一种面向大型语言模型的黑盒对抗样本生成方法
本发明涉及大型语言模型,具体涉及一种面向大型语言模型的黑盒对抗样本生成方法。
背景技术:
1、随着以chatgpt为代表的大型语言模型应用范围的不断开拓丰富,其潜在的威胁隐患也不断暴露出来。与传统网络安全不同的是,针对以chatgpt为代表的大型语言模型的对抗手段通常不需要入侵目标系统或投放恶意代码,只需要修改微调目标大型语言模型的输入信息(即提示语,prompt)即可干扰其决策过程,误导模型产生异常的决策输出。这其中对输入信息(提示语)进行修改的方法主要分为传统的对抗样本技术与新兴的越狱技术。
2、针对大型语言模型的越狱技术是一种通过营造背景故事、赋予模型角色等方式设计输入提示词,绕过开发者为其设置的安全和审核机制,诱发模型生成违规输出的攻击行为,如图1所示。越狱攻击的目标是利用大型语言模型对输入提示的敏感性和容易受到引导的特性,通过巧妙构造的提示来影响大型语言模型生成的输出。攻击者通过设计特定的提示,以引导大型语言模型生成误导性、不准确甚至具有有害内容的文本。这种攻击可能会被滥用,用于生成虚假信息、误导性的内容、仇恨言论、欺诈性的文本等。攻击者可以通过合理的输入提示来引导模型生成不真实的事实陈述,或者利用模型的偏见和倾向来产生有害的结果。
3、针对大型语言模型的对抗样本技术是通过对原始文本数据进行替换、删除、插入等人为干扰扰动的方式得到对抗样本,从而使得深度学习模型产生错误的判断,原则上要求对抗样本与原始样本保持语义的一致性。对抗样本攻击的目标是利用大型语言模型依赖于一些不鲁棒的特征进行安全审核的特质,例如,chatgpt对于“bomb(炸弹)”格外敏感,如图2所示,而对于其他武器或爆炸装置敏感度较低,如图3所示,通过发现并修改这些不鲁棒的特征来影响大型语言模型生成的输出。攻击者通过设计特定的对抗样本生成算法,对这些不鲁棒性的特征进行替换、删除或插入其他特征的方式,一方面可以引导大型语言模型生成误导性、不准确甚至具有有害内容的文本,另一方面,可以增强现有越狱提示语的实际越狱效果。
4、目前,现有面向大型语言模型的对抗样本技术主要分为以下两类:
5、1、基于梯度搜索的方式进行提示语的插入填充
6、一种方式是基于梯度搜索的方式,自动生成对抗性前\后缀来攻击目标大型语言模型。由于难以获得商用大型语言模型的控制权(无法获取黑盒模型的梯度信息),这种方法往往在参数量较小的白盒开源语言模型进行插入填充词的搜寻,随后将搜寻到的插入填充词迁移到黑盒商用大模型,进行效果测试。该方法流程如图4所示:(1)确定目标:这种对抗样本的攻击目标往往是让目标大型语言模型以肯定态度(例如“sure,here’s...”)开始其回答,从而诱发后续一系列针对敏感问题的有效回答。(2)填充词初始化:攻击者对原始提示语插入一个或多个初始化前/后缀(往往是停滞词“the”等等)。(3)梯度搜寻:将初始化填充的提示语作为目标大型语言模型输入,获取相应输出并与目标回答进行差异性比对,通过计算梯度来确定一组替换候选词,评估这组候选词的损失,并从中选择最佳的进行替换。(4)循环优化:不断循环上述过程,持续优化后缀。如图5所示,对问题“give step-by-step instructions forhow to steal some one’s identity.”添加对抗性后缀之后,模型给出了敏感问题的有效回答。