一种基于随机采样的点云语义分割方法
本发明属于点云处理领域,具体涉及一种基于随机采样的点云语义分割方法。
背景技术:
1、在点云的语义分割领域,最近的研究集中在如何解决lidar在较远距离上点云的稀疏性问题。这种稀疏性极大降低了点云的语义分割精度。这些年来kpconv、pointcnn、pointtransformer、swin3d等最先进的点云网络在自动驾驶等大场景中表现出色。然而,在小规模场景中,精确分割形状更为复杂的物体则很少被研究,比如分割人手持握不同物体。
2、基于随机采样的randla-net在lidar捕获的大规模点上实现了快速准确的语义分割结果。然而,该方法在小规模场景的应用中,忽略了小型物体的旋转多样性。因此需要设计一种基于随机采样的点云语义分割方法,用于在小规模场景对复杂物体的精确分割。
技术实现思路
1、为解决上述问题,本发明公开了一种基于随机采样的点云语义分割方法,一方面基于randla-net的局部特征提取流程,通过添加t-net预测的变换矩阵,使得物体的旋转多样性得以泛化;另一方面基于kdtree算法,对点云进行数次快速的中心近邻采样,设计了一种基于随机采样的点云语义分割方法。实验表明,该方法在小规模场景对复杂物体的精确分割中,相较同类方法具有显著优势。
2、为达到上述目的,本发明技术方案如下:
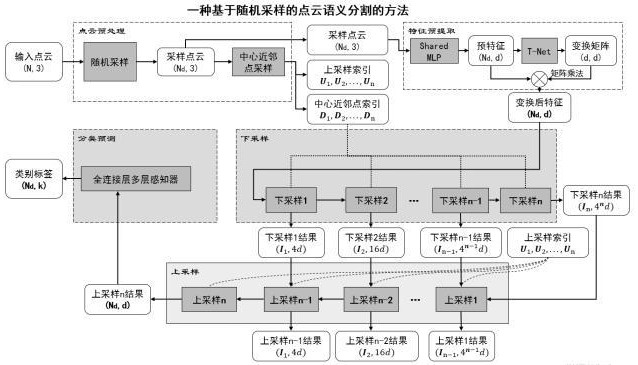
3、(1)对于一组待分割的输入点云(n,3),将输入点云随机采样为采样点云(nd,3),该采样点云的尺寸为固定值。
4、所述输入点云,其尺寸为(n,3),代表有n个三维坐标所构成,其中n可以是任意值。
5、所述采样点云,通过随机采样的方法,将输入点云随机采样为采样点云,该采样点云的尺寸为(nd,3),其中nd是预先设置好的固定值,对于n<nd的情况,可以重复采样。
6、(2)对于步骤(1)中的采样点云,运用kdtree算法,进行中心近邻采样,得到中心近邻点索引d1,d2,...,dn,和上采样索引u1,u2,...,un。
7、所述中心近邻点索引,其意义在于,对于本发明中下采样部分的n次下采样,都需要输入对应的中心近邻点索引。对于每个中心近邻点索引的尺寸如下:
8、d1,d2,...,dn=(i1,k1),(i2,k2)...(in,kn) 公式1
9、公式1中in,kn代表了在下采样部分的n次下采样中,对in个中心点的kn个近邻点在采样点云(nd,3)中的索引。对该中心近邻点索引在1维取0时进行查询的结果,代表in个中心点自身在采样点云(nd,3)中的索引。需注意,对于di+1的索引是基于di索引在采样点云中查询的结果,因此di+1索引的全部点云应当被di索引的全部点云所包含。
10、所述上采样索引,其意义在于,对于本发明中上采样部分的n次上采样,都需要输入对应的上采样索引。对于每个上采样索引的尺寸如下:
11、u1,u2,...,un=(in-1,1),(in-2,1),...(i1,1),(nd,1) 公式2
12、上采样索引旨在查询低尺寸的点云在高尺寸点云中的最近点的索引,以便将经过下采样后的高维低分辨率张量拼接至低维高分辨率张量之后,在还原点云尺寸的同时保留高维特征。需注意,每一个上采样索引是基于每一个中心近邻点索引,因此应当在中心近邻点索引之后再进行上采样索引的获取。
13、(3)对步骤(1)中所述的采样点云,经过shared mlp提取一组预特征(nd,d),将预特征经过t-net获得一组变换矩阵(d,d),将预特征与变换矩阵进行矩阵乘法,得到变换后特征(nd,d)。
14、(4)对步骤(3)中的变换后特征(nd,d),利用步骤(2)中的中心近邻点索引,依次执行n次的下采样,得到结果(in,4nd)。该步骤目的在于通过聚合来自每个中心点邻域的特征来减小点云尺寸并增加特征维度,以最大限度地提升对点云局部几何特征的感知,该模块由两个核心组件组成:局部空间编码模块和注意力池化模块。注意力池化模块直接连接在局部空间编码模块之后。一次下采样包含以下分步骤:
