一种基于背景语义信息增强的场景文本识别方法和装置
本发明涉及一种基于背景语义信息增强的场景文本识别方法和装置,特别针对遮挡或者模糊的文本。由于遮挡或模糊可能导致部分文本特征丢失,因此有效识别这类文本变得困难。本发明通过引入文本所在的背景信息,以指导当前单词的推理。本发明涉及深度学习的计算机视觉和自然语言处理领域,还涉及视觉和语言的跨模态领域。
背景技术:
1、场景文本识别(str)是一项广泛应用的技术,主要用于从自然图片中识别文字,包括街道标志识别,门店标志牌识别、以及自动文本翻译等。场景文本识别的两个主要阶段是场景文本检测分支和场景文本识别分支,本发明主要涉及文本识别分支。与光学字符识别(ocr)不同,ocr专注于文档,其中文字统一而整齐。相反,str关注自然场景中的文本,例如街道标志牌和商铺店名,因此具有更大的挑战性。
2、一般来说,场景文本识别(str)任务和相应的数据集可以分为两类:规则文本和不规则文本。规则文本通常包含较少噪声,文本水平布局且大小恒定。而不规则文本则包含大量的噪声,例如弯曲文本,文本遮挡或模糊不清,甚至包括一些艺术字体。在某些情况下,为了实现艺术效果,文本可能会和背景图片融合在一起,导致文本特征不够明显。
3、随着场景文本识别技术的发展,对于一般的规则文本,已经能够达到很好的识别效果。但是对于模糊或者遮挡的文本,由于部分视觉特征缺失,模型往往难以有效识别。最近许多模型提出使用语言模型或者词典来对识别的文本进行纠正,取得了不错的效果。然而,由于现有的大多数文本识别方法都是使用裁剪的图片(只包含文本的图片),缺少相应的背景信息。仅依赖裁剪图片的视觉特征,当遇到遮挡的文本会对模型带来巨大的挑战,即使使用了语言纠错模型,但由于模型的独立性,语言纠正错误时仅基于文本特征,正确的单词被错误纠正或者纠正后的单词仍不符合期望。
4、此外,基于大规模数据训练的视觉语言模型(例如clip),在跨模态领域表现出色,人们开始逐渐把clip引入场景文本识别领域。cn 117058667 a“一种基于clip的端到端场景文本识别方法”,引入了语言提示生成器、视觉提示生成器以及文本实例与语言匹配模块。通过借助clip中的语言知识,感知图片局部文本区域,进而获得文本分割图,实现对图片文本的定位,从而有利于后续文本的识别。该发明主要将clip应用于文本分割和检测部分,通过clip来感知图片中文本的位置。
技术实现思路
1、为了解决遮挡文本的识别问题,本发明提出了一种基于背景语义信息增强的场景文本识别方法和装置。
2、本发明将clip引入了文本识别分支,借用clip的语言能力,来获取文本所在的背景语义信息,增强网络的识别能力。仿照人类的思维方式,当面对模糊或者遮挡的文本时,通常会通过周围的信息来推断当前文本的含义。借助于clip,这是通过大量数据训练的多模态模型,能够提取文本所在的背景语义信息。将背景语义特征和文本图片的视觉特征融合后输入到模型中,可以丰富网络的特征,提升网络对遮挡文本的识别能力。相较于目前的方法,该方法可以获得更为先进的性能。
