一种面向流式数据复杂场景的动态集成分类方法与流程
本发明涉及在线学习,具体涉及一种面向流式数据复杂场景的动态集成分类方法。
背景技术:
1、流式数据广泛产生于电子商务、工业生产、社交媒体等领域。在不失一般性的情况下,其分布可能会随着时间的推移而变化,称为概念漂移。在这种情况下,根据历史数据创建的分类器可能无法识别新概念,从而导致错误分类。此外,属于各种类别的数据量可能是偏斜的,从而形成不平衡的数据流。传统的分类方法通常偏向于多数类,导致泛化能力差。因此,用概念漂移对不平衡流数据进行分类是数据流挖掘的一个具有挑战性的问题。
2、为了解决概念漂移问题,人们对适应一个新概念进行了丰富的研究,可以分为主动和被动方法。它们之间的主要区别在于是否检测到漂移点。主动方法通过监测模型性能的平稳性来判断新概念是否出现,然后在出现漂移时触发自适应过程。通常,检测漂移取决于人类预先设置的分类精度阈值。不适当的阈值可能会导致漂移的程度和时间的不正确重新定域,甚至导致概念漂移的误报。与它们不同的是,被动方法通过不断更新分类器来适应具有漂移概念的数据,而无需明确的漂移检测。
3、数据流的另一个具有挑战性的问题是类不平衡,其中一个类的实例数量远远多于其他类。一般来说,前者被称为多数阶级,而另一种则是少数阶级。偏斜的数据可能导致基础分类器在少数类上的泛化能力差,以及集成结构不合适。为了解决这个问题,许多研究都致力于将过采样技术引入集成模型。过采样新生成的少数实例的质量直接影响分类精度和学习效率。
技术实现思路
1、为解决上述技术问题,本发明提供一种面向流式数据复杂场景的动态集成分类方法。
2、为解决上述技术问题,本发明采用如下技术方案:
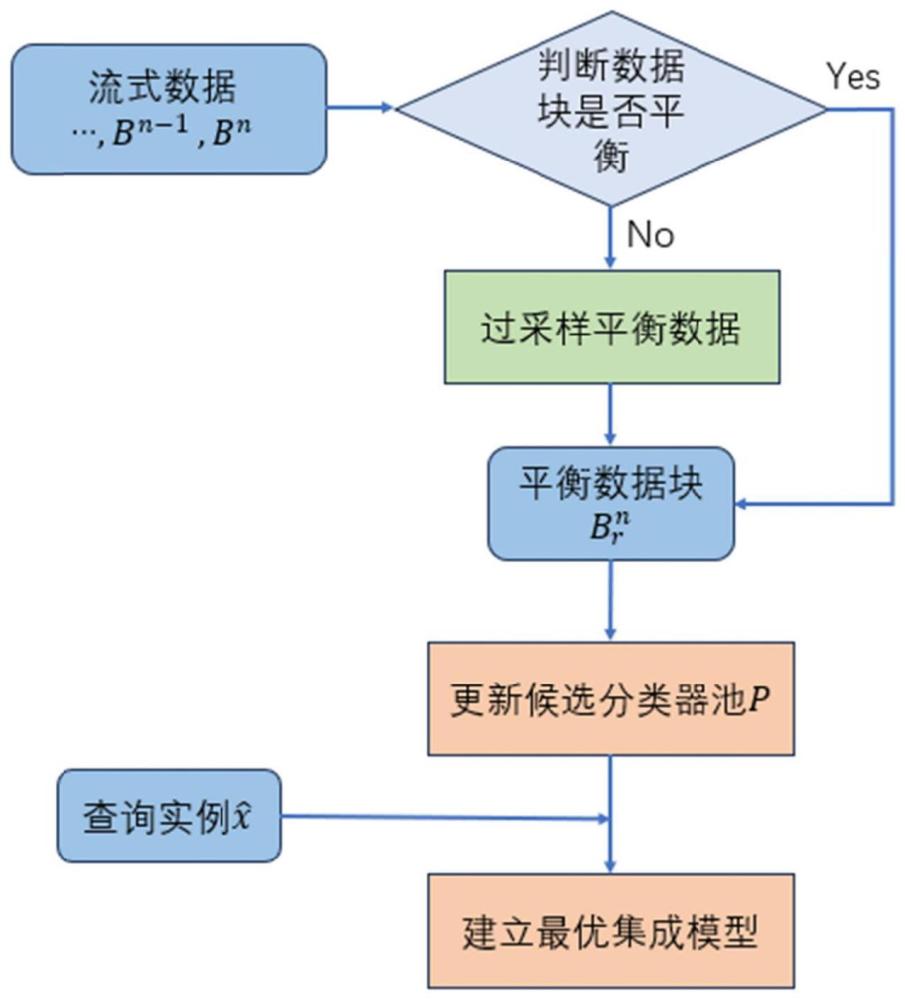
3、一种面向流式数据复杂场景的动态集成分类方法,包括以下步骤:
4、步骤一:通过循环缓存数组连续捕获实例,将流式数据转换为一系列的数据块;
5、步骤二:对每个数据块的实例数量进行统计,判断数据块是否平衡;通过过采样技术对每个不平衡的数据块进行处理,将原本平衡的数据块,以及过采样处理后得到的平衡的数据块组成训练数据;
6、步骤三:根据训练数据生成候选分类器池;
7、步骤四:根据改进的选择策略为每个查询实例建立最优的集成分类模型,并输出查询实例的分类结果。
8、进一步地,步骤一具体包括:所述流式数据s为无限数据流,使用循环缓存数组捕获来自流式数据s的每个新到达的实例;循环数组存满后,将循环数组内的数据形成数据块,然后清空循环数组以缓存后续的实例。
9、进一步地,步骤二具体包括:
10、s21:对于每个新的数据块,统计数据块中不同类的实例数量,以判断数据块是否平衡;在不平衡的数据块中,实例数量最多的类中的实例称为多数实例,其他类中的实例称为少数实例;
11、s22:记bn是第n个不平衡的数据块,bn中的第i个少数实例记为是用于重新采样的相邻少数实例的数目;对于选择在bn-1中的k1个最近相邻少数实例来构成一个子集bn-1中围绕的子区域的密度被定义为中与的相邻少数实例之间的平均距离
12、
13、k1是一个预定义的邻居参数,用于控制周围子区域的大小;||·||表示欧几里得距离,是中的第j个实例;
14、bn中的与的k个最近相邻少数实例之间的平均距离为:来计算,其中是bn中的第j个少数实例;设k=k1,并且将周围的子区域中的两个相邻数据块的分布变化定义为
15、根据的值,分布变化分为以下三种类型:
16、
17、由密度变化的严重程度决定:
18、
19、表示中少数实例的数量,是bn中的k2最近邻居的子集;
20、s23:如果是一个有噪声或无价值的实例,则能够通过来识别:
21、如果中的实例都属于多数类,则在这种情况下,是噪声样本或者无价值样本,并且即,没有用于重新采样的邻居;此外,k2是的最大值,k2大于k1;
22、s24:设置一个空集合g,将中前个相邻少数实例和结成数据对并加入到集合g中;
