差分隐私保护下基于联邦学习和多臂赌博机的商品推荐方法
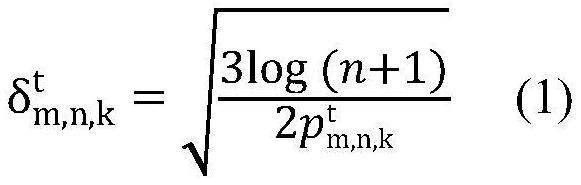
本发明属于推荐系统领域,具体的说是一种差分隐私保护下基于联邦学习和多臂赌博机的商品推荐方法。
背景技术:
1、身处大数据时代,数据量是否足够已然不是我们需要担心的问题,相比于此,数据的安全问题显然更需要我们的关注,越来越多的国家和地区都开始通过立法的方式来保护用户的隐私安全。同时,信息过载也是大数据时代的负面影响之一,而推荐系统则为了解决信息过载提供了可行的思路。通过获取用户的历史信息,推荐系统可以从中分析出用户的相关偏好,从而给用户推荐更加符合其偏好的商品,从而实现生产者与消费者的双赢。
2、然而,现有的推荐算法对用户信息的使用可能会导致严重的信息安全问题,用户的购买记录、浏览记录、收藏记录都属于用户敏感信息,在上传给第三方后,可能由于第三方不可信使得这些信息泄露,从而造成用户的财产损失、隐私侵犯、信用损害等后果。同时,推荐系统对用户信息过于依赖,在对新用户、新商品进行推荐时由于信息不够完善会导致冷启动问题,使得推荐效率低下。最后,在这个数据量爆炸的时代,使用集中式系统来进行计算已然不现实,因此,如何在不泄露用户敏感信息的情况下实现一个能解决冷启动问题的分布式推荐方法变得极其重要。
技术实现思路
1、本发明是为了解决上述场景下存在的问题,提出一种差分隐私保护下基于联邦学习和多臂赌博机的商品推荐方法,以期能有效解决现有场景下主流方案中用户敏感数据容易泄露的安全性问题、无法进行分布式计算的问题、以及现有推荐系统的冷启动问题,从而能更好的运用海量数据、保护用户的隐私信息、能提升商品推荐效率。
2、本发明为达到上述发明目的,采用如下技术方案:
3、本发明一种差分隐私保护下基于联邦学习和多臂赌博机的商品推荐方法的特点是应用于由一个中央服务器、m个客户端、一个候选商品集a={a1,a2,…,ak,…,ak}所构成的网络环境中,其中,ak表示第k个候选商品,k表示候选商品的总数,m为客户端的数量,所述商品推荐方法是按如下步骤进行:
4、步骤1、所述中央服务器及各个客户端初始化商品推荐的参数:
5、定义当前训练轮次为t,并初始化t=1;定义总训练轮次为t,训练步长为fp,且fp=10log(t),定义活跃候选商品集为a',并初始化a'=a;
6、步骤2、第t次迭代下各个客户端对a'中所有候选商品进行推荐并获得对应的奖励反馈向量:
7、步骤2.1、定义候选商品重复推荐的总次数为n,且n=min(t-t,fp);定义当前推荐次数为n,并初始化n=1;
8、定义第t次迭代下第k个候选商品ak第n次推荐给第m个客户端所获得的累计奖励反馈为rtm,n,k,并初始化rtm,n,k=0;
9、定义第t次迭代下第k个候选商品ak第n次推荐给第m个客户端的推荐次数为ptm,n,k,并初始化ptm,n,k=0;
10、定义并初始化参考奖励向量为r0m;
11、初始化参考推荐次数向量为p0m;
12、步骤2.2、初始化k=1;
13、步骤2.3、第t次迭代下将第k个候选商品ak第n次推荐给第m个客户端,并得到在第n次推荐下第m个客户端对第k个候选商品ak的评分δtm,n,k,将rtm,n,k+δtm,n,k赋值给rtm,n,k;将ptm,n,k+1赋值给ptm,n,k;
14、步骤2.4、k+1赋值给k后,返回步骤2.3顺序执行,直到k>k为止,从而得到第t次迭代下的第n次推荐时第m个客户端对a'中所有候选商品的累计评分向量
