基于生成对抗网络的人脸图像超分辨重建方法
本发明属于图像处理及人脸超分辨重建,具体涉及一种基于生成对抗网络的人脸超分辨率重建方法。
背景技术:
1、人脸超分辨率重建技术是针对人脸这个特殊结构的超分辨率技术,旨在将低分辨率人脸通过某种技术转换为高分辨率人脸。但是人脸结构比较特殊,不像平常的图像,它具有高强度的结构相似性和身份信息的细节差异性,它的重建难度更大,要求更高,重建过程中,我们要保证几何特征的一致性,还要注意纹理信息的准确恢复。因此,人脸超分辨率重建具有极大的挑战。人脸超分辨这一概念最早由baker和kanada在2000年提出来的,它是图像超分辨领域中的一个分支,专门针对人脸这一特殊场景进行超分辨。近年来,深度学习技术在图像处理方面应用广泛,因此人脸超分辨领域也开始结合深度学习技术,从此人脸超分辨领域开始进入一个新的发展阶段。
2、基于深度学习的人脸超分辨率技术按照网络结构的不同可以分成:基于插值的人脸超分辨率重建、基于重构的人脸超分辨率重建、基于卷积神经网络的人脸超分辨方法和基于对抗生成网络的人脸超分辨方法。dong等人提出了srcnn模型,第一次将深度学习应用到图像超分辨率。srcnn首先使用双三次插值将lr图像放大到目标大小,然后通过三层卷积神经网络提取图像特征,建立非线性映射关系,最后生成hr图像,极大提高了重构效果;sha等通过改变残差网络结构构建并行残差网络,能增强网络特征提取能力并提高网络训练速度;shang等在网络中引入小核卷积有效降低了网络的噪声输入;xiao等改进重建时的上采样方式,从多角度捕捉图像特征信息。为了降低网络的复杂度,提高图像重建的速度;guo等将递归网络与残差网络进行结合来有效降低网络参数量;sun等采用多尺度残差网络使得重建的图像不局限于固定的尺度,能高效的训练出针对任意倍数重建的网络模型。这些模型在训练时都使用了逐像素均方误差mse损失函数,重建图像在psnr和ssim评价指标上都有明显的提升,但是缺乏感官上的真实感。gan网络以其无监督学习的方式被广泛应用,为超分辨率重建提供了无限的可能性;在生成对抗网络的基础上,leding等将gan用在了解决超分辨率问题上,提出了一种基于图像超分辨率的生成对抗网络(srgan),使用一个经过训练的判别器网络来区分sr图像和原始真实图像,可使重建的图像更符合人眼感知,具有真实感,但该算法的人脸图像重建结果存在过多失真,对眼睛等部位的重建效果不理想。
3、因此,如何更大程度地提升重建图像的感知质量,充分利用高频特征和减少冗余信息,提供一种基于生成对抗网络的人脸超分辨率重建方法是本技术领域技术人员亟需解决的问题。
技术实现思路
1、本发明的目的在于克服现有技术的不足,提供了一种基于生成对抗网络的人脸超分辨率重建方法,基于srgan网络进行改进,引入高效通道eca注意力机制,设计了人脸超分辨率重构网络,以提高人脸超分辨率重构的准确度和人脸图像的重建质量。
2、为了实现上述目的,本发明采用如下技术方案:
3、基于生成对抗网络的人脸超分辨重建方法,其特征在于,包括:低层特征提取网络、高层特征提取网络、上采样网络、重建网络和判别网络;