3、为解决上述问题,本发明提供的技术方案为:
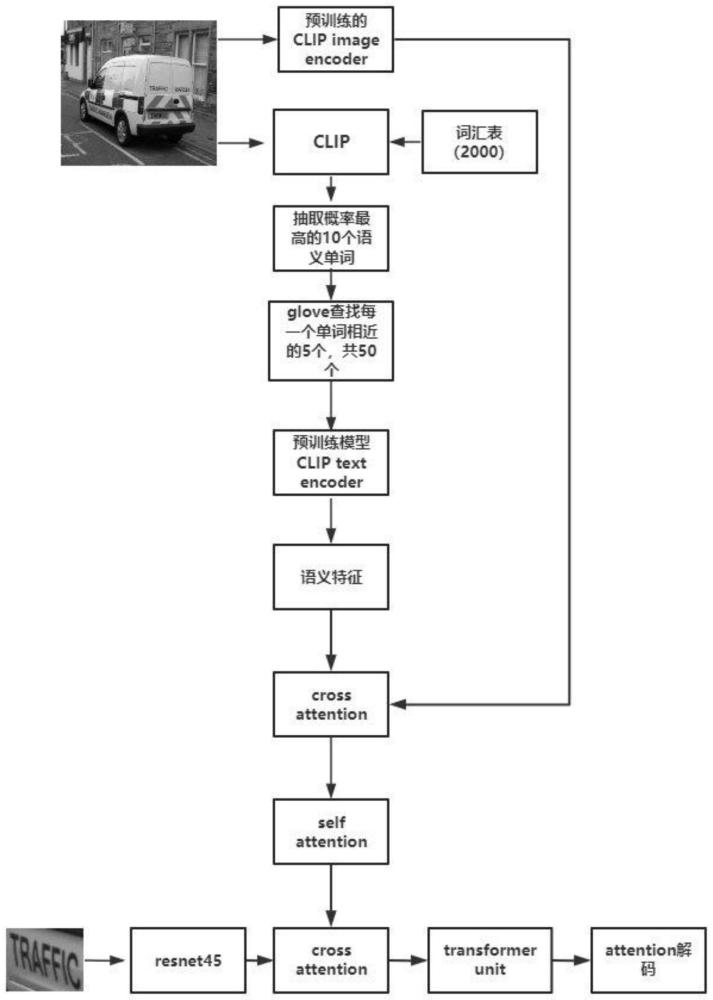
4、一种基于背景语义信息增强的场景文本识别方法,包含以下步骤:
5、步骤1:clip输入文本所在的背景图片和语义词汇表进行相似度计算,抽取背景图片的语义信息。
6、步骤2:抽取的语义单词通过glove查找相似的语义单词,以扩充语义词汇,获得更多的语义信息。
7、步骤3:将背景图片通过clip图片嵌入,语义信息通过clip文本嵌入,然后再用cross attention融合,重点关注于背景图片相关的语义信息。
8、步骤4:利用self-attention机制,进一步增强语义特征的内在关联性。
9、步骤5:输入裁剪后的文本图片,通过resnet45网络进行编码,获取裁剪图片特征。
10、步骤6:将裁剪的文本图片特征和通过clip获取的语义特征用cross attention做融合,让文本图片关注于相关的语义信息。
11、步骤7:将融合的特征通过transformer编码,进一步提取特征。
12、步骤8:最后使用attention并行解码出最后的单词序列。
13、本发明的一个实施例中,所述步骤1具体包括:使用clip模型输入文本识别的背景图片和语义词汇表进行相似度计算,从中抽取背景图片的语义信息。clip是一种基于对比文本-图像对的预训练方法,通过直接计算文本特征t和图像特征i的余弦相似性来匹配图片和文本。我们通过输入背景图片和包含两千个单词的词汇表来计算图片和文本的相似度,然后抽取相似度最高的10个单词,获得了关于图片的背景语义信息。
14、
15、本发明的一个实施例中,所述步骤2具体包括:通过glove对抽取的语义单词进行扩充,以获得更多的语义信息。由于clip在计算图片文本的相似度匹配时受到计算能力的限制,所以对于输入的词汇表的数量大小会有一定的限制。但是词汇表的数量太少又会影响背景语义信息的获取。为了解决这一问题,我们使用在更多单词上训练的glove来扩充背景语义词汇,具体实现使用余弦相似度来搜索近义词。已创建的预训练词向量实例glove.42b.300d.txt.pt的词典中有190多万个单词,包含着丰富的单词量。除去输入词和未知词,我们从中搜索每个单词语义最相近的5个词。然后将原始语义词汇和扩充的语义词汇混合,进一步丰富了语义信息。
16、本发明的一个实施例中,所述步骤3具体包括:将背景图片通过clip图片嵌入,语义单词通过clip文本嵌入,然后使用cross attention融合,这一步的目的是使网络关注和背景图片相关的语义信息,虽然glove扩充了语义信息的数量,但是由于扩充单词的过程是基于文本的操作,有可能导致扩充的词汇偏离了背景信息。因此,通过融合背景图片特征和语义特征是为了让背景图片关注于和其相关的语义信息。
17、本发明的一个实施例中,所述步骤4具体包括:利用self-attention机制,进一步增强语义特征的内在关联性。对于获取的背景语义信息,它们之间就存在这样一定的相关性,加强这些反映背景信息的语义关联性,能够更好的为文本图片提供有用的语义特征。
