一种多模态人机交互系统的制作方法
本发明涉及人机交互,具体为一种多模态人机交互系统。
背景技术:
1、传统的人机交互系统通常基于单一的输入方式,如语音或键盘输入,缺少多模态输入的优势。在传统系统中,语音识别或文本输入是主要的用户交互方式,通过将用户的语音转换成文本来解析用户的意图和需求,然而,这种系统存在一定的局限性和劣势。
2、首先,单一输入方式可能无法全面地捕捉用户的目标和意图。例如,在一些情境中,用户可能同时使用手势或肢体动作来表达自己的需求或意图,单纯依靠语音输入则无法感知到这些信息。这限制了系统对用户意图的准确理解。
3、其次,传统系统在处理输入的准确性和效率方面可能存在一些问题。语音识别算法可能受到背景噪声或语音口音的影响而产生错误的识别结果,从而导致系统误解用户的意图。此外,文本输入可能存在输入错误或不清楚的情况,需要用户进行更正或澄清,增加了用户和系统之间的交互成本。
4、另外,传统系统在结果的可靠性和准确性方面存在一定风险。由于单一输入方式的限制,系统很难确定正确的用户意图,容易导致误解和错误的反应。系统无法进行结果的多角度验证和确认,存在误差传递的风险,可能产生误导性的结果。
5、综上所述,传统的人机交互系统在单一输入方式、准确性和效率、结果可靠性等方面存在一定的劣势。
技术实现思路
1、本发明的目的在于提供一种多模态人机交互系统,以解决上述背景技术中提出的问题。
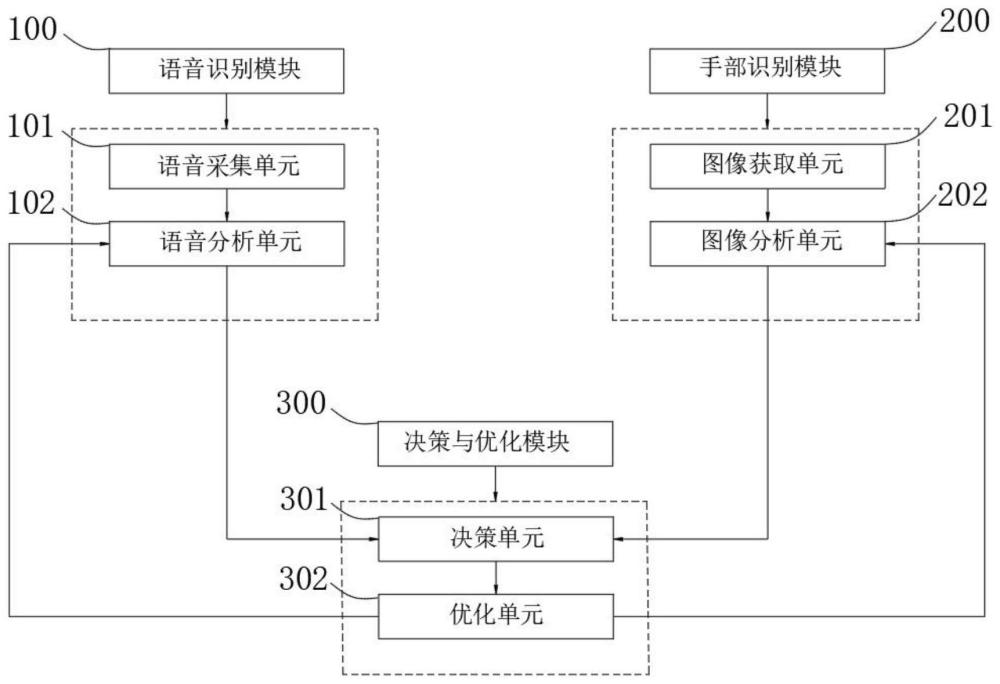
2、为实现上述目的,本发明提供如下技术方案:一种多模态人机交互系统,其包括语音识别模块、手势识别模块和决策与优化模块,其中:
3、所述语音识别模块用于收集语音数据并进行特征提取,利用长短时记忆网络模型对特征提取后的语音数据进行文本结果和置信度的预测,其中长短时记忆网络模型的建立包括历史语音数据进行的收集;所述手势识别模块用于收集用户视频数据,视频数据包含用户的手势和肢体动作,利用卷积神经网络模型对用户视频数据进行文本结果和置信度的预测,其中卷积神经网络模型的建立包括历史视频数据的收集;
4、所述决策与优化模块对语音识别模块和手势识别模块中的文本结果进行比对,文本结果比对一致,确定文本结果为最终结果;
5、文本结果比对不一致时,决策与优化模块对语音识别模块中的历史语音数据和手势识别模块中的历史视频数据进行数据增强,提高模型预测的置信度,并将语音识别模块和手势识别模块中的置信度进行比对,根据置信度高低选择对应的文本结果作为最终结果,其中,置信度相等,决策与优化模块对语音识别模块中的长短时记忆网络算法进行优化,运用参数剪枝的方法减少模型的大小和计算量,决策与优化模块对手势识别模块中的卷积神经网络进行优化,运用批量归一化提高模型的训练速度和准确性,优化完成再次进行结果比对,不停迭代,直到确定最终结果。