4、低层特征提取网络,用于提取人脸图像的低层特征,使用一个9×9的卷积层对低分辨率人脸图像进行特征提取,之后经过prelu激活函数,这个卷积层只能从低分辨率图像中提取初步特征,得到人脸图像的低层特征;
5、高层特征提取网络,用于提取人脸的深层特征,将上一步提取的低分辨率人脸图像输入到高层特征提取网络进行深层特征提取,该模块包括32个残差块,每一个残差块都包含两个3×3的卷积核,经过hardswish激活函数,再经过eca高效注意力模块;之后经过一个短跳跃连接,最后图像经过一个卷积层和一个长跳跃连接,得到提取出来的高层特征图像;
6、上采样网络,将高层特征提取网络提取的图像输入到两个子像素卷积层,对图像进行放大,再经过prelu激活函数,得到高分辨率人脸图像;
7、重建网络,将上采样网络生成的高分辨率图像经过一个9×9的卷积核,对图像进行最后的重建,输出最终的超分辨率图像;
8、判别网络,将生成的超分辨率图像和原始的高分辨率图像同时输入到判别网络中,判别图像是真实图像的概率,通过判别网络和生成网络的不断对抗,使得最终输出的超分辨率图像愈发接近真实图像;
9、优选的,高层特征提取网络包括:
10、将低分辨率人脸图像输入到高层特征提取网络进行深层特征提取,该模块包括32个残差块,每一个残差块都包含两个3×3的卷积核,使用hardswish激活函数替换原本的prelu激活函数,在每一个残差块之后添加eca高效注意力模块,增强特征信息的提取;之后经过一个短跳跃连接融合信息,经过32次残差块提取信息之后,最后图像经过一个3×3卷积层和一个长跳跃连接,融合前面的所有特征图像信息,得到提取出来的高分辨率图像;
11、优选的,判别网络包括:
12、首先将生成的超分辨率图像和原始的高分辨率图像同时输入到判别网络中,经过6层卷积提取图像特征,卷积层的通道数以2倍逐层增加到512,由最初的64个通道逐步增加,选择激活函数为leakyrelu。我们引入patchgan思想,基于patchgan算法改进的判别器网络与传统gan网络的判别器相比,并不是将输入映射为一个实数,而是映射为一个矩阵x的形式,矩阵中的每个元素对应输入n×n大小的patch样本块为真的概率值,最后通过对由概率值组成的概率矩阵求均值得到判别器的最终输出,这样可以强化判别网络对高频特征细节的判别能力,关注更多的局部纹理细节,提高重构人脸图像质量;
13、优选的,损失函数包括:
14、⑴像素损失
15、像素损失是在超分辨率领域广泛应用的基于均方误差(mse)的损失函数,如下公式:
16、
17、其中,ilr表示低分辨率图像,表示像素损失函数,w和h分别表示vgg网络中特征图的宽和高,表示生成网络输出的重建图像isr,ihr表示高分辨率图像;
18、⑵内容损失
19、使用mse作为损失函数有助于生成psnr较高的超分辨率图像,但过度平滑和过多高频信号的滤除会导致人脸图像的失真,降低视觉上的真实性。因此,本发明用vgg19网络损失来替代mse作为生成图像和原始样本数据间的欧氏距离,将生成网络的结果通过vgg某一层之后产生的特征图和高分辨率图像ihr通过vgg网络产生的特征图计算损失,指出这种损失更能反应图片之间的感知相似度。公式如下:
20、
21、其中,w和h分别表示vgg网络特征图的维度,表示生成网络输出的重建图像isr,ihr表示高分辨率图像,表示vgg网络第j层卷积之后,第i层最大池化层之前的特征图输出结果,wi,j、hi,j分别表示vgg网络中各自的特征图的尺寸;
22、⑶对抗损失
23、为了使得生成器重建的图像能够欺骗判别器,根据判别器添加了对抗损失函数,公式如下:
24、
25、其中,表示对抗损失,表示重建出的高分辨率图像,表示重建出的图像是真实的高分辨率图像的概率;
26、⑷判别损失函数
27、判别网络仅考虑对抗损失作为损失函数,分别将原始高清图像和生成的高分辨率图像输入到判别网络中,判别网络的损失函数为二分类交叉熵损失函数,公式如下:
28、
29、其中,xhr表示高分辨率图像,判别损失函数用来判别高分辨率图像是原始图像还是生成的高分辨率图像;
30、⑸总损失
31、基于改进的人脸超分辨率重建模型的训练效果主要由损失函数的选择决定,为了提高视觉上的保真度,我们将像素损失、内容损失和对抗损失三部分的加权和作为生成器的损失函数,总体损失函数可以描述为:
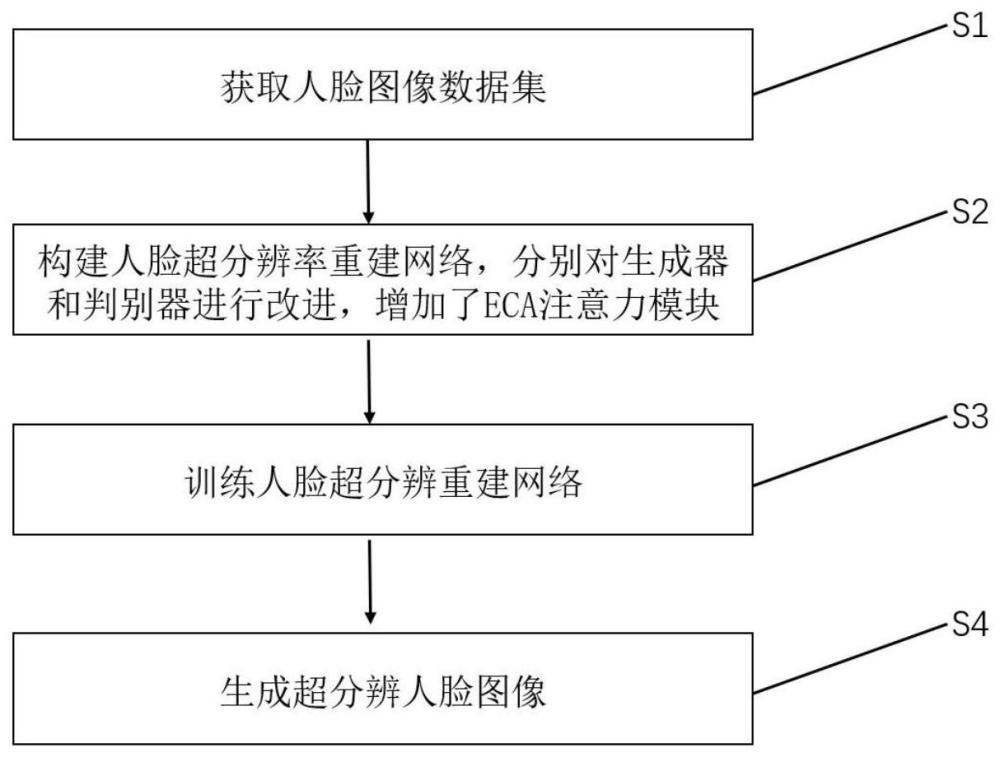
32、
33、其中,λmse、λperc、λgen表示权重系数,
34、表示感知损失,由对抗损失和内容损失组成;
35、表示像素损失,生成图像与真实图像的逐像素点mse损失;
36、表示内容损失,vgg网络中第i层第j个卷积核输出的特征图的mse损失
37、表示对抗损失。
38、基于生成对抗网络的人脸超分辨率重建方法,包括以下步骤:
39、s1.下载原始人脸图像数据集,训练时,从数据集原图像中随机截取出96×96的高分辨率图像块,使用双三次bicubic插值法将其下采样为24×24的低分辨率图像块,并作为原始的输入数据;测试时,使裁剪出的图像块尺寸满足尽量大且能被放大比例整除的条件,使用双三次bicubic插值法将其下采样为低分辨率图像进行测试。本发明对生成器部分网络以10-4的学习率进行100个周期的训练,对整体网络先以10-4的学习率进行50个周期的训练,再以10-5的学习率进行50个周期的训练;
40、s2.将s1经过处理获得的图像输入到低层特征提取模块中提取人脸图像的表层特征,使用卷积层对低分辨率人脸图像进行特征提取,这个卷积层只能提取人脸图像的低层特征,得到低分辨率图像ilr;
41、s3.将s2中得到的低分辨率图像输入高层特征提取网络中,经过32个残差块进行特征提取,每一个残差块都包含两个3×3的卷积核,使用hardswish激活函数替换原本的prelu激活函数,在每一个残差块之后添加eca高效注意力模块,增强特征信息的提取;之后经过一个短跳跃连接融合信息,经过32次残差块提取信息之后,最后图像经过一个3×3卷积层和一个长跳跃连接,融合前面的所有特征图像信息,得到提取出来的高分辨率图像;
