一种眼底图像分类方法
本发明涉及深度学习和图像处理领域,尤其是涉及一种眼底图像分类方法。
背景技术:
1、眼底成像作为一种有效和经济的工具,在眼科筛查视网膜疾病和监测疾病进展方面被普遍利用。与眼科医生当面检查相比,视网膜摄影具有较高的敏感性、特异性和检查间/检查内的一致性。因此,在许多临床情况下,视网膜照片可以代替眼底镜检查。光学眼底成像技术的进步使其在即便没有瞳孔扩张的情况下也更容易获得高质量的视网膜图像。眼底照相机有几个优点,它们对患者来说是很方便的,因为只需要泛光灯的单次闪光曝光。此外,它们在不同的情况下不会影响图像质量,如在白内障病例中的退化减少。总的来说,数字视网膜摄影可以促进远程医疗咨询,这提供了更多获得准确和及时的亚专业护理的机会,特别是对于医疗服务不足的地区。因而,利用计算机技术辅助眼底诊断,进行眼底健康筛查十分必要。
2、深度学习(dl)现已成为计算机视觉的主流技术。它在开发新的医学图像处理算法以支持疾病检测和诊断方面扮演者重要的角色。利用深度学习技术进行眼底图像分类的研究方法可以从广义上分为两种,即利用全局信息进行分析和基于局部病灶。在这些方法中,一些研究通过对整个眼底图像进行特征提取,随后进行分类的方法已经取得了很多成果。例如,研究人员在糖尿病视网膜眼底的诊断上尝试利用inception-v3结构进行深度学习技术的应用,对数据集eyepacs-1和messidor进行了验证。在eyepacs-1数据集上,其auc结果为0.991。同时,muhammad等人也设计一种深度学习方法,该方法将alexnet网络与随机森林方法混合,用于青光眼的诊断,并获得63.7%至93.1%之间的模型精度范围。
3、除了全局信息分析,局部病灶分析也是一种较为常见的方法。这种方法的主要流程是先使用定位算法检测眼底图像中的病变区域,然后根据病变的类型或数量等信息进行分类,最终得到分类结果。2015年,haloi等人提出一种利用卷积神经网络判断每个像素的类别属性的眼底微动脉瘤检测方法,用于早期糖尿病视网膜病变中眼底微动脉瘤的检测。在2017年,bogunovic等研究人员使用oct图像来检测与年龄相关的黄斑病变,通过定位算法得到病变区域,再利用卷积神经网络对病变区域进行识别和分类。
4、还有一些研究探索不同深度学习方法的融合以提高诊断的精度。例如,felix等研究人员设计一种模型,采用神经网络和随机森林相结合的方法,对年龄相关性黄斑病变进行12个等级的分类。该模型使用alexnet、vgg、googlenet等多个网络进行训练,并综合参考这些模型的结果,采用随机森林方法进行诊断。最终,该算法检测到84.2%的图像中存在明确的早期或晚期年龄相关性黄斑病变。
5、中国专利cn202110274127.2公开一种基于深度学习的眼底图像识别分类方法,解决现有深度学习方法进行眼底图像识别存在着准确度与速度之间的矛盾制约,效率较低,且原始数据少,给训练精度带来极大的影响等问题。该方法包括:步骤1,将眼底图像数据集进行数据增强后分为初始训练集a和验证集c,对训练集a进行数据扩充得到相对改变性质较小的训练集b1和相对改变性质较大的训练集b2;步骤2,分别将三个有映射关系的训练集a、b1、b2输入到不同的神经网络,其中将训练集b1的训练的卷积基复用到训练集b2,再通过密集连接分类器生成分类标签;步骤3,以图像改变性质的大小通过验证集c验证赋以不同的权重,融合使用优化算法达到最终结果。
6、发明目的
