及数据量十分巨大,不可避免地会出现一些异常数据,完全依靠人工去除异常数据十分费时费力,这也导致了上述的一些方法不能够很好的适应核电数据。
4、核电厂记录的不同设备的时序数据,往往会因为外部因素导致数据中存在一些异常值,而这些异常值没有明确的位置标签。常见的利用回归预测检测异常数据的方法往往需要利用正常数据训练,当训练集中包含异常值时,模型的精准率就会受到异常值的影响,降低模型异常检测的能力。
技术实现思路
1、为解决上述技术问题,本发明提供一种基于最大相关熵准则(maximumcorrentropy criterion,mcc)加权的最小二乘支持向量回归(least squares supportvector regression,lssvr)异常检测方法,用于预测核电厂中某一设备的相关变量,实现对该变量的异常检测。该方法对训练集进行循环迭代加权,以此降低异常值在整个训练集中的权重,提高模型的鲁棒性,能够更加精准的预测,同时可以提高异常检测的精度。
2、本发明采取的技术方案为:
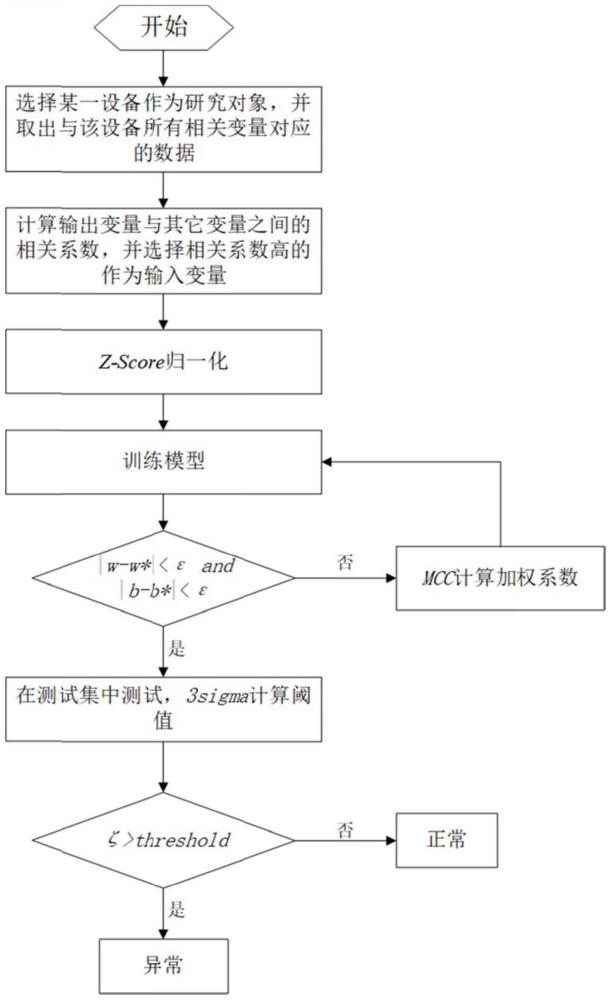
3、基于mcc加权的最小二乘支持向量回归异常检测方法,包括以下步骤:
4、步骤1:选择某一设备作为研究对象,选择与该设备相关变量的历史运行数据作为mcc-lssvr模型的数据集;
5、步骤2:计算输出变量与其它变量之间的相关系数,选择相关系数大于一个固定值的变量及其对应的数据作为mcc-lssvr模型的输入数据;
6、步骤3:采用z-score方法对步骤2中的输入数据进行归一化处理;
7、步骤4:利用训练集迭代训练mcc-lssvr模型;
8、步骤5:利用训练得到的mcc-lssvr模型在测试集上验证,利用3sigma原则计算阈值,通过预测值和真实值之间的残差是否大于该阈值来判断测试集中数据是否出现异常;
9、步骤6:计算mcc-lssvr模型的mae和mape指标。
10、所述步骤2中,输出变量为某一设备中的一个具体变量,其它变量为除去输出变量之外的所有与该设备有关的变量;相关系数采用皮尔逊系数,其计算公式如下:
11、
12、其中:x、y分别表示任意两个向量;cov(x,y)、e[(x-ex)(y-ey)]均表示两个变量之间的协方差;σx,σy分别为x、y的标准差;ex,ey分别表示x、y的期望值。
13、所述步骤3中,数据归一化是为了将不同量纲的变量统一在一个范围之内,z-score公式如下所示:
14、
15、其中:为x的均值,σx为x的标准差。
16、所述步骤4中,最小二乘支持向量回归lssvr定义为如下形式:
17、y=wx+b (3);
18、其中:w为权重矩阵,b为偏置量;lssvr通过解决下述最优化问题得到最优的w和b:
19、
20、s.t.yi=wxi+b+ξi,i=1,2,…,n (5);
21、其中:ξ表示预测值和真实值的误差向量;ξi表示ξ中的第i个误差值;c为一个常量;n表示总的样本数;xi表示第i个输入向量;yi表示第i个输出值。
22、通过拉格朗日乘子法,能够将上述最优化问题变成:
23、
24、其中:α表示一个拉格朗日乘子向量;αi为α中的第i个拉格朗日乘子;yi为第i个真实值。