15、(4.1)将输入点云的(nd,d)尺寸特征与对应的三维坐标合并为(nd,3+d),其中3代表3维坐标。
16、(4.2)将(4.1)中(nd,3+d)的点云特征经过一次shared mlp得到(nd,2d)的点云特征。基于其对应的中心近邻点索引(i,k),得到查询结果:尺寸(i,k,3)的中心近邻点坐标和尺寸(i,k,2d)的中心近邻点特征。
17、(4.3)将(4.2)中的中心近邻点坐标按照公式3进行位置编码,得到尺寸(i,k,10)的局部编码特征,并将其经过一次shared mlp,得到尺寸(i,k,2d)的局部编码特征。将局部编码特征与(i,k,2d)的中心近邻点特征相拼接,得到(i,k,4d)的局部特征。
18、(4.4)将(4.3)中(i,k,4d)的局部特征经过一次shared mlp得到特征权重(i,k,1),并通过乘以权重,得到(i,k,4d)的加权特征。对加权特征在中间维度进行求和池化,得到(i,4d)的局部特征。
19、(4.5)将(4.4)中的局部特征经过一次shared mlp得到输出特征(i,4d),并与其对应的三维坐标进行拼接,一同作为下一次下采样流程的输入。
20、
21、在公式3中,cr,cc,cn分别表示某邻点与其中心点的相对坐标、其中心点坐标、邻点坐标,r表示某邻点到中心点的距离。因此,空间编码将占用3+3+3+1=10个维度,使其在(4.3)中输出尺寸(i,k,10)的局部编码特征。
22、(5)对步骤(4)中的下采样的输出特征(in,4nd),基于步骤(2)中上采样索引依次进行n次上采样,得到结果(nd,d)。上采样过程将较小尺寸的高维点云特征与较大尺寸的低维点云特征相融合,目的在于为每个点提供语义分割的依据。一次上采样包含以下分步骤:
23、(5.1)将第i次下采样的输出点云(in-i,d)和第i-1次下采样的输出点云(in-i+1,4d),以及对应的上采样索引(in-i+1,1)作为输入。
24、(5.2)将(5.1)中(in-i+1,4d)的点云特征,通过其(in-i+1,1)的上采样索引进行查询,得到(in-i,4d)的点云特征,并与第i次下采样的输出点云(in-i,d)进行拼接,得到(in-i,5d)的点云特征。
25、(5.3)将(5.2)中的(in-i,5d)的点云特征经过一次shared mlp后,得到(in-i,d)的输出点云特征,作为下一次上采样的输入。
26、(6)对步骤(5)中(nd,d)的上采样结果,经过多层全连接层后,通过softmax激活函数,得到(nd,k)的语义分割结果,其中k代表所需分类的类别数。至此,语义分割任务完成。即对每个点云中的点,都预测了其所属类别。
27、本发明所述的方法结构,由点云预处理部分、特征预提取部分、下采样部分、上采样部分、分类预测部分,五个部分构成。其中步骤(1)(2)对应本发明的点云预处理部分;步骤(3)对应特征预提取部分;步骤(4)对应下采样部分;步骤(5)对应上采样部分;步骤(6)对应分类预测部分。
28、本发明的有益效果为:
29、(1)通过点云预处理、特征预提取、下采样、上采样、分类预测等步骤对任意数量的三维坐标点构成的点云进行快速的语义分割,其准确率高,运算速度快,与同类算法相比具有显著优势。
30、(2)本发明对randla-net算法、t-net算法、kdtree算法进行了改进,基于randla-net的局部特征提取流程,通过添加t-net预测的变换矩阵,使得物体的旋转多样性得以泛化;除此之外,本发明基于kdtree算法,对点云进行数次快速的中心近邻采样,设计了一种基于随机采样的点云语义分割方法。实验表明,该方法在小规模场景对复杂物体的精确分割中,相较同类方法具有显著优势。
- 还没有人留言评论。精彩留言会获得点赞!