23、s25:重复步骤s22、s23、s24,直至遍历完bn中的所有少数实例
24、s26:在集合g中随机选择数据对通过在由及随机选择的的相邻少数实例组成的数据对之间进行插值,生成一个新的少数实例:
25、
26、其中,λ~u[0,1]是一个随机数;
27、将生成的新的少数实例加入到bn中,重复步骤s26直至bn中的少数实例与多数实例达到平衡,得到新的平衡数据块
28、进一步地,步骤三具体包括以下步骤:
29、s31:设置候选分类器池,pm为最新的候选分类器池,pm-1为更新前的候选分类器池;
30、s32:基于原本的平衡数据块和新的平衡数据块使用任何一种在线分类算法对pm-1中的所有基础分类器ci进行更新;
31、s33:基于最新的平衡数据块使用任何一种在线分类算法建立一个新的基础分类器cn,并将新的基础分类器cn与步骤s32中所有更新后的基础分类器ci合并,形成最新的候选分类器池pm;如果合并后的候选分类池大小超过设置的容量阈值m,则逐个舍弃最旧的基础分类器,直至pm符合容量要求。
32、进一步地,步骤四具体包括:
33、给定查询实例将从最新的数据块中选择的、与实例最近的k3个邻居构成集合判断中的实例是否都属于同一类,如是,则从pm中提取在中具有最高分类器精度的基本分类器,构建的集成分类模型如否,则把具有最高召回值的基本分类器组成集成分类模型通过多数投票获得查询实例的最终分类结果
34、
35、其中k3为设定的邻居数量,y是类标签,是由基础学习器ci给出的类y的分类概率。
36、与现有技术相比,本发明的有益技术效果是:
37、本发明提出的利用概念漂移对不平衡数据流进行分类的动态集成分类方法,是一种基于块的方法;也就是说,流中的实例是逐块处理的。对于每个数据块,提出了一种改进的合成少数类过采样技术(smote),以产生新的少数实例,其中少数实例的邻居数量取决于前一数据块的分布变化程度,称之为具有自适应近邻的smote(annsmote)。基于重采样后的数据块,构建了一个新的基础分类器,并将其与历史分类器相集成,形成候选分类器池。然后,设计了一种选择策略,为每个查询实例寻找最合适的组合。此外,由于内存有限,候选分类器池的大小必须受到限制。因此,当池中的基分类器的数量大于其最大值时,丢弃最旧的基分类器。本发明可以解决流式数据的不平衡问题,提高了分类预测的准确性。
技术特征:
1.一种面向流式数据复杂场景的动态集成分类方法,包括以下步骤:
2.根据权利要求1所述的面向流式数据复杂场景的动态集成分类方法,其特征在于,步骤一具体包括:所述流式数据s为无限数据流,使用循环缓存数组捕获来自流式数据s的每个新到达的实例;循环数组存满后,将循环数组内的数据形成数据块,然后清空循环数组以缓存后续的实例。
3.根据权利要求1所述的面向流式数据复杂场景的动态集成分类方法,其特征在于,步骤二具体包括:
4.根据权利要求1所述的面向流式数据复杂场景的动态集成分类方法,其特征在于,步骤三具体包括以下步骤:
5.根据权利要求1所述的面向流式数据复杂场景的动态集成分类方法,其特征在于,步骤四具体包括:
技术总结
本发明涉及在线学习技术领域,公开了涉及一种面向流式数据复杂场景的动态集成分类方法,包括以下步骤:通过循环缓存数组连续捕获实例,将流式数据转换为一系列的数据块;对每个数据块的实例数量进行统计,判断数据块是否平衡;通过过采样技术对每个不平衡的数据块进行处理,将原本平衡的数据块,以及过采样处理后得到的平衡的数据块组成训练数据;根据训练数据生成候选分类器池;根据改进的选择策略为每个查询实例建立最优的集成分类模型,并输出查询实例的分类结果。本发明可以解决流式数据的不平衡问题,提高了分类预测的准确性。
技术研发人员:许镇义,李家仁,康宇,曹洋,刘斌琨
受保护的技术使用者:合肥综合性国家科学中心人工智能研究院(安徽省人工智能实验室)
技术研发日:
技术公布日:2024/3/24
- 还没有人留言评论。精彩留言会获得点赞!