25、根据karush-kuhn-tucker条件,能够将公式(6)转化为线性方程组的形式:
26、
27、其中:i是单位向量;1v为全1的列向量;表示全为1的行向量;y表示真实值向量;q表示核函数矩阵;
28、所述步骤4中,迭代训练的过程包括以下步骤:
29、步骤4.1:初始化变量c,σ,λ,ε;
30、步骤4.2:根据公式(7)计算w,b;
31、步骤4.3:根据公式(3)计算y,并计算误差ξi;
32、步骤4.4:计算vi,w*,b*,vi为表示第i个输入向量的权重;w*表示上一轮迭代的权重矩阵;b*表示上一轮迭代的偏置量。
33、如果|w-w*|和|b-b*|都小于ε,则终止迭代;否则跳回步骤4.3继续迭代。
34、所述步骤4.4中,mcc-lssvr模型使用mcc作为样本的权重系数,mcc公式如下:
35、
36、其中:ξ为真实值与预测值之间的误差;σ为高斯核函数的频带宽度。由公式(8)能够计算:
37、vi=λ(1-mcci) (9);
38、其中:λ表示缩放常数;mcci第i个误差值的mcc函数值。
39、w*,b*能够由下述公式计算:
40、
41、其中:v是由vi组成的对角矩阵。
42、所述步骤5中,判断测试集中数据是否异常的步骤如下:
43、步骤5.1:利用训练得到的模型对测试集进行预测;
44、步骤5.2:计算预测值与真实值之间的误差,计算公式如(12)所示;
45、ξ=y-y (12)
46、其中,ξ表示误差向量,y表示真实值向量,y表示预测值向量。
47、步骤5.3:利用3sigma原则计算误差的阈值,误差大于阈值的认为是异常,公式如下所示:
48、
49、
50、其中:|·|表示绝对值,表示误差的均值,σξ表示误差的标准差;ξi表示误差向量ξ中的第i个值;threshold表示用于判断是否异常的阈值,r表示第i个输入向量和真实值是否出现异常,1表示异常,0表示正常。
51、所述步骤6中,mae和mape的计算公式如下:
52、
53、
54、其中:mae(y,y)表示真实值和预测值之间的mae值;mape(y,y)表示真实值和预测值之间的mape值;yi表示第i个真实值;yi表示第i个预测值;n表示总的样本数。
55、本发明一种基于mcc加权的最小二乘支持向量回归异常检测方法,技术效果如下:
56、1)本发明采用mcc加权的方法,降低训练集中异常数据对模型的影响。
57、2)本发明相较于mse加权的模型,有着更低的mae和mape指标值,从而反映出基于mcc加权的模型异常检测准确率更高。
58、3)本发明可以降低对数据集的要求,容许数据中包含一部分异常数据,从而降低制作完全正常的数据所需的劳动力。
59、4)本发明本发明提供了一种基于mmc加权的最小二乘法支持向量回归异常检测方法。最小二乘法支持向量回归方法在求解过程中采用了线性规划技术,降低了时间复杂度,特别适用于大规模数据。相较于普通的加权方法,mcc具有更强的鲁棒性,能够有效地抑制异常数据的干扰,从而提高最小二乘法支持向量回归的鲁棒性,使其能够更好地适应含有异常数据的样本。
- 还没有人留言评论。精彩留言会获得点赞!