18、本发明的一个实施例中,所述步骤5具体包括:输入裁剪后的文本图片(图片大小为256x64),通过resnet45进行编码。卷积神经网络resnet45具有的残差结构,可以消除深度过大的网络训练困难的问题,防止网络退化,能够有效提取文本图片的特征。
19、本发明的一个实施例中,所述步骤6具体包括:裁剪后的图片提取特征后与通过clip获取的语义特征使用cross attention进行融合。cross attention是不同模态融合的一种方式,可以融合视觉特征和文本特征,能够有效地捕捉图像和文本之间的语义关联,从而实现更好的融合和理解。视觉特征作为q,语义特征作为k和v。通过cross attention,可以使裁剪后的文本图片关注于和自身相关的语义信息,有利于模型的正确识别。
20、
21、本发明的一个实施例中,所述步骤7具体包括:融合的特征ffusion通过transformerunit进行编码,获得特征tv,按照标签的字符顺序为图片特征添加位置编码p。cnn和transformer的结合方式,能够把cnn关注于局部的优势和transformer关注于整体的优势保留下来,从而使模型更好地提取特征,提升模型的准确率。
22、本发明的一个实施例中,所述步骤8具体包括:最后使用attention并行解码出单词序列。attention并行解码,效率高,实现容易。
23、g(v)=w1tanh(w2p+w3tv) (3)
24、ai=softmax(g(v)) (4)
25、c=aitv (5)
26、本发明通过多模态模型clip提取背景语义信息,通过glove获取和语义信息相近的词汇,丰富抽取的语义信息。然后将背景图片嵌入和语义信息融合,使背景图片关注于相关的语义信息。最后将语义信息融入到现有的文本识别网络,丰富模型的特征。相较于以往的方法,本发明在准确度上有一定的提升。
27、本发明与cn 117058667 a的区别在于:本发明主要利用clip的视觉语言能力来获取文本所在的背景语义,以丰富识别网络的特征,提升网络的识别能力。而cn 117058667a主要是利用clip感知图片中文本的区域。此外本发明在clip获取语义后使用glove来查找并获取和语义单词相近的词汇,极大丰富了背景语义信息。
28、本发明的第二个方面涉及一种基于背景语义信息增强的场景文本识别装置,包括存储器和一个或多个处理器,所述存储器中存储有可执行代码,所述一个或多个处理器执行所述可执行代码时,用于实现本发明的一种基于背景语义信息增强的场景文本识别方法。本发明的优点是:
29、1、本发明在场景文本识别分支引入多模态模型clip,利用clip强大的视觉语言能力,能够有效获取背景语义信息,进而增强识别模型的语言感知能力。
30、2、通过glove来查找和语义单词相似的词汇,来解决仅根据预先设定的词汇表导致获取语义词汇不够丰富的问题,进一步丰富背景语义信息。
- 还没有人留言评论。精彩留言会获得点赞!