一种基于扩散模型的长文本生成连续图片的方法
本发明涉及自然语言处理和计算机视觉领域,具体涉及一种基于扩散模型从一段长文本中生成对应的多张连续图片的方法。
背景技术:
1、近年来,结合图像和文本的跨模态研究越来越多地引起自然语言处理和机器视觉领域学者的关注。其中文本生成图像是多模态机器学习的任务之一。文本生成图像是指将人类以关键词或句子形式的文本描述生成符合文本语义的图像的计算方法。文本自动图像生成可以帮助艺术家或平面设计师的减轻大量工作,也可以让用户自由发挥创作空间。
2、通过自然语言描述引导图像生成一直是图像生成领域的具有良好前景的发展方向,目前该领域的研究也取得了很大的进步和成果。比如vae方法以一种统计方法进行建模最大化数据的最小可能性来生成图像,而draw方法使用了循环神经网络,并利用注意力机制,每一步关注一个生成对象,依次生成并叠加出最终结果。基于gan生成对抗网络的方法,在后期逐渐成为主流。基于扩散模型的图片生成,和其他生成网络不同的是,扩散模型在前向阶段对图像逐步施加噪声,直至图像被破坏变成完全的高斯噪声,然后在逆向阶段学习从高斯噪声还原为原始图像的过程。
3、但针对长文本中生成对应的多张连续图片的技术研究相对较少,仍然存在以下问题:
4、1.模型无法完全理解文本语义,不能很好地关联图片内容和文本,大部分模型输入是简单句,对于复杂长文本难以很好地在图片中将信息表达完善,上下文信息获取不佳。
5、2.只能根据简单句生成单张图片,对于复杂文本的理解表现欠佳。对于一段内容丰富的文本也只能生成一张图片,不能生成连续多张图片。
6、3.无法更新上下文信息以有效地捕获背景变化;无法在生成每幅图像时结合新的输入和随机噪声,以形象化字符的变化,这些变化可能会导致图像生成时发生很大的变化。
7、4.在文本生成图像过程中,无法多图像生成进行其他方面的条件约束,只能依赖文本条件进行图像生成。
8、因此本发明从解决以上问题入手,提出一种可以从复杂长段文本中生成一系列有逻辑性的连续图片的方法。该方法可以实际中应用在多个领域,如从儿童故事中自动生成儿童绘本,从剧本描述中自动生成镜头画面等。
技术实现思路
1、为解决现有技术中存在的上述缺陷,本发明的目的在于提供一种基于扩散模型的长文本生成连续图片的方法,通过对长文本的分析处理,从长段文本中生成一系列连续图片。
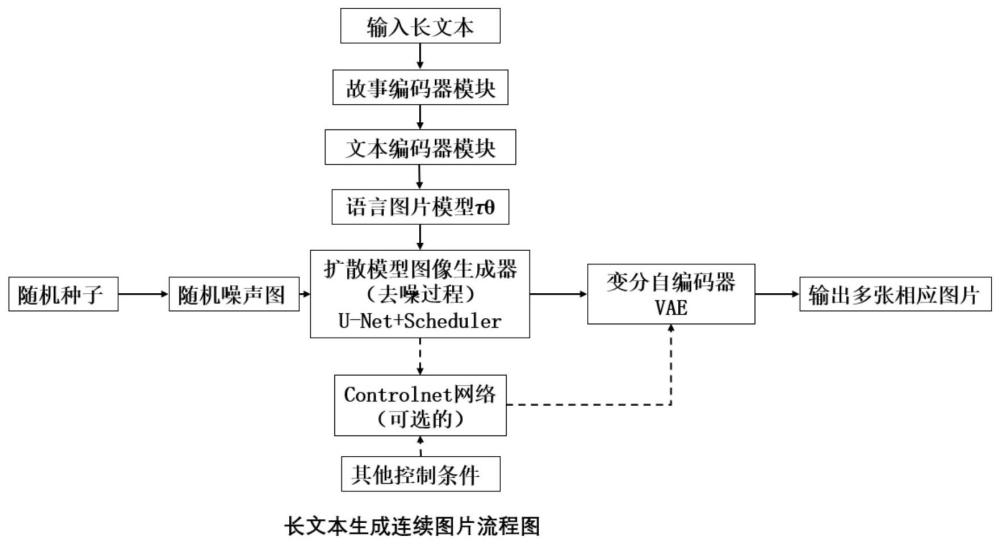
2、根据本发明的第一方面,提供一种基于扩散模型的长文本生成连续图片的方法,包括:
3、步骤10:将待处理长文本输入到文本分割器,输出包含多个句子的分割语句文本s,包括t个句子。
4、步骤20:将分割语句文本s输入到故事编码器模块,将分割语句文本s映射为低维嵌入向量h0。
5、步骤30:将低维嵌入向量h0输入到文本编码器模块,每个时间步对应处理一个句子,通过文本编码器在多个时间步的更新,在t时刻输出该时刻生成图像需要的所有必要信息ot。
6、步骤40:依次将t时刻生成的ot和随机生成的噪声图片输入到包含controlnet网络扩展的扩散网络模型中,输出待处理的与长文本对应的低维空间的连续图片xt。
7、步骤50:将低维空间的连续图片xt输入到变分自编码器的解码器模块,输出全尺寸图像xt。
8、在步骤40中,包含controlnet网络扩展的扩散网络模型包括:语言图片信息模型τθ,条件时序去噪编码器controlnet网络扩展。
9、语言图片模型τθ包含一个图片编码器和一个文字编码器,将输入的ot,进行语言图片信息转换后,输出中间表示τθ(ot)。
