一种可提高预测精度的固废焚烧多温度同步预测方法
本发明属于城市固废焚烧,尤其涉及一种可提高预测精度的固废焚烧多温度同步预测方法。
背景技术:
1、固废(固体废弃物)焚烧是垃圾处理的主要手段,其炉膛焚烧温度直接影响到固废燃烧的稳定性、燃尽率、低温腐蚀、高温结焦、二次污染物的排放等等,因此需要监测与炉膛焚烧温度相关的参数并控制其恒定在一定范围内。由于温度传感器在焚烧的高温下容易损坏,降低了固废焚烧的运行效率及提高了运行成本,故现有对温度监测基本上采用预测方法。
2、目前固废焚烧温度预测通常以搭建神经网络模型实施,即利用神经网络模型,选取辅助温度变量作为模型输入,选取主要温度变量作为模型输出,通过计算辅助温度变量与主要温度变量的变化关系,最终得到主要温度变量的预测值。例如,公开号为cn110991756a的中国发明专利,公开了一种“基于ts模糊神经网络的mswi炉膛温度预测方法”,具体是通过搭建ts神经网络,以一次风加热温度、二次风加热温度、蒸汽量和干燥段炉排左外侧温度为模型输入,以炉膛温度为模型输出。由于所搭建的ts神经网络模型结构为多输入单输出,输入变量直接影响输出变量的预测值,若输入变量选择不当将导致输出变量的预测值与实际值产生偏差,从而导致温度预测精度不高,结果不准。
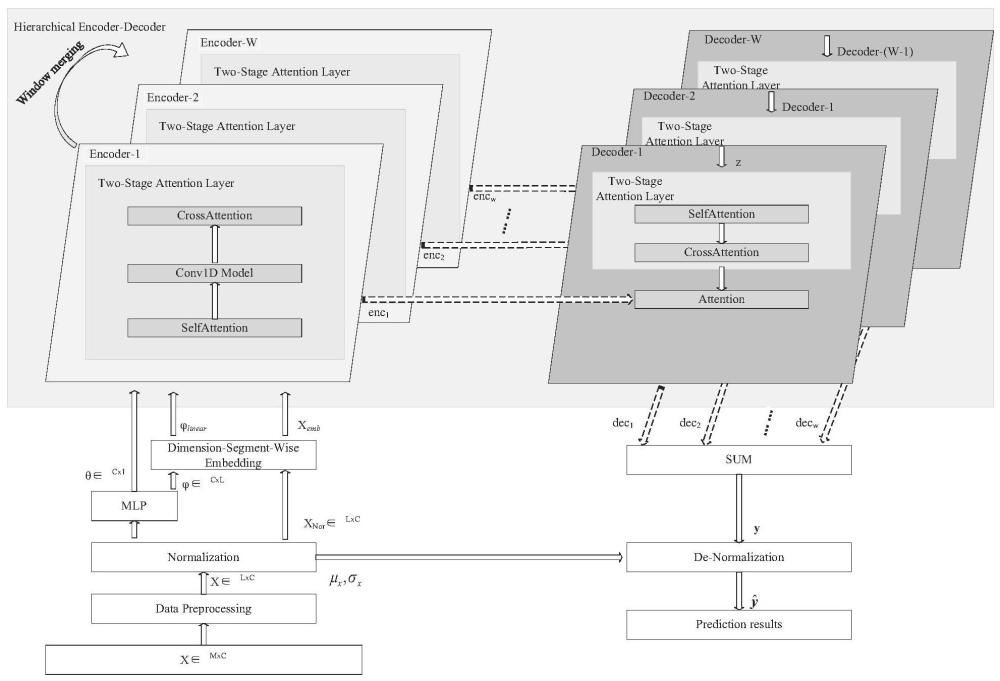
3、现有crossformer模型结构为hierarchical encoder-decoder,具体是设置有预处理模块、dimension-segment-wise embedding(分段嵌入)模块、分层编码模块、分层解码模块及求和模块,分层编码模块和分层解码模块的每一编码层及解码层都是由two-stageattention layer(自注意力模块和空间注意力模块)完成。具体实现方法是通过预处理模块对数据集进行去噪、归一化等预处理后,按照输入时间序列长度设定值提取样本数据;之后经过分段嵌入模块对时间序列进行等份分割并通过全连接层进行映射;然后再通过分层编码模块的第一编码层,计算单个时间序列及多个时间序列之间的注意力,输出本编码层计算结果,同时通过合并分割窗口合并后作为下一编码层的输入继续计算编码计算,遍历每一编码层,得到每一编码层的计算结果并保存;分层解码模块的第一解码层的输入分别为可学习的随机张量z及第一编码层的输出,分层解码模块的第一解码层的输入分别为可学习的随机张量z及第一编码层的输出,随机张量z经过双层注意力计算后再与第一解码层的输入进行attention计算,得到本解码层预测结果;分层解码器模块的其余解码层的输入分别为上一解码层的输出及对应编码层的输出,上一解码层的输出经过双层注意力计算后再与对应编码层的输出进行attention计算,得到计算结果;最后,将所有解码器层的预测结果求和得到最终预测值。现有crossformer模型在整个预测过程中,只考虑了多个时间序列之间的相关性并没有考虑单个时间序列的非平稳性,同时对单个时间序列的注意力特征提取不够,最终影响模型的预测精度。
技术实现思路
1、本发明是为了解决现有技术所存在的上述技术问题,提供一种可提高预测精度的固废焚烧多温度同步预测方法。