15、rtm,n={rtm,n,k|k=1,2,…,k}以及a'中所有候选商品推荐给第m个客户的推荐次数向量
16、ptm,n={ptm,n,k|k=1,2,…,k};
17、步骤3、第t次迭代下各个客户端从a'中选择局部最优的商品进行推荐并获得对应的奖励反馈:
18、步骤3.1、定义并初始化第t次迭代下第k个候选商品ak第n次推荐给第m个客户端时参考奖励的期望φtm,n,k=rtm,n,k/ptm,n,k,从而得到第t次迭代下所有候选商品第n次推荐给第m个客户端时参考奖励的期望向量φtm,n={φtm,n,k|k=1,2,…,k};
19、根据式(1)计算第t次迭代下第k个候选商品ak第n次推荐给第m个客户端的置信半径δtm,n,k:
20、
21、步骤3.2、定义第t次迭代下第k个候选商品ak第n次推荐给第m个客户端所获得的累计奖励反馈为r'tm,n,k,并初始化r'tm,n,k=0;
22、定义第t次迭代下第k个候选商品ak第n次推荐给第m个客户端的推荐次数为sm,n,k,并初始化sm,n,k=0;
23、步骤3.3、计算第t次迭代下第k个候选商品ak在第n次推荐给第m个客户端时的置信上界ltm,n,k=φtm,n,k+δtm,n,k;从而得到第t次迭代下所有候选商品在第n次推荐给第m个客户端时的置信上界ltm,n={ltm,n,k|k=1,2,…,k};
24、步骤3.4、从ltm,n中选择最大值所对应的候选商品并作为局部最优的商品am,max推荐给第m个客户端,并得到第t次迭代下第m个客户端对第n次推荐的最优商品am,max的评分δ'tm,n,max,将r'tm,n,max+δ'tm,n,max赋值给r'tm,n,max;并将sm,n,max+1赋值给sm,n,max;其中,r'tm,n,max表示第t次迭代下最优商品am,max第n次推荐给第m个客户端所获得的累计奖励反馈,sm,n,max表示第t次迭代下最优商品am,max第n次推荐给第m个客户端的推荐次数;max∈[1,k];
25、步骤3.5、根据r'tm,n,max得到第t次迭代下第m个客户端在第n次推荐时对所有候选商品的累计评分向量itm,n;根据sm,n,max得到第t次迭代下第m个客户端在第n次推荐时对所有候选商品的推荐次数向量stm,n;
26、步骤3.6、将(r0m+itm,n)/(p0m+stm,n)赋值给φtm,n;当n=1时,令r0m=rtm,n,p0m=ptm,n;
27、步骤3.7、将n+1赋值给n后,判断n>n是否成立,若成立,则表示得到第t次迭代下第n次推荐时第m个客户端的累计评分向量rtm,n并赋值给最终累计评分向量rtm,得到第t次迭代下第m个客户端在第n次推荐时对所有候选商品的累计评分向量itm,n并赋值给最终累计评分向量itm、得到第t次迭代下的第n次推荐时a'中所有候选商品推荐给第m个客户的推荐次数向量ptm,n并赋值给最终推荐次数向量ptm、得到第t次迭代下第m个客户端在第n次推荐时对所有候选商品的推荐次数向量stm,n并赋值给最终推次数向量stm,否则,返回步骤2.2顺序执行,
28、步骤4、利用式(2)计算第t次迭代下第m个客户端的推荐参数向量gtm={gtm,k|k=1,2,…,k}:
29、
30、式(2)中,β为权重参数;