7、本发明的目的在于针对现有技术存在的由于数据收集和注释的成本较高而图像数量有限造成的模型准确度低、泛化能力低的问题,提供一种眼底病变图像分类方法,利用深度学习技术对odir-2019数据集进行分类。
8、本发明所述一种眼底病变图像分类方法,包括以下步骤:
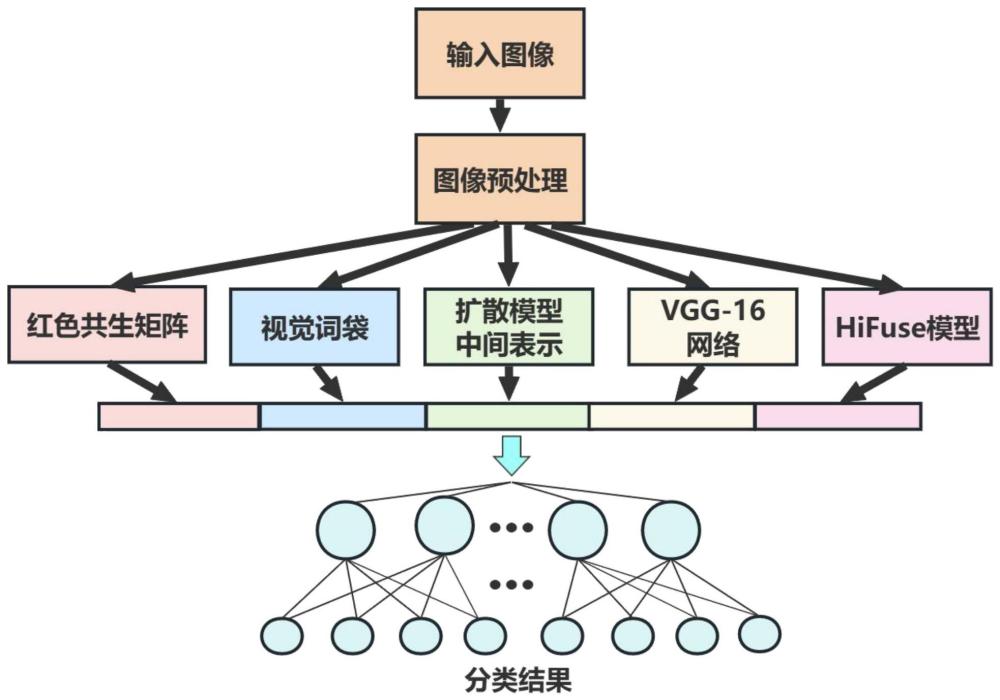
9、1)获取已有的眼底图像数据集并进行数据转换、图像预处理和数据的增广处理,得到预处理数据集;
10、在步骤1)中,所述数据集采用2019年北京大学“智慧之眼”国际眼底图像智能识别竞赛(peking university international competition on ocular diseaseintelligent recognition,odir-2019)开源的训练集;原始数据来自合作医院及医疗机构进行眼健康检查的患者,该训练集共包括3500组信息,每一组分别包含左眼和右眼的相关信息,以下简称该数据集为odir数据集,该数据集包含标签信息和眼底视网膜图像两部分;
11、所述数据转换针对odir数据集标签信息表中的“left-diagnostic keywords”和“right-diagnostic keywords”列进行统计,得出所有关键字集合;然后分别针对左眼和右眼提取并生成相应的疾病类别标签,即单眼级别的标签;
12、所述图像预处理,针对odir数据集中图像的大小不一致、亮度不均匀等问题,先将每张图像采样至512×512像素尺寸大小,再进行一系列的预处理,以提高图像质量、增强图像特征,图像预处理的具体步骤包括:
13、(1)标准化处理:眼底图像中像素值的范围可能会因为不同的采集设备或者参数设置而有所不同,这会对后续的图像分析和处理造成影响;标准化处理可以将图像中的像素值缩放到统一的范围内,使得不同图像之间的像素值具有可比性,从而更好地进行数据分析或者机器学习;
14、
15、
16、(2)clahe直方图均衡:眼底图像中可能存在大量的低对比度区域和细节模糊的区域,clahe直方图均衡化可以增强图像的对比度和细节,使图像更加清晰,从而更容易进行图像分析和特征提取;
17、(3)gamma校正:眼底图像中的亮度和对比度可能会受到拍摄环境、采集设备等因素的影响,这也会影响图像的可视化和特征提取;gamma校正可以调整图像的亮度和对比度,使得图像更加鲜明、清晰,从而更容易进行图像分析和特征提取;
18、
19、(4)高斯平滑处理:眼底图像中可能存在的一些噪声信息会对后续的图像分析和处理造成影响;使用高斯平滑处理可以去除一些噪声,使得图像更加平滑,从而更容易进行图像分析和特征提取;
20、iweight=iγ×α+iblur×β+γ
21、iblur=iγ×kernalh×w
22、所述数据的增广处理,用于扩充训练集、防止网络过拟合以及提高网络模型的泛化能力,对数据随机进行如如下增广处理操作:
23、(1)随机旋转(random rotation):该方法将图像旋转一个随机角度,以产生不同的图像变换增加数据的多样性,从而帮助模型学习到图像不同角度的特征;
24、(2)随机缩放裁剪(random resized crop):该方法随机从原始图像中裁剪出一块子图像,并将其缩放到指定的大小;
25、(3)随机水平/垂直翻转(random horizontal/vertical flip):该方法会随机将图像水平或垂直翻转,并将其作为新的训练样本;
26、2)提取图像特征并进行融合:
27、(1)红色共生矩阵:灰度共生矩阵(gldm)的统计方法是20世纪70年代初由r.haralick等人提出的,它是在假定图像中各像素间的空间分布关系包含了图像纹理信息的前提下,提出的具有广泛性的纹理分析方法;灰度共生矩阵被定义为从灰度为i的像素点出发,离开某个固定位置的点上灰度值为的概率,即所有估计的值可以表示成一个矩阵的形式,以此被称为灰度共生矩阵;由于眼底图像主要包含红色,因此通过红色共生矩阵可以获得更多的图像信息;读取图片并转为rgb格式,将图像的红色通道r的值作为相关特性;取图像(n×n)中任意一点(x,y)及偏离它的另一点(x+a,y+b),设该点对的r值为(r1,r2);共生矩阵中每个元素的值可以理解为(x,y)点与(x+a,y+b)点的值对为(i,j)的概率;对于整个画面,统计出每一种(r1,r2)值出现的次数,然后排列成一个方阵,在用(r1,r2)出现的总次数将它们归一化为出现的概率p(r1,r2);通过基于四个方向(水平、垂直、对角线、反对角线)的红色共生矩阵,从而得到眼底图像的纹理特征统计量r;
28、r=(r1,r2,…,rm)
29、(2)视觉词袋:bag-of-words模型是信息检索领域常用的文档表示方法;在信息检索中,bow模型假定对于一个文档,忽略它的单词顺序和语法、句法等要素,将其仅仅看作是若干个词汇的集合,文档中每个单词的出现都是独立的,不依赖于其它单词是否出现;也就是说,文档中任意一个位置出现的任何单词,都不受该文档语意影响而独立选择的;视觉词袋则是利用在图像中的关键点,即包含有关图像的丰富局部信息的部分;将关键点分组到大量聚类中,并将具有相似描述符的关键点分配到同一聚类中;通过将每个聚类视为一个“视觉词”,代表该聚类中的关键点共享的特定局部模式,有一个描述各种此类局部图像模式的视觉词词汇表;通过将图像的关键点映射到视觉词中,可以将图像表示为视觉词袋;采用尺度无关特征变换方法(scale-invariantfeaturetransform,sift)进行特征提取,从不同类别的图像中提取视觉词汇向量,这些向量代表的是图像中局部不变的特征点;将所有特征点向量集合到一块,利用k-means算法合并词义相近的视觉词汇,构造一个包含k个词汇的单词表;在关键点特征数据集x={x1,x2,..,xi,..,xn}中找到k个簇的聚类中心{c1,c2,..,cj,..,ck}使得各个簇中样本向量到对应簇聚类中心的欧式距离最小;公式如下:
30、
31、图像中sift关键点特征分别与k个聚类中心(即为视觉单词)进行距离计算,哪一个视觉单词距离最小,就将sift关键点特征分配给该视觉单词;最终得到的集合就是视觉词典,表示如下:
32、d=(d1,d2,…,dk)
33、随后,统计单词表中每个单词在图像中出现的次数,从而将图像表示成为一个k维数值向量,即生成该图像的视觉单词包;
34、h=(h1,h2,…,hk)
35、(3)扩散模型的中间特征表示;扩散模型首先定义了一个前向噪声过程,将逐步高斯噪声迭代添加到图像x0中,从数据分布q(x0)中采样,以t步得到一个完全噪声的图像xt;这个正向过程是一个具有值x1,x2,…,xt,…,xt-1,xt的马尔可夫链,它代表不同程度的噪声图像,定义如下:
36、
37、
38、其中,为方差设定,n为正态分布;根据以下公式,可在扩散步骤t时直接从真实图像x0中采样噪声图像xt:
39、
40、αt:=1-βt
41、
42、逆向扩散过程旨在从后验分布q(xt|xt-1)中反转正向过程和采样,该分布取决于整个数据分布;迭代地这样做可以对一个完全有噪声的图像xt进行降噪,这样就可以从数据分布q(x0)中采样;这通常使用神经网络∈θ近似为如下表达:
43、
44、当p和q作为vae时,变分下界目标的简化版本只是一个均方误差损失;这可用于训练∈θ,该∈θ学习将高斯噪声近似∈添加到真实图像x0中:
45、
46、使用引导扩散(guided diffusion,gd)实现,使用u-net式架构,其中具有残差块,将残差块、残差加注意力块和下采样或上采样残差块中的每一个都视为单独的块,并将它们编号为b∈{1,2,...,37},用于预训练好的无条件引导扩散模型;用扩散步骤t和模型块数b进行参数化,得到噪声图像xt和用块号b之后的激活作为特征向量的f(x0,t,θ);
47、f(x0,t,θ)=(f1,f1,…,fn)
48、将三个特征进行线性拼接,形成融合后的特征,各特征向量在融合时所占的权值相等,即:
49、t=(r1,r2,…,rm,h1,h2,…,hk,f1,f1,…,fn)
50、3)构建包含注意力机制以及特征融合机制的hifuse网络;将预处理数据集通过vgg-16网络和hifuse模型分别进行特征提取,并与步骤2)中的特征进行融合,采用softmax层进行分类,得到眼底病变图像分类结果;
51、(1)使用去除全连接层的vgg-16作为主干网,利用vgg-16网络中的中间特征映射(pool-3和pool-4)推断注意力图;在计算注意力图时,pool-5的输出作为一种“全局特征(global guidance)”(标记为g),最后阶段的特征包含着整个图像中最压缩和抽象化的信息;使用f=(f1,f2,...,fn)表示中间层的特征,其中fi代表第i个块的输出;
52、f和g同时作为注意力模块的输入,计算产生一个一通道的输出r,其中代表卷积运算,wf和wg由256个卷积核组成,卷积核w输出为一个通道大小,up(·)是双线性插值函数,用于统一输出空间的大小;
53、
54、最终的注意力图a是由r归一化得到;
55、a=sigmoid(r)
56、a中的每个元素ai∈a表示对应空间特征向量的关注程度,添加注意力分数后的特征向量由a和f做点积得到;最后,将vgg-16第3、4块的输出以及g做拼接作为提取的特征v;
57、v=(v1,v2,…,vs)
58、(2)hifuse模型用于获得不同尺度的局部空间信息和全局语义表示;在hifuse模型中使用一个并行的结构从全局和局部特征块中提取医学图像的全局和局部信息,并通过“h”型结构融合不同层次的特征;通过hff块融合不同层次的特征,然后经过下采样步骤,得到提取的特征fi;
59、将步骤2)、vgg-16网络以及hifuse模型提取的特征进行线性拼接,即:
60、features=(t1,t2,…,tm,v1,v2,…,vs,fi1,fi2,…,fik)
61、将features输入到softmax分类层,最后得到眼底病变图像分类结果。
62、与现有技术相比,本发明具有以下突出的技术效果:
63、(1)本发明在对眼底图像预处理阶段,探索出一种能够较为清晰的提取出眼底图像特征的图像预处理方法,为后续的模型训练提供重要的帮助。
64、(2)本发明同时实现“迁移学习网络模型”、“注意力机制网络模型”和“注意力机制+特征融合机制网络模型”,将注意力机制和特征融合机制相结合,在眼底图像分类具有更加精确的结果。
65、(3)本发明可将网络模型利用flutter框架部署到移动应用端。使得本发明可应用到实际场景中,提高眼底疾病的诊断效率。
技术实现思路
- 还没有人留言评论。精彩留言会获得点赞!