10、条件时序去噪编码器将输入的中间表示τθ(ot),通过多头交叉注意力机制映射到u-net主干网络,从而实现条件控制u-net主干网络,输出潜在空间内的图片信息xt1。
11、controlnet网络扩展将一组其他控制条件cf经过可训练副本模型处理得到图片信息xt2,再将输入的xt1与xt2进行组合,输出图片信息xt。
12、条件时序去噪编码器包括多头交叉注意力机制模块、u-net主干网络、采样器。
13、多头交叉注意力机制模块输入τθ(ot),根据嵌入向量得到q,k,v三个向量,再经过计算得到最终输出隐变量attention(q,k,v),其输出传入每一个残差网络模块中,并通过残差链接跳跃至后面对应的残差网络模块中,具体处理过程为:
14、
15、
16、φi(zt)是u-net主干网络的中间表示,τθ(ot)是通过语言图片转换得出的中间表示,可训练参数矩阵
17、u-net主干网络的输入是随机加噪图和噪声强度,输出是减去加噪图上所加的噪声后的图片信息xt1。u-net主干网络包括多个resnet残差网络模块;每一层残差网络模块的输入都是上一层的交叉注意力层输出的隐变量attention(q,k,v)和时间序列向量,隐变量经过卷积变换后和经过全连接投影的时间序列向量做加和,再和经过残差链接的原始隐向量做加和,再经卷积层处理得到经残差网络编码变换后的隐变量输出。
18、采样器是负责条件时序去噪编码器的正向扩散过程和反向扩散过程。
19、条件时序去噪编码器是通过正向扩散过程和反向扩散过程进行训练的,训练步骤包括:步骤401正向扩散过程,为训练过程采集训练样本数据集,步骤402反向扩散过程,训练u-net主干网络。
20、步骤401包括:收集一系列样本图像,用变分自编码器的编码器压缩至低维空间;正向扩散过程在样本图像x0上逐步增加高斯噪声,每一步得到的图像xd只和上一步的结果xd-1相关,直至第d步的图像xd变为纯高斯噪声,该过程将产生一系列噪声图像样本x1,…,xd;也就是说每一时间步的xd是从一个,以为均值,βt为方差的高斯分布中采样得到的。βd是方差,是一系列固定的值,且β1<β2<···<βd。增加高斯噪声的过程为马尔科夫过程,满足:
21、
22、
23、给定αd=1-βd,结合①②得出用以对xd进行训练样本采集。
24、q表示条件分布概率函数,即在已知x0的情况下xd的概率,其中βd是方差,其中βd∈(0,1),d∈[1,d]是一系列固定的值,i是单位矩阵,为高斯分布符号,表示条件概率服从高斯分布。
25、步骤402包括:经过正向扩散扩散过程得到的训练样本集包括:噪声强度、噪声图像样本、噪声图;训练后得到的u-net主干网络,在已知噪声强度的条件下,根据噪声图像中计算出噪声图;生成图片时,用噪声图像减掉噪声图恢复出原图;反向扩散过程的训练目标函数为:
26、
27、z0=e(x0)
28、
29、其中,z0是经过压缩编码的原始图像,zt是加噪图像,t是时间步长即加噪次数。ε是独立同分布标准正态随机变量;是目标值,是条件时序去噪自编码器的处理结果,e表示数学期望即平均值;u-net主干网络增加条件输入θ(ot),语言图片模型τθ和条件时序去噪编码器是基于lldm1联合训练的。
30、controlnet网络扩展对图像生成进行多条件控制,即除文字条件控制生成图片的同时,还通过包含线稿和深度图的条件控制生成图片;controlnet网络扩展的组建步骤包括:步骤403克隆预训练模型,步骤404定义输入条件,步骤405训练可训练副本,步骤406合并训练,步骤407合并输出。
31、步骤403包括:创建上述预训练过的时序去噪编码器的两个副本,其中一个是“锁定”的,不能被修改,而另一个是“可训练”的,可以在特定任务上进行微调。
