基于AIGC的图像描述文本的生成方法及装置、存储介质与流程
本技术涉及计算机视觉和自然语言处理,尤其是涉及到一种基于aigc的图像描述文本的生成方法及装置、存储介质、计算机设备。
背景技术:
1、随着计算机技术尤其是图像处理技术的发展,以图像为载体的信息传递方式占越来越多的比重。在一些场景下,如电商场景中,利用商品的图像与商品的自然语言描述共同对商品进行介绍,可以使得买家更加直接地了解该商品。
2、图像中包括丰富的视觉信息,目前基于该视觉信息可以生成自然语言描述。但是,现有技术中,在根据视觉信息生成自然语言描述时,生成的描述内容往往完全取决于图像中包含的元素,使得描述内容与图像元素完全匹配,无法满足用户的个性化需求。因此,亟需一种图像描述生成方法,使得生成的自然语言描述可以满足用户的个性化需求,以提高用户的满意度。
技术实现思路
1、有鉴于此,本技术提供了一种基于aigc的图像描述文本的生成方法及装置、存储介质、计算机设备,通过目标用户参与待描述图像的标签总集中标签的筛选,可以使得最终生成的描述文本在具备可控性的同时符合目标用户的需求,有利于提升目标用户的满意度。
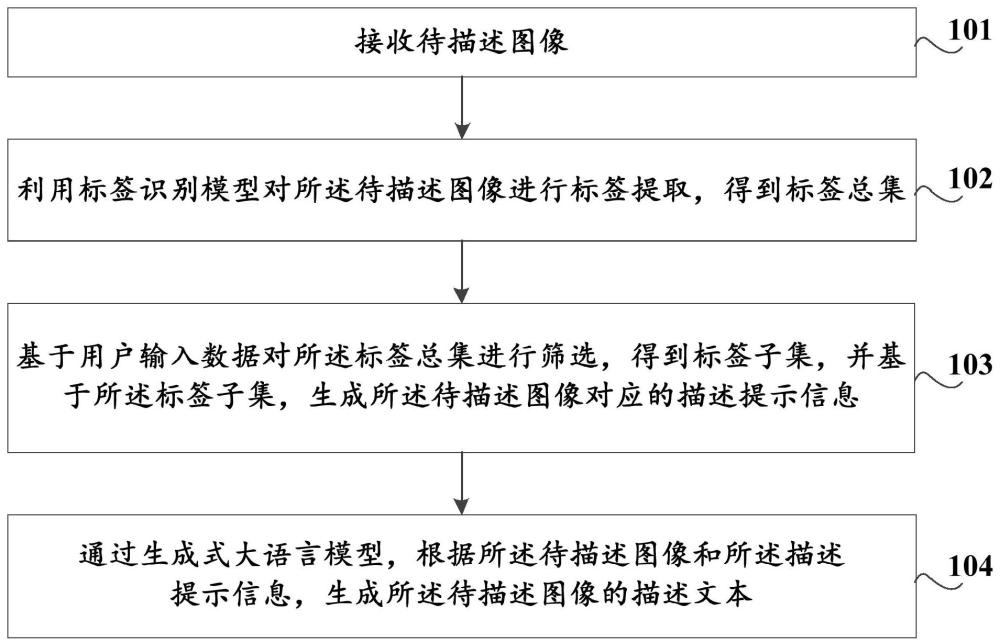
2、根据本技术的一个方面,提供了一种基于aigc的图像描述文本的生成方法,包括:
3、接收待描述图像;
4、利用标签识别模型对所述待描述图像进行标签提取,得到标签总集;
5、基于用户输入数据对所述标签总集进行筛选,得到标签子集,并基于所述标签子集,生成所述待描述图像对应的描述提示信息;
6、通过生成式大语言模型,根据所述待描述图像和所述描述提示信息,生成所述待描述图像的描述文本。
7、可选地,所述基于用户输入数据对所述标签总集进行筛选之前,所述方法还包括:
8、获取针对所述待描述图像设置的描述关键词,并将所述描述关键词作为所述用户输入数据;和/或,
9、获取目标用户对所述标签总集中任意标签的选择操作数据,并将所述选择操作数据作为所述用户输入数据。
10、可选地,所述基于所述标签子集,生成所述待描述图像对应的描述提示信息,包括:
11、将所述标签子集填入描述提示模板,得到描述提示信息,其中,所述描述提示模板包括待填充部分以及说明部分,所述描述提示模板用于指示基于所述说明部分生成对所述待填充部分的描述文本。
12、可选地,在所述用户输入数据包含所述描述关键词的情况下,所述将所述标签子集填入描述提示模板,得到描述提示信息,包括:
13、将所述描述关键词与所述标签子集进行比对,识别所述描述关键词中是否包含不属于所述标签子集的描述关键词;
14、若包含,则将所述标签子集填入描述提示模板,得到初始描述提示信息,并根据不属于所述标签子集的描述关键词和所述初始描述提示信息,生成所述描述提示信息;
15、若不包含,则将所述标签子集填入描述提示模板,得到所述描述提示信息。
16、可选地,所述将所述标签子集填入描述提示模板之前,所述方法还包括:
17、在所述用户输入数据包含所述描述关键词的情况下,解析所述描述关键词,得到待描述对象和/或待描述场景,并基于所述待描述对象和/或待描述场景,从预设模板集合中确定匹配的问题模板作为所述描述提示模板;或者,
18、接收所述目标用户对预设模板集合中任一问题模板的选择指令,将所述选择指令对应的问题模板作为所述描述提示模板。