6、作为本技术方案的进一步改进,所述语音识别模块包括语音采集单元和语音分析单元,所述语音采集单元利用麦克风收集语音数据,并通过模数转换器将模拟信号转化为数字信号数据发送给语音分析单元;所述语音分析单元对语音数字数据进行数据预处理、特征提取并利用长短时记忆网络模型进行文本结果和置信度的预测,将预测结果发送给决策与优化模块。
7、作为本技术方案的进一步改进,所述手势识别模块包括图像获取单元和图像分析单元,所述图像获取单元利用摄像头收集视频流数据,视频流数据包含用户的手势和肢体动作,并对视频流数据中的图片帧进行图像处理,将处理好的图片数据发送给图像分析单元;所述图像分析单元利用卷积神经网络模型对图片数据进行文本结果和置信度的预测,将预测结果发送给决策与优化模块。
8、作为本技术方案的进一步改进,所述决策与优化模块包括决策单元和优化单元,所述决策单元接收语音分析单元和图像分析单元发送的文本结果和置信度,根据文本结果是否一致和置信度的高低,确定最终结果;所述优化单元对语音分析单元和图像分析单元中的算法模型进行优化处理。
9、作为本技术方案的进一步改进,所述语音分析单元对语音数据进行特征提取,具体包括:
10、将语音信号进行时域分析,将其划分为小的时间窗口,对每个时间窗口内的语音信号进行傅里叶变换,得到语音信号在频域上的频谱分布,在频谱上应用梅尔滤波器组来模拟人耳的感知特性,将连续频率范围划分为一系列梅尔带,每个梅尔带对应一个滤波器系数,用于测量该带内频率的能量,对于每个梅尔带内的能量,采用对数变换,得到梅尔频谱系数,通过进行离散余弦变换,提取主要频率成分,得到最终的梅尔频率倒谱系数作为语音特征。
11、作为本技术方案的进一步改进,所述图像分析单元利用卷积神经网络模型对图片数据进行文本结果和置信度的预测,具体包括:
12、使用带有手动标记的手势视频数据来训练卷积神经网络,通过对网络进行反向传播和梯度下降,网络参数逐渐调整以最大化正确分类手势的概率;
13、卷积神经网络的输入是经过预处理的图像帧,图像帧包括灰度图;
14、卷积层通过使用多个卷积核对输入图像进行卷积操作,提取图像中的局部特征,每个卷积核检测图像中的不同特征,包括边缘和纹理;
15、在卷积层之后,使用一个激活函数对卷积结果进行非线性映射,增强网络的非线性建模能力;
16、池化层用于降低特征图的维度,并提取出具有鲁棒性的特征,通过取每个池化窗口中的最大值来减少特征图的大小;
17、在卷积和池化层之后,通过全连接层进一步抽取和组合特征,全连接层将特征映射到特定类别的概率上;
18、输出层采用softmax激活函数,将网络的输出映射为每个类别的概率分布,对于手势识别任务,每个类别代表一个特定的手势动作。
19、作为本技术方案的进一步改进,所述决策单元接收语音分析单元和图像分析单元发送的文本结果和置信度,根据文本结果是否一致和置信度的高低,确定最终结果,具体包括:
20、文本结果比对一致,确定文本结果为最终结果;文本结果比对不一致,将语音分析单元和图像分析单元中的置信度进行比对,语音分析单元的置信度高于图像分析单元的置信度,决策单元选择语音分析单元的输出结果作为最终的决策;图像分析单元的置信度高于语音分析单元的置信度,决策单元选择图像分析单元的输出结果作为最终的决策。