32、步骤404包括:定义一组输入条件cf,用以控制整个包含controlnet网络扩展的扩散网络模型的输出;输入条件包括:颜色方案、对象类别、用户涂鸦、边缘映射、分割映射、pose关键点。
33、步骤405包括:根据应用场景收集并制作对应的图像数据集,该数据集基于输入条件对可训练副本进行训练。
34、步骤406包括:合并训练,训练流程与时序去噪编码器训练流程相同;其中,controlnet网络扩展训练过程中将50%的文本提示随机替换为空字符串;训练的目标函数为:
35、
36、ct=θ(ot)
37、其中cf是特定的其他条件,t是时间步长。
38、步骤406包括:将两个模型副本的输出组合起来,输出最终结果xt。
39、进一步地,本发明所提供的方法,步骤10中,文本分割器的作用在于合理切割长文本的同时,不破坏语义信息;文本分割器包括:前向lstm层、后向lstm层、sigmod激活函数层。
40、其中,前向lstm层将输入的第一句分割文本从前往后传递嵌入第一个句子结尾的模式,输出嵌入1;后向lstm层将输入的第二句分割文本从后往前传递嵌入第二个句子开头的模式,输出嵌入2;将嵌入1和嵌入2连接起来输入sigmod激活函数层,输出结果如果大于0.5则决定分割两个句子,依次读入长文本句子,即可针对长文本进行分割,可分割为t句输出分割后的文本s。
41、文本分割器通过训练得到,训练过程包括:步骤101创建数据集,步骤102搭建模型结构,步骤103优化模型参数。
42、步骤101包括:分别创建正例和负例的数据集;正例是应该被分割开的两个句子,句子中间以“\n”分割;负例是应该被合并的两个句子,句子之间没有“\n”;所有正例和负例随机划分训练集和验证集。
43、步骤102包括:搭建前向lstm层、后向lstm层,将输出的嵌入1和嵌入2连接起来;采用sigmoid函数作为激活函数,确定损失函数为:其中是sigmoid函数输出值,代表预测样本是正例的概率,y是样本标签,如果样本属于正例,取值为0,否则取值为1。
44、步骤103包括:使用梯度下降求解,通过找到求导找到损失函数最快下降的方向,逐渐逼近最优解模型。
45、进一步地,本发明所提供的方法,步骤20中,故事编码器的作用是将s随机映射到一个低维的向量空间,得到的向量h0不仅包含了s全部的信息,同时还作为文本编码器隐状态的初始值;故事编码器模块包括:词向量嵌入模型;其训练过程包括:步骤201预处理文本数据集,步骤202确定训练参数,步骤203训练并优化模型参数,步骤204获取词向量表示。
46、步骤201包括:对输入的文本去除所有停顿符号,进行jieba分词,同时生成一个词汇表,每个词统计词频,按照词频从高到低排序,取最频繁的v个词,构成一个词汇表,每个词存在一个one-hot词向量,词向量的维度是v,如果该词在词汇表中出现过,则词向量中词汇表中对应的位置为1,其他位置全为0,如果该词在词汇表中不出现,则词向量为全0;确定词向量的维数n。
47、步骤202包括:确定窗口大小window,对每个词生成2×window个训练样本;确定batch_size的大小为2×window的整数倍,以确保每个batch包含了一个词汇对应的所有样本,确定负样本数量,默认为5个,创建embedding矩阵和context矩阵,设置矩阵行数为词汇表的大小v,列数为词向量的维度n,并进行随机初始化。
48、步骤203包括:计算输入嵌入与每个上下文嵌入的点积,再用sigmoid函数生成[0,1]的输出。