19、可选地,所述通过生成式大语言模型,根据所述待描述图像和所述描述提示信息,生成所述待描述图像的描述文本之前,所述方法还包括:
20、将所述描述提示信息以及所述待描述图像输入至提示信息生成模型,通过所述提示信息生成模型提取所述标签子集对应的注意力图,生成所述注意力图的提示描述,从所述提示描述中提取候选答案,生成所述候选答案的提示问题,根据所述候选答案和所述提示问题生成提示问答对;
21、相应地,所述通过生成式大语言模型,根据所述待描述图像和所述描述提示信息,生成所述待描述图像的描述文本,包括:
22、通过生成式大语言模型,根据所述提示描述、所述提示问答对和所述描述提示信息,生成所述待描述图像的描述文本。
23、可选地,所述描述关键词包括描述对象关键词、描述场景关键词、以及描述风格关键词中至少一种;所述描述对象关键词的类型包括菜品名称、菜品口味、菜品特色以及菜品菜系中的至少一种;所述描述场景关键词包括菜品评论、菜品发布以及菜品升级中的至少一种。
24、可选地,所述接收待描述图像之前,所述方法还包括:
25、获取训练样本集合,其中,所述训练样本集合中包括多个训练样本对,每个所述训练样本对中包括菜品图像样本,以及描述所述菜品图像样本的菜品文本样本;
26、利用文本语义解析器对任一训练样本对中的菜品文本样本进行解析,得到目标对象,并利用所述目标对象对所述任一训练样本对中的菜品图像样本进行标记,其中,所述目标对象包括菜品实体;
27、通过标记后的菜品图像样本对初始识别模型进行训练,得到所述标签识别模型。
28、根据本技术的另一方面,提供了一种基于aigc的图像描述文本的生成装置,包括:
29、图像接收模块,用于接收待描述图像;
30、标签提取模块,用于利用标签识别模型对所述待描述图像进行标签提取,得到标签总集;
31、标签筛选模块,用于基于用户输入数据对所述标签总集进行筛选,得到标签子集,并基于所述标签子集,生成所述待描述图像对应的描述提示信息;
32、文本生成模块,用于通过生成式大语言模型,根据所述待描述图像和所述描述提示信息,生成所述待描述图像的描述文本。
33、可选地,所述装置还包括:
34、用户输入数据确定模块,用于所述基于用户输入数据对所述标签总集进行筛选之前,获取针对所述待描述图像设置的描述关键词,并将所述描述关键词作为所述用户输入数据;和/或,获取目标用户对所述标签总集中任意标签的选择操作数据,并将所述选择操作数据作为所述用户输入数据。
35、可选地,所述标签筛选模块,还用于:
36、将所述标签子集填入描述提示模板,得到描述提示信息,其中,所述描述提示模板包括待填充部分以及说明部分,所述描述提示模板用于指示基于所述说明部分生成对所述待填充部分的描述文本。
37、可选地,在所述用户输入数据包含所述描述关键词的情况下,所述标签筛选模块,还用于:
38、将所述描述关键词与所述标签子集进行比对,识别所述描述关键词中是否包含不属于所述标签子集的描述关键词;
39、若包含,则将所述标签子集填入描述提示模板,得到初始描述提示信息,并根据不属于所述标签子集的描述关键词和所述初始描述提示信息,生成所述描述提示信息;
40、若不包含,则将所述标签子集填入描述提示模板,得到所述描述提示信息。
41、可选地,所述装置还包括:
42、模板确定模块,用于所述将所述标签子集填入描述提示模板之前,在所述用户输入数据包含所述描述关键词的情况下,解析所述描述关键词,得到待描述对象和/或待描述场景,并基于所述待描述对象和/或待描述场景,从预设模板集合中确定匹配的问题模板作为所述描述提示模板;或者,接收所述目标用户对预设模板集合中任一问题模板的选择指令,将所述选择指令对应的问题模板作为所述描述提示模板。
43、可选地,所述装置还包括:
44、提示信息生成模块,用于所述通过生成式大语言模型,根据所述待描述图像和所述描述提示信息,生成所述待描述图像的描述文本之前,将所述描述提示信息以及所述待描述图像输入至提示信息生成模型,通过所述提示信息生成模型提取所述标签子集对应的注意力图,生成所述注意力图的提示描述,从所述提示描述中提取候选答案,生成所述候选答案的提示问题,根据所述候选答案和所述提示问题生成提示问答对;
45、相应地,所述文本生成模块,还用于:
46、通过生成式大语言模型,根据所述提示描述、所述提示问答对和所述描述提示信息,生成所述待描述图像的描述文本。
47、可选地,所述描述关键词包括描述对象关键词、描述场景关键词、以及描述风格关键词中至少一种;所述描述对象关键词的类型包括菜品名称、菜品口味、菜品特色以及菜品菜系中的至少一种;所述描述场景关键词包括菜品评论、菜品发布以及菜品升级中的至少一种。
48、可选地,所述装置还包括:
49、样本集合获取模块,用于所述接收待描述图像之前,获取训练样本集合,其中,所述训练样本集合中包括多个训练样本对,每个所述训练样本对中包括菜品图像样本,以及描述所述菜品图像样本的菜品文本样本;
50、样本解析模块,用于利用文本语义解析器对任一训练样本对中的菜品文本样本进行解析,得到目标对象,并利用所述目标对象对所述任一训练样本对中的菜品图像样本进行标记,其中,所述目标对象包括菜品实体;
51、模型训练模块,用于通过标记后的菜品图像样本对初始识别模型进行训练,得到所述标签识别模型。
52、依据本技术又一个方面,提供了一种存储介质,其上存储有计算机程序,所述程序被处理器执行时实现上述基于aigc的图像描述文本的生成方法。
53、依据本技术再一个方面,提供了一种计算机设备,包括存储介质、处理器及存储在存储介质上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现上述基于aigc的图像描述文本的生成方法。
54、借由上述技术方案,本技术提供的一种基于aigc的图像描述文本的生成方法及装置、存储介质、计算机设备,接收到待描述图像之后,可以进一步从待描述图像中提取出全部标签组成标签总集,之后,可以根据用户输入数据对标签总集中包含的标签进一步筛选,得到标签子集,接着利用标签子集生成待描述图像对应的描述提示信息,最终生成式大语言模型根据描述提示信息生成描述文本。本技术实施例通过利用目标用户筛选后的标签子集生成描述提示信息,进而利用该描述提示信息生成待描述图像的描述文本,相比于传统技术中根据图像直接生成描述文本的方式,解决了描述文本生成的可控性较差的问题,本技术实施例通过目标用户参与待描述图像的标签总集中标签的筛选,可以使得最终生成的描述文本在具备可控性的同时符合目标用户的需求,有利于提升目标用户的满意度。
55、上述说明仅是本技术技术方案的概述,为了能够更清楚了解本技术的技术手段,而可依照说明书的内容予以实施,并且为了让本技术的上述和其它目的、特征和优点能够更明显易懂,以下特举本技术的具体实施方式。
- 还没有人留言评论。精彩留言会获得点赞!