31、步骤5、计算扰动后的推荐参数向量g'tm={g'tm,k|k=1,2,…,k}、最终推荐次数向量p'tm、s'tm并上传至中央服务器,其中,g'tm,k表示第t次迭代下第m个客户端对第k个商品ak的推荐参数;
32、步骤6、中央服务器对扰动后的参数向量进行处理:
33、步骤6.1、根据式(5)计算第t次迭代下所有客户端对所有候选商品的全局期望向量htglobal={htglobal,k|k=1,2,…,k},其中,htglobal,k表示第t次迭代下第k个商品ak的全局期望:
34、
35、步骤6.2、根据式(6)计算第t次迭代下中央服务器对所有候选商品的全局期望向量其中,表示第t次迭代下第k个商品ak的全局置信半径:
36、
37、式(6)中,σc为置信度参数;
38、步骤6.3、遍历每个候选商品的全局期望,当第k个候选商品ak的全局期望htglobal,k不满足式(7)时,将第k个候选商品ak加入第t次迭代下的淘汰集et,从而得到第t次迭代下最终的淘汰集et;
39、
40、步骤6.4、从活跃候选商品集a'中删除最终的淘汰商品集et中所包含的商品,从而得到更新后的活跃候选商品集a';
41、步骤7、判断活跃候选商品集a'中剩余的商品数量大于1是否成立,若成立,则将t+1赋值给t后,返回步骤2顺序执行,否则,直接选择活跃候选商品集a'中最终剩余的商品进行推荐。
42、本发明所述的商品推荐方法的特点也在于,所述步骤5包括:
43、步骤5.1、利用式(3)计算方差σ2:
44、σ2=2f2log(1.25/ρ)/ε2 (3)
45、式(2)中,ρ表示松驰项,ε表示隐私预算,f为敏感度;
46、步骤5.2、利用式(4)计算扰动后的推荐参数向量g'tm={g'tm,k|k=1,2,…,k}并上传至中央服务器;
47、
48、式(4)中,表示从中心为0且方差为σ2的高斯分布抽样;
49、步骤5.3、利用式(4)计算扰动后的最终推荐次数向量p'tm、s'tm并上传至中央服务器。
50、本发明一种电子设备,包括存储器以及处理器的特点在于,所述存储器用于存储支持处理器执行所述商品推荐方法的程序,所述处理器被配置为用于执行所述存储器中存储的程序。
51、本发明一种计算机可读存储介质,计算机可读存储介质上存储有计算机程序的特点在于,所述计算机程序被处理器运行时执行所述商品推荐方法的步骤。
52、与现有技术相比,本发明的有益效果在于:
53、1、相对于传统的商品推荐方法,本发明设置了全臂推荐和最优臂推荐两阶段来进行商品推荐,通过两阶段的推荐来提升本地商品推荐的准确性,然后通过加入高斯机制来保护商品推荐的参数,防止用户隐私数据泄露,最后采用商品淘汰机制来加速整个商品推荐的过程;通过使用差分隐私保护下基于联邦学习和多臂赌博机的商品推荐方法,解决了分布式场景下的商品推荐问题,所得到的商品推荐方案,不仅拥有更高的推荐效率,而且还保护了用户的敏感数据。
54、2、本发明的商品推荐数据聚合过程中,对于全臂推荐阶段和最优臂推荐两阶段维护了一个权重参数,来保证更有效的推荐数据在后续的商品推荐过程中发挥更重要的作用。这种方式既可以由推荐过程本身来相互学习商品背后所服从的分布情况,也可以由经验参数来加速整个推荐过程,从而提升了商品推荐的效果。
55、3、本发明的中央服务器基于淘汰机制,通过确立淘汰商品集,来解决次优商品被大量重复推荐的问题,这样可以节省推荐的时间和通信成本,从而保证了推荐效率。
- 还没有人留言评论。精彩留言会获得点赞!