面向边缘设备的深度学习模型加速系统及其加速方法与流程
本发明涉及深度学习模型,尤其涉及面向边缘设备的深度学习模型加速系统及其加速方法。
背景技术:
1、近几年来随着深度学习技术的快速发展,深度学习越来越多的应用到工业界中,如基于深度学习的图像识别、自动驾驶、自动翻译系统等,目前的深度学习模型由于其计算复杂性高、参数冗余,对硬件平台的内存、带宽等条件要求较高,从而导致在一些场景或设备上的推理部署存在限制,特别是面向边缘设备时,现有技术中通常采用对模型优化的方法对模型进行加速,其优化的方法包括模型压缩、软件库优化等技术;
2、目前的模型压缩技术中,压缩后的模型一般需要多次训练,其加速效果仍得不到明显提高;另外压缩处理后的模型在边缘设备中进行推理时,其推理运算数据量仍较大,加速效果仍较低,不能满足使用需求,综合上述情况,因此我们提出了面向边缘设备的深度学习模型加速系统及其加速方法。
技术实现思路
1、基于背景技术存在的技术问题,本发明提出了面向边缘设备的深度学习模型加速系统及其加速方法。
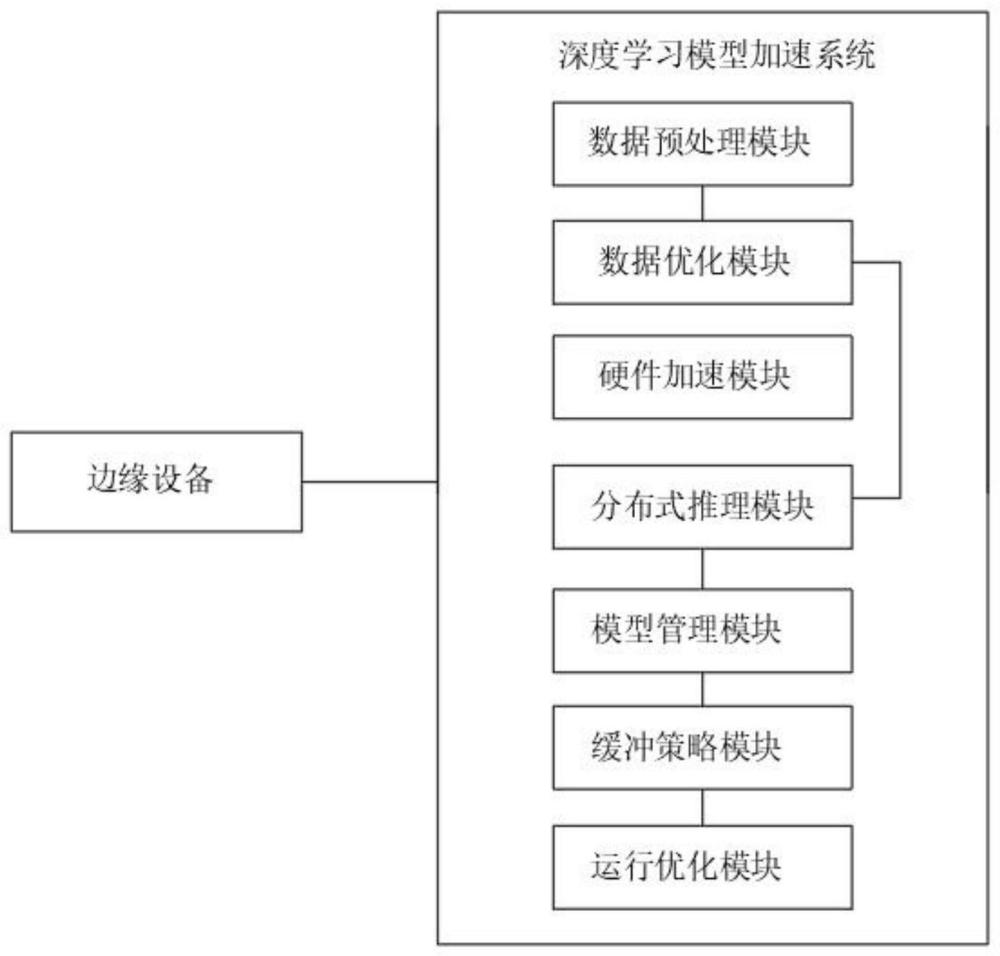
2、本发明提出的面向边缘设备的深度学习模型加速系统,包括边缘设备和深度学习模型加速系统,所述深度学习模型加速系统包括数据预处理模块、数据优化模块、硬件加速模块、分布式推理模块、模型管理模块、缓冲策略模块和运行优化模块;
3、所述边缘设备与深度学习模型加速系统相连接;
4、所述数据预处理模块与数据优化模块相连接;
5、所述分布式推理模块与数据优化模块和模型管理模块相连接;
6、所述缓冲策略模块与模型管理模块和运行优化模块相连接。
7、优选地,所述数据预处理模块用于对输入数据的格式进行转换、归一化和数据增强等操作,以便将数据转换为适合输入到深度学习模型的格式,其在对数据归一化时使用归一标准化的方法进行归一化,使用到的公式为:其中μ是均值,σ是标准差。
8、优选地,所述数据优化模块使用模型压缩、剪枝、量化等技术,用于减少模型的计算量、存储空间和计算复杂度,以提高模型的推理速度和性能,其中在剪枝过程中,一种常用的数学表达式是通过设定阈值来截断参数,将绝对值小于阈值的参数置为0,对于参数w,可以使用以下公式进行剪枝,$w'=\begin{cases}0,&\text{if}\|w|<\text{threshold}\w,&\text{otherwise}\end{cases}$,其中,w′表示剪枝后的参数值,threshold是设定的剪枝阈值。
9、优选地,所述边缘设备为路由器、路由交换机、集成接入设备(iad)、多路复用器以及各种城域网(man)和广域网(wan)接入设备中的一种或多种。
10、优选地,所述分布式推理模块通过使用轻量级网络结构、模型蒸馏等方法,减小模型的规模,从而加速模型的推理速度;
11、所述模型管理模块用于对模型的版本、更新和配置进行管理,以确保模型的正常运行和维护;
12、所述缓冲策略模块用于对处理后的边缘数据进行缓冲,同时结合边缘设备的计算资源进行设计,从而以减少数据的重复计算、提高推理效率,并对缓存数据进行管理和更新;
13、所述运行优化模块通过动态图优化、模型分割与卸载等技术,根据设备的实时状态和资源利用情况,实现运行时模型的优化与调度。
14、本发明还提出了面向边缘设备的深度学习模型加速方法,包括以下步骤:
15、s1:通过数据预处理模块对数据进行预处理;
16、s2:通过数据优化模块对预处理后的数据进行压缩、剪枝、量化等技术处理,以减少模型的计算量、储存空间和计算复杂度;
17、s3:通过硬件加速模块对边缘设备以及模型进行加速处理;
18、s4:通过分布式推理模块将大型深度学习模型分割成多个子模型,将其中一部分部署在边缘设备上进行推理,而将另一部分部署在云端进行远程推理,实现边缘设备与云端的协同计算;