2、本发明的技术解决方案是:一种可提高预测精度的固废焚烧多温度同步预测方法,是将多个温度变量输入到预测模型中进行温度预测,所述预测模型按照如下方法进行构建:
3、步骤1.搭建网络模型
4、对crossformer模型进行改进,具体是在数据预处理模块与分段嵌入模块之间增加归一化模块和mlp前馈神经网络,所述归一化模块的输出分别与分段嵌入模块和mlp前馈神经网络相接,所述mlp前馈神经网络的输出分别与分段嵌入模块和分层编码模块的第一编码层的自注意力模块相接;所述分层编码模块的每一编码层的自注意力模块和空间注意力模块之间增加注意力卷积模块,所述注意力卷积模块由一维卷积层、批归一化层、激活函数层和池化层构成;所述求和模块后增加反归一化模块;
5、步骤2.训练网络模型
6、步骤2.1建立模型数据集
7、选取关键参数构建模型数据集所述m为样本个数,所述c为变量个数;
8、步骤2.2数据预处理
9、将数据集划分为训练集、验证集和测试集,并按照输入序列长度设定值l提取样本数据
10、步骤2.3归一化处理
11、按照公式(1)对样本数据进行归一化处理,得到归一化后的样本数据
12、
13、式中分别表示样本数据的平均值和标准差,具体分别按照公式(2)、(3)进行计算:
14、
15、
16、所述l表示输入序列长度设定值,xi表示样本数据中的每一个温度数据;
17、2.4计算非平稳因子
18、以输入样本数据及其平均值作为mlp前馈神经网络的输入参数,按照公式(4)计算第一个非平稳因子并以输入样本数据和其标准差作为mlp前馈神经网络的输入参数,按照公式(5)计算第二个非平稳因子θ;
19、
20、θ=exp(mlp(σx,x)) (5)
21、步骤2.5数据及非平稳因子分段处理
22、分段嵌入模块将归一化后的样本数据和第一个非平稳因子进行分段处理,具体如下:
23、将样本数据按照公式(6)进行分段,得到n个如公式(7)所示的补丁xpatch;
24、
25、
26、式中s表示每个补丁xpatch的长度,n表示补丁xpatch的总数;
27、通过分段嵌入模块的线性层对补丁xpatch进行特征变换,得到如公式(8)所示的分段嵌入样本数据xemb;
28、xemb=linear(xpatch,d) (8)
29、其中d是模型的特征维数;
30、将第一个非平稳因子进行分段处理,依次得到分别如公式(9)、(10)所示的分段嵌入的第一个非平稳因子
31、
32、
33、其中nd表示非平稳因子的特征维数;
34、步骤2.6编码处理
35、分层编码模块以样本数据xemb、第一个非平稳因子及第二个非平稳因子θ为参数进行计算,具体如下:
36、步骤2.6.1通过自注意力模块按照公式(11)计算非平稳自注意力xself;
37、
38、式中:
39、
40、θ′=unsqueeze(θ) (14)
41、所述q′=(q-1*μqt)/σx,q是查询向量,q=[q1,q2,q3…ql-1,ql]t,μq,σx分别代表查询向量的平均值和标准差;