42、s4.将s3中获得的高分辨率图像输入到上采样网络中,经过两个子像素卷积层,对图像进行放大,再经过prelu激活函数,得到高分辨率人脸图像;
43、s5.将s4中生成的高分辨率图像输入到9×9的卷积核,对图像进行最后的重建,输出最终的超分辨率图像isr;
44、s6.将s5中输出的超分辨率图像输入到判别网络中,经过6层卷积提取图像特征,卷积层的通道数以2倍逐层增加到512,由最初的64个通道逐步增加,选择激活函数为leakyrelu。我们引入patchgan思想,基于patchgan算法改进的判别器网络与传统gan网络的判别器相比,并不是将输入映射为一个实数,而是映射为一个矩阵x的形式,矩阵中的每个元素对应输入n×n大小的patch样本块为真的概率值,最后通过对由概率值组成的概率矩阵求均值得到判别器的最终输出,这样可以强化判别网络对高频特征细节的判别能力,关注更多的局部纹理细节,提高重构人脸图像质量;
45、s7.将s2获得的低分辨率图像ilr、原始高分辨率图像ihr、最终超分辨率结果isr输入到像素损失函数中,经过像素损失函数处理生成高分辨率图像,计算得到损失函数将生成网络的结果isr通过vgg某一层之后产生的特征图和高分辨率图像ihr通过vgg网络产生的特征图计算内容损失这种损失更能反应图片之间的感知相似度;将重建出的高分辨率图像输入到判别网络中进行判别,为了使得生成器重建的图像能够欺骗判别器,根据判别器添加了对抗损失函数为了提高视觉上的保真度,我们将像素损失、内容损失和对抗损失三部分的加权和作为生成器的损失函数lsr,不断迭代使损失函数最小化,经过训练,最后生成人脸超分辨网络模型;同时,判别网络仅考虑对抗损失作为损失函数,分别将原始高清图像和生成的高分辨率图像输入到判别网络中,判别网络的损失函数为二分类交叉熵损失函数ld;
46、s8.设定人脸超分辨网络模型的超参数,生成器网络以10-4的学习率进行100个周期的训练,对整体网络先以10-4的学习率进行50个周期的训练,再以10-5的学习率进行50个周期的训练,经过残差网络处理和损失函数最小化迭代,最后产生细节纹理清楚、效果更好的高分辨率人脸图像。
47、经由上述的技术方案可知,与现有技术相比,本发明的有益效果是:
48、(1)本发明将去除生成器部分bn层的srgan模型作为基础网络架构,为了充分利用注意力信息,使感兴趣的区域能够被准确地捕获,我们在残差块中增加了高效通道注意力eca模块,该模块通过学习通道注意信息,避免在学习通道注意力信息时,通道维度减缩,该模块只涉及少数几个参数,但具有明显的效果增益,有效捕捉到通道间的关系。同时,我们发现残差块的数量也会影响到重建效果,实验发现选择残差块数量为32效果增益最好;
49、(2)本发明在生成器部分将eca模块插入到残差组中每一个残差块的尾端,并用hardswish激活函数将网络中的prelu激活函数替换掉;判别器部分,引入patchgan思想,强化判别器网络对高频特征细节的判别能力,关注更多的局部纹理细节,提高重构人脸图像质量;
- 还没有人留言评论。精彩留言会获得点赞!