49、步骤204包括:使用经多次迭代训练后的文本分割器,得到每个词语的词向量表示,从而获得整个故事文本对应的低维嵌入向量h0。
50、进一步地,本发明所提供的方法,步骤30中,文本编码器模块包括两层结构:第一层是gru单元,第二层是text2gist单元;文本编码器模块的处理过程为:
51、
52、ot,ht=text2gist(it,ht-1)
53、gru单元在第t时间步,将句子st,等距高斯噪声以及第t-1个gru记忆单元的值gt-1作为输入,并输出向量it和第t个gru记忆单元的值gt。
54、text2gist单元将向量it与故事语境向量ht作为输入,并输出ot;ot编码了在第t时间步生成图像需要的所有必要信息,ht初始值来为h0,由text2gist更新,以反映潜在的语境信息变化,gt的初始状态g0采样自等距高斯分布。
55、其中text2gist详细的更新过程为:
56、zt=σz(wzit+uzht-1+bz)
57、rt=σr(writ+urht-1+br
58、ht=(1-zt)⊙ht-1+zt⊙σh(whit+uh(rt⊙ht-1)+bh)
59、ot=filter(it)ht
60、filter(·)将向量it转换为多通道过滤器,σz、σr和σh是非线性sigmoid函数,w与u是权重参数,b是偏置参数。⊙表示矩阵乘积。
61、进一步地,本发明所提供的方法,其特征在于,步骤50中,变分自编码器包括编码器模块和解码器模块;编码器模块用于模型训练阶段,将全尺寸图像在低维潜在空间进行编码;解码器将输入的xt解码,将潜在空间的数据还原,输出全尺寸图像xt。
62、存储器,用于存储指令;以及
63、处理器,用于调用所述存储器存储的指令执行第一方面的方法。
64、根据本发明的第三方面,提供一种计算机可读存储介质,其特征在于,存储有指令,所述指令被处理器执行时,执行第一方面的方法。
65、与现有技术相比,本发明所构思的上述技术方案至少具有以下有益效果:
66、1、图像是根据文本信息实时生成的,而不是根据文本匹配图像库的中的图像,其多元性和可玩性大大增加。
67、2、大多数文生图工具只能根据一句简单文本prompt生成单张图片,如:一个穿红裙子的小女孩。本方法可根据多句文本,长段文本生成多张对应图片,如:一个穿红裙子的小女孩,开心地在捉蝴蝶,阳光洒在草地上非常美丽,她家的小狗开始呼唤她,原来是妈妈叫她回家吃饭了。模型可以根据以上信息中角色,动作,和场景的变化正确地断句并分别生成图片诠释故事。
68、3、conrtrolnet网络的增加,使人物动作,环境等生成可控性大大增加,保证了图像生成对特定对象的安全性。
69、4、扩散模型作为新的图像生成方案正在逐渐崭露头角,相比于传统的gan神经网络,它具有更好的稳定性和可控性,并且可以通过最小化凸回归损失来更加有效地解决gan训练中的鞍点问题。同时,其简单易懂的数学公式也让其在理论上更加具有优势。
70、本发明最终可使长文本自动生成相应的连续图像,在儿童故事生成儿童绘本的应用中,应用场景如:给一篇儿童故事自动生成相应儿童绘本图片,减轻插画师的工作;也可以实时进行交互,即兴讲述一个儿童故事,该模型可以在讲述的同时读入文本并生成文本相对应的图片辅助儿童理解。可选的扩展网络controlnet支持控制生成图像中人物动作,环境背景,图像色彩,图像边缘等,在生成儿童绘本时,其可控性大大增加。除此以外,本发明还可应用于剧本分镜头图像生成,短视频配音图像生成等领域。
71、应当理解的是,以上的一般描述和后文的细节描述仅是示例性和解释性的,并不能限制本发明。
- 还没有人留言评论。精彩留言会获得点赞!