42、所述k′=(k-1*μkt)/σx,k是键向量,k=[k1,k2,k3…kl-1,kl]t,μk,σx分别代表键向量的平均值和标准差;
43、所述v′=(v-1*μvt)/σx,v是数值向量,v=[v1,v2,v3…vl-1,vl]t,μv,σx分别表示样本数据的平均值和标准差;
44、步骤2.6.2通过注意力卷积模块按照步骤2.6.2.1-2.6.2.4提取特征;
45、步骤2.6.2.1通过一维卷积层对非平稳自注意力xself进行卷积特征提取,得到如公式(15)所示的卷积结果
46、
47、步骤2.6.2.2通过批归一化层对卷积结果xconv执行批归一化处理,得到如公式(16)所示的批归一化后的结果
48、xnorm=batchnorm1d(xconv) (16)
49、步骤2.6.2.3通过激活函数层将批归一化后的结果由gelu激活函数进行非线性转换,得到如公式(17)所示的非线性变换的结果
50、xgelu=gelu(xnorm) (17)
51、步骤2.6.2.4通过池化层对非线性变换的结果xgelu进行降低特征维数处理,得到如公式(18)所示的最大池化操作的结果
52、xpool=maxpool1d(xgelu) (18)
53、如公式(19)所示,将池化操作的结果转换为原始形状
54、
55、步骤2.6.3通过空间注意力模块计算,得到如公式(20)所示的空间维度注意力xcross,即本编码层输出encj,所述j为1≤j≤w的整数,是分层编码模块的编码层序数,所述w为分层编码模块的编码层总数;
56、xcross=crossattn(xpool) (20)
57、步骤2.6.4合并分段数据
58、根据窗口合并参数对分段样本数据xcross和第一个非平稳因子进行合并;
59、步骤2.6.5遍历编码层
60、从j=1起,以本编码层合并的分段数据作为下一编码层的输入参数,重复步骤2.6.1-2.6.4,直至得到最后编码层的计算结果encw,保存每编码层的计算结果;
61、步骤2.7解码处理
62、分层解码模块的每一解码层按照公式(21),根据其输入参数计算该层的预测值decj:
63、
64、其中为可学习的随机张量z,表示第j编码层的计算结果,decj表示第j解码层的输出;
65、步骤2.8求和处理
66、将所有解码层的输出结果decj进行求和,得到如公式(22)所示的预测结果y;
67、
68、步骤2.9反归一化处理
69、根据样本数据的平均值μx和标准差σx,按照公式(23)对预测结果y进行反归一化处理,得到c个温度变量的最终预测结果
70、
71、本发明是将深度学习、注意机制和潜在特征提取等算法结合起来并引入了非平稳性的概念,同步预测固废焚烧过程中的几个关键温度参数。具体是通过设置归一化模块计算样本数据的平均值和标准差;所设置的mlp前馈神经网络,利用标准差和平均值计算非平稳因子,还原原始数据的分布特征;所设置的注意力卷积模块可提取时间序列特征,增强双层注意力的计算效果。本发明还原了原始数据的分布特征,对原始数据集的各个温度参数进行相关分析,使预测结果更接近实际温度数据的变化,有效提高了固废焚烧的温度预测精度。
- 还没有人留言评论。精彩留言会获得点赞!