21、作为本技术方案的进一步改进,所述优化单元对语音分析单元和图像分析单元中的算法模型进行优化处理,具体包括:
22、优化单元对语音分析单元中的长短时记忆网络算法模型进行优化处理,运用参数剪枝的方法来减少模型的大小和计算量,同时提高模型的推理速度,通过获得长短时记忆模型中的参数,设定一个阈值来评估模型中每个参数的重要性,并将重要性较低的参数剪枝掉,剪枝后的模型将拥有更少的参数,对剪枝后的模型进行重新训练,使其恢复性能,并确保其在测试数据上保持较高的准确性;
23、优化单元对语音分析单元运用批量归一化来提高模型的训练速度和准确性,通过在每一层的激活函数前,添加批量归一化层,并重新进行模型的训练,在训练过程中,对每个批量的输入数据进行归一化处理,将数据的均值调整为0,方差调整为1,归一化后的数据经过一个可学习的缩放因子和偏移项,以恢复数据的原始范围和偏移,在反向传播过程中,通过计算梯度并根据梯度更新缩放因子和偏移项的参数,使得模型根据数据的统计信息自适应地调整输入的规模和偏移,以进行优化处理。
24、作为本技术方案的进一步改进,所述决策与优化模块对语音识别模块中的历史语音数据和手势识别模块中的历史视频数据进行数据增强,提高模型预测的置信度,具体包括:
25、对语音数据进行增强:通过向语音数据添加不同类型和强度的噪声,适应各种嘈杂环境;通过变化语音的语速,增加或减慢语音的讲话速度,用于模拟用户不同的语速并增加语音模型的稳健性;对语音进行音调变化,模拟说话者不同的音高特点,用于提高语音识别的泛化能力;
26、对手势视频数据进行增强:从不同角度捕捉手势动作,包括旋转、翻转和缩放变换,用于增加模型对用户手势动作的鲁棒性,提高模型在多种视角下的准确性;在视频中添加不同类型的背景,用于模拟真实场景中的背景变化,增加模型对不同背景的适应能力。
27、与现有技术相比,本发明的有益效果是:
28、1、该一种多模态人机交互系统收集语音数据并进行特征提取,利用长短时记忆网络模型对特征提取后的语音数据进行文本结果和置信度的预测,收集用户视频数据,视频数据包含用户的手势和肢体动作,利用卷积神经网络对用户视频数据进行文本结果和置信度的预测,比对来自语音和手势识别的结果,从而提高指令的准确性,并在结果不一致的情况下,通过比对置信度来决策最终结果,保证结果的准确性,从而显著提升了系统对指令的正确响应率。
29、2、该多模态人机交互系统在进行文本结果和置信度结果的比对之后,若都不能确定最终结果,则对语音识别模块和手势识别模块中的算法模型进行优化,对语音识别模块中的长短时记忆网络算法运用参数剪枝的方法减少模型的大小和计算量,对手势识别模块中的卷积神经网络运用批量归一化提高模型的训练速度和准确性,优化完成再次进行结果比对,不停迭代,直到确定最终结果,这种在运行中自我修正和优化的能力,使得系统在实际使用中不断自我提升。
- 还没有人留言评论。精彩留言会获得点赞!