19、s5:针对边缘设备的计算资源限制,设计并实现合理的缓存策略,以减少重复计算,提高推理效果;
20、s6:在s4中所述的模型的推理过程中对模型进行优化,以最大程度地提高模型的性能和能效。
21、优选地,所述s1中,对数据进行预处理时包括以下步骤:
22、s101:首先对原始数据进行清洗和预处理,去除噪声、异常值等不符合要求的数据;
23、s102:将数据缩放到特定的范围内,以便于模型训练和收敛,其使用到的方法为数据归一标准化,使用公式进行归一化处理;
24、s103:根据深度学习模型的要求,对数据进行转换,将图像数据可以转换为矩阵格式,文本数据可以转换为词向量表示,以便于模型的输入;
25、s104:对s103中所述的转化后的训练数据采用随机翻转法增强,以扩充训练样本的多样性,其中随机翻转法采用水平翻转,随机生成一个介于0和1之间的随机数r,如果r大于等于0.5,则进行水平翻转。
26、优选地,所述s3中,硬件加速模块对边缘设备以及模型进行加速处理时,包括以下步骤:
27、s301:选择合适的硬件加速器后,将转换格式后的深度学习模型部署到边缘设备上,并与硬件加速器进行连接和配置,在配置时,包括配置硬件加速器的参数和使用相关的api或sdk进行模型加载和推断的参数;
28、s302:在配置后,利用硬件加速器对输入数据进行模型推断,并输出推断结果;
29、s303:对s302中,模型输出的结果进行解码、解析和过滤处理,以得到最终的预测结果或应用效果;
30、s304:根据s303的预测结果,并根据边缘设备和实际应用需求,进行硬件加速器和模型的性能优化,其在性能优化时,需要调整硬件加速器的特定功能、加速器参数等,通过调整实现对边缘设备和模型的加速处理。
31、优选地,所述s5中,在针对边缘的计算资源限制,设计实现缓存策略时,使用缓冲策略模块进行运行,其运行的内容如下:
32、(1)、资源分析:首先分析边缘设备的计算资源限制,其包括内存、存储空间、计算能力等方面的限制,这样可以确定可用的资源大小和约束条件;
33、(2)、数据分析:分析模型推断过程中生成的中间结果数据的特点,包括数据大小、数据复用性、数据访问模式等;通过对推断流程和数据访问模式的分析,了解数据缓存的需求和机会;
34、(3)、缓存策略设计:根据资源分析和数据分析的结果,设计合理的缓存策略,这包括确定缓存的数据类型和大小,确定缓存的位置和范围,确定缓存的更新策略等;
35、(4)、缓存管理:实现缓存的管理逻辑,这包括缓存的创建和销毁、数据的缓存和清理、缓存的替换策略等,需要根据缓存的设计策略来管理缓存,以最大程度地利用有限的计算资源;
36、(5)、访存控制:实现对缓存的访问控制机制,这包括读取缓存数据、写入缓存数据、缓存的命中与失效判断等,通过有效的访存控制可以减少对计算资源的消耗,提高边缘设备的处理效率;
37、(6)、性能评估:对设计的缓存策略进行性能评估,通过模拟或实际部署在边缘设备上,测试缓存策略在实际场景中的性能表现,包括计算速度、资源利用率、缓存命中率等指标;
38、(7)、优化改进:根据性能评估的结果,对缓存策略进行优化改进,根据评估结果调整缓存的大小、更新策略、命中判断算法等,以提升缓存策略的性能和效果。
39、优选地,所述s6中,在对模型进行优化时包括以下方面:模型结构优化、参数优化、学习率调整、超参数调优和模型集成。
40、与现有的技术相比,本发明的有益效果是:
41、本发明通过对深度学习模型进行分割,采用边缘设备与远端协同计算的方式,再结合推理过程中的优化处理,可有效的减轻边缘设备的运算负担,提高模型的性能和能效,另外通过对计算的数据资源进行有效的缓存策略,减少重复计算,提高推理效果,从而实现加速的效果。
- 还没有人留言评论。精彩留言会获得点赞!