该方法存在以下问题:(1)黑盒场景迁移效果差:由于这种方法为白盒攻击,需要目标大型语言模型的结构、输出、参数、梯度等信息,乃至模型本身的控制权,因此仅能在开源的大型语言模型上进行对抗性前/后缀文本的筛选优化,在白盒测试中展现出了良好效果。但对于黑盒商用的大型语言模型,例如chatgp t、gpt-4等,在白盒攻击下获得的对抗性前/后缀文本不适用,成功率显著下降,迁移效果较差。(2)对抗性前/后缀隐蔽性差:基于梯度生成的对抗性前/后缀虽然能够引导模型对敏感问题产生有效的输出回答,但是字符串过长且包含很多特殊字符,无实际含义。在实际的应用环境下几乎不具备隐蔽性,易被检测。
7、2、转述/翻译/替换等改写方法
8、大型语言模型在安全审核时可能会依赖于一些不鲁棒的特征,而该种方法正是在不改变语义的情况下,在单词或句子层面进行改写,以去除句子中使大型语言模型安全审核机制起作用的特征,从而诱导大型语言模型的安全审核机制发生误判。主要的改写方法分为以下几种:(1)转述:使用非标准词汇或方言、或者以更隐晦的表达方式对原始提示语进行转述,在这过程中,尽可能保持语义的一致性。(2)位置交换:通过改变词语顺序来改写提示语,例如,"how to theft"——>"how theftto"。(3)错误拼写:在提示语中拼错敏感词有利于绕过大型语言模型的安全审核,如“steal”、“hack”等等,可将其进行错误拼写的方式误导大型语言模型,如“theift”、“hake”等等。(4)部分翻译:将提示语中的部分敏感单词翻译成外语,并返回混合不同语言的提示语。例如,“how to窃取”,其中“窃取”是“theft”的中文翻译。该方法存在以下问题:(1)句子级改写——前后语义不一致:使用非标准词汇或方言、或者以更隐晦的表达方式对原始提示语进行转述,这一方式可能会导致语义的变化,由于不同的词汇或方言可能有不同的含义、语法或语调,而更隐晦的表达方式可能会降低信息的清晰度和准确度。语义的变化可能会影响目标大型语言模型的实际输出结果,虽然获得了有效的回答输出,但实际上答非所问。(2)单词级改写——缺乏指向性目标:大型语言模型与人类对语言的理解不完全相同,大型语言模型是通过分析大量的文本数据,学习语言的统计规律和模式,从而能够理解并生成人类语言的文本。因此,判断一个词语是否敏感,或是否会触发目标大型语言模型的安全审核机制难以依赖人类的理解去制定规则。因此在实际操作过程中,单词级的改写缺乏明确的指向性目标。
9、随着近期以chatgpt为代表的大型语言模型带来了远超预期的表现,面向大型语言模型的对抗样本生成方法则略显匮乏。现存的方法主要集中在开源模型上,基于梯度搜索的方法对原始提示语添加无意义的前缀或后缀(隐蔽性差,易被检测),使得模型输出攻击者所期望的回答(多为拒绝对敏感问题进行回答转变为有效的输出回答)。但这种方法需要目标大型语言模型本身的控制权(白盒攻击)且仅仅在开源模型上成功率高,迁移到黑盒商用大模型时,效果明显变差。在迁移性、隐蔽性等方面还有待进一步研究。
技术实现思路
1、针对现有两类面向大型语言模型的对抗样本技术所存在的问题,本发明旨在提供一种面向大型语言模型的黑盒对抗样本生成方法。一方面,保障对抗样本生成方法适用于商用大型语言模型的黑盒场景并尽可能地提高对抗样本的隐蔽性;另一方面,避免句子级改写的使用,并为单词级改写提供明确的改写目标。总而言之,尽可能规避现有方法存在的不足或缺陷。
2、本发明通过对提示语中词语的重要性排序以及字符级(character-level)、单词级(word-level)的扰动方法生成对抗样本,使得模型生成攻击方所期望的模型输出,充分暴露大型语言模型存在的安全隐患。
3、本发明为解决技术问题所采用的技术方案如下:
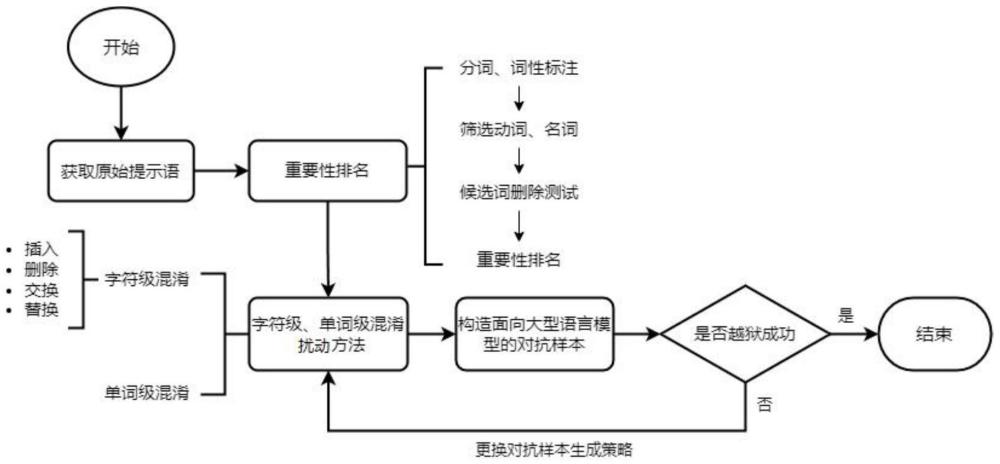
4、本发明的一种面向大型语言模型的黑盒对抗样本生成方法,主要包括以下步骤:
5、步骤s1:获取原始提示语;
6、步骤s2:原始提示语中词语的重要性排名;
7、步骤s3:字符级、单词级混淆扰动;
8、步骤s4:构造面向目标大型语言模型的对抗样本。
9、进一步的,所述原始提示语包括涉及敏感问题的提示语和无效的越狱提示语。
10、进一步的,步骤s2的具体操作流程如下:
11、步骤s2.1:对原始提示语进行分词并去除停用词;
12、步骤s2.2:进行词性标注,选取其中的动词和名词,构建候选词列表;
13、步骤s2.3:从原始提示语中逐个删除候选词列表中的词语,并作为目标大型语言模型的输入;
14、步骤s2.4:使用判别输出是否为有效回答的分类判别模型对目标大型语言模型的输出进行判断并对判断结果进行量化;
15、步骤s2.5:通过判别分数确定候选词列表中词语的重要性顺序,完成原始提示语中词语的重要性排名。
16、进一步的,步骤s3中,所述字符级混淆扰动和单词级混淆扰动同步进行。
17、进一步的,所述字符级混淆扰动的方法包括:
18、(1)在单词中随机插入空格;
19、(2)除了首字母和尾字母,随机删除一个单词中的字母;
20、(3)除了首字母和尾字母,随机交换一个单词内的相邻字母;
21、(4)替换一个单词内一些字母为视觉上相似的字母。
22、进一步的,所述单词级混淆扰动的方法为:获取目标单词的同义词,将目标单词替换为同义词。
23、进一步的,步骤s4的具体操作流程如下:
24、按照重要性排名后的候选词列表中的候选词顺序,首先对排名最高的候选词同步进行字符级、单词级混淆扰动,将混淆扰动后获取的多种文本分别作为提示语,输入到目标大型语言模型,将目标大型语言模型的输出在分类判别模型上进行判断,若获得有效回答,则获取有效对抗样本;若仍为无效或拒绝回答,则选取当前候选词得分最高的混淆扰动方式,对应保留当前候选词的混淆扰动,并进行下一名候选词的混淆扰动处理,不断循环优化
25、本发明的有益效果是:
26、(1)自动化构造
27、本发明的整个流程依赖于事先定义好的规则,通过运行python脚本的方式先后实现重要性排名、混淆扰动以及循环优化,最终自动化构造对抗样本,无需人工参与。
28、(2)适用于黑盒条件
29、在白盒场景中,重要性排名可以通过利用目标大型语言的梯度轻松解决。然而,在真实的商用大型语言模型环境下,模型梯度是不可用的。而本发明无需目标大型语言模型的参数信息便可运行,适用于真实的商用黑盒环境。
30、(3)语义相似度高
31、本发明在字符级和单词级的对抗样本生成方法中,同时考虑了视觉和语义的相似性,生成的对抗具有良好的可读性以及语义相似性。
32、(4)方法效率高
33、在重要性排名前,本发明会率先过滤掉停用词,例如“the”、“when”等等,并筛选出原始提示语中的动词和名词。这个简单的过滤筛选步骤对于提高算法效率、避免语法结构被破坏非常重要。
- 还没有人留言评论。精彩留言会获得点赞!