一种基于对比学习和变分自编码器的领域外意图检测方法
本发明属于自然语言处理领域,具体涉及一种基于对比学习和变分自编码器的领域外意图检测方法。
背景技术:
1、在面向任务的对话系统中,当用户在特定领域内进行交流时,往往有着明确的意图,如查询、购买、推荐等。对话系统会有这些意图的预先定义,并使用由相应的数据训练出来的模型识别这些意图。领域外意图检测就是对不属于这些预定义意图的用户输入进行识别,从而让对话系统能采取正确的策略进行响应。领域外意图检测是面向任务对话系统中至关重要的功能,它帮助系统识别用户话语中未知或领域外的意图,从而避免采取错误的响应策略。然而,受限于训练数据的质量和数量,深度学模型面临过度自信和分布依赖的问题,这会使它们在实际应用中的性能下降。
2、提升对话系统领域外检测的能力,可以提高系统的稳定性和抗干扰能力。检测领域外意图,能帮助系统找出非服务相关的用户输入。排除领域外数据的干扰后,系统对领域内意图的分类也会更准确。此外,检测出的领域外意图数据还可以用来发现新的与业务相关的新用户意图,可以被用来扩展系统的功能。
3、根据在训练模型时是否需要标注好的领域外意图样本,现有技术可以分为两种方案,一种是需要领域外样本的方案,另一种是不需要领域外样本的方案;第一种方案在训练期间同时使用领域内和领域外样本,例如中国专利cn 116186255 a,这种方案将领域外意图检测视为n+1分类任务,用打好标签的领域内和领域外的样本直接训练一个分类模型进行分类,其中前n类是领域内意图,第n+1类表示领域外的意图。第二种方案在训练期间仅使用领域内样本,被称为无监督领域外检测。例如中国专利cn 114564964 a,这些方法侧重于在训练时让模型学习到有益于领域外检测的语义特征。其目标是最小化类内方差和最大化类间方差,以增加特征空间中领域内意图和领域外意图之间的距离。领域外的数据存在领域内意图之间。最后用训练好的模型得到语句的表示特征,并用一些检测算法识别领域外的意图。在训练时只使用领域内的样本而不需要领域外样本,且使用了k临近对比学习来让模型学习句子嵌入,也就是语义的表示特征。
4、对于需要领域外数据的第一种方案,收集到足够多且合适的领域外样本十分重要。这种方案的模型准确性依赖于用于训练的领域外数据分布。然而在实际应用中,用户输入话语中的意图是多种多样且不断变化的。因此想要获取大量标注好的、涵盖范围足够大的领域外意图数据需要耗费大量的时间和人力。一些方法通过数据增强的技术来自动构造额外的领域外数据,比如通过替换语句的某些词语或是用生成模型直接生成领域外数据。这些方法产生的领域外样本仍然难以覆盖真实场景下的所有开放类别,会导致模型的偏差。
5、对于不需要领域外数据的第二种方案,其模型的准确性依赖于对领域内数据语义特征的学习,如何得到容易分辨的特征表示十分重要。但现有的方案仍然存在一些问题。第一个问题是模型过度自信问题,第二种方案的深度神经模型容易产生高度过度自信的后验分布。一些属于不同意图的语句可能具有相似的单词、语法结构和语义。这类输入会迷惑模型,让模型给出错误的高分,导致对领域外或领域内意图的误判。另一个问题是分布依赖。用户的语句可能并不总是遵循特定的分布,模型可能在训练数据上表现良好,但在真实环境下表现不佳。
技术实现思路
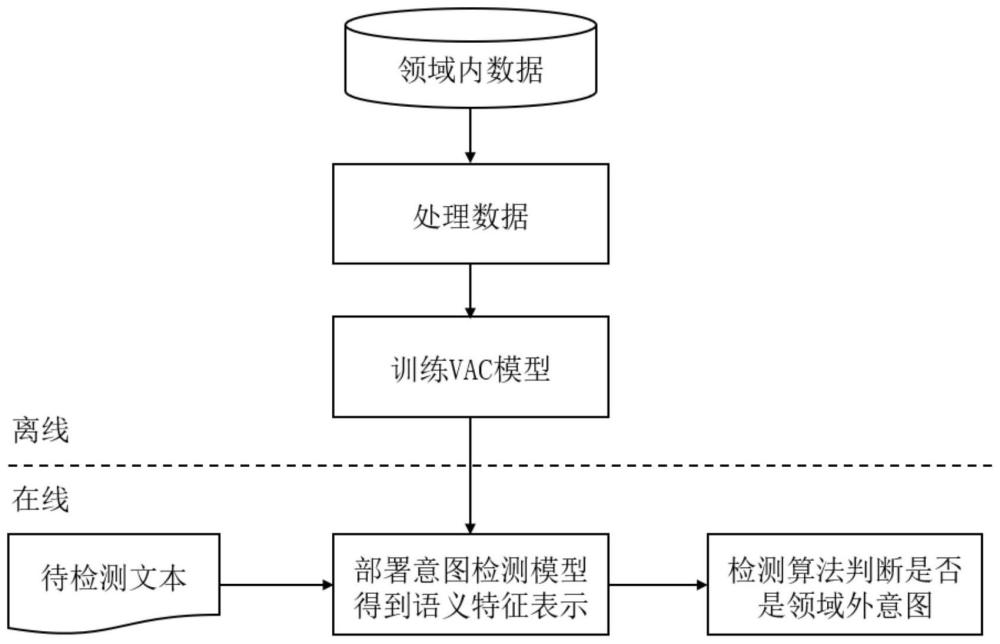
1、为应对现有技术方案存在的问题,本发明使用无监督的领域外检测方法,仅使用领域内数据训练模型。利用变分自编码器和结合了对抗训练的对比学习使模型得到更易于区分的特征表示,以应对过度自信和分布依赖问题。本发明的一种基于对比学习和变分自编码器的领域外意图检测方法被命名为vac(variational auto-encoder withadversarial contrast),包括如下步骤:
2、获取待检测文本;将所述待检测文本输入到训练完成的领域外意图检测模型中,输出得到待检测文本是否为领域外意图的检测结果;
3、其中,领域外意图检测模型的训练过程包括:
4、获取领域内数据;对领域内数据进行预处理,并将领域内数据的语句文本处理成预设长度;将处理好的领域内数据放入领域外意图检测模型中,提取出领域内数据的特征表示,将所述领域内数据的特征表示输入到两个不同多层感知机中,分离得到原始领域外特征表示和原始领域内特征表示,使用变分自编码器重构原始领域外特征表示和原始领域内特征表示,将分离得到的原始领域外特征表示、重构领域外特征表示、原始领域内特征表示和重构领域内特征表示分别采用基于互信息的训练和基于对抗对比学习的训练。
5、本发明的有益效果:
6、(1)相较于需要使用领域外数据的方案,本方案使用无监督的领域外检测方法,不需要收集额外的领域外数据,节省了准备数据需要的时间和人力成本。
7、(2)相较于不使用领域外数据的现有方案,本方案有以下优点:
8、①本发明提出了一个新的领域外意图检测的框架,利用变分自编码器分离语句中领域外和领域内的特征,同时利用重构误差放大领域外样本与领域内样本表示特征之间的差距,得到更易于分辨的表示特征。
9、②本发明的模型在较少数据下仍然拥有更高的准确率和更好的泛化性。利用分离的领域外特征、变分自编码器以及对抗攻击增强的样本,丰富了模型能学习到的语义维度,使用对比学习拉近了相同分类表示特征间的距离,提升了模型准确率和泛化性。
10、③本发明采用了多任务(对比、对抗、领域内分类、互信息)训练,各个任务间互相协同,增强模型的训练效果。
11、④本发明使用双向lstm编码,相比传统transformer类的大型预训练模型,采用的参数更少,其训练和计算速度更快。
技术特征:
1.一种基于对比学习和变分自编码器的领域外意图检测方法,其特征在于,所述方法包括:
2.根据权利要求1所述的一种基于对比学习和变分自编码器的领域外意图检测方法,其特征在于,所述预设长度的计算公式包括:
3.根据权利要求1所述的一种基于对比学习和变分自编码器的领域外意图检测方法,其特征在于,所述提取出领域内数据的特征表示的过程包括采用词嵌入层对所述领域内数据进行处理,提取出领域内数据的语句文本的各个词嵌入向量;使用双向长短时记忆神经网络对各个词嵌入向量进行处理,得到词序列编码;对所述词序列编码中的隐藏状态矩阵使用注意力机制进行处理,得到领域内数据的特征表示。
4.根据权利要求1所述的一种基于对比学习和变分自编码器的领域外意图检测方法,其特征在于,采用基于互信息的训练的过程包括:
5.根据权利要求1所述的一种基于对比学习和变分自编码器的领域外意图检测方法,其特征在于,采用基于对抗对比学习的训练的过程包括:
6.根据权利要求4或5所述的一种基于对比学习和变分自编码器的领域外意图检测方法,其特征在于,分类器的分类损失的计算公式包括:
7.根据权利要求5所述的一种基于对比学习和变分自编码器的领域外意图检测方法,其特征在于,使用分类器的分类损失对清洁样本的特征表示进行扰动,生成领域内数据的对抗样本包括计算出分类器的分类损失的一阶导数,对所述一阶导数进行正则化,采用控制参数对正则化后的一阶导数进行调整,得到扰动参数;将所述扰动参数叠加到清洁文本的词嵌入向量中,使用双向长短时记忆神经网络对叠加后的各个词嵌入向量进行处理,得到词序列编码;对所述词序列编码中的隐藏状态矩阵使用注意力机制进行处理,得到对抗文本的特征表示。
8.根据权利要求5所述的一种基于对比学习和变分自编码器的领域外意图检测方法,其特征在于,所述对抗对比学习损失的计算公式表示为:
技术总结
本发明属于自然语言处理领域,具体涉及一种基于对比学习和变分自编码器的领域外意图检测方法,所述方法包括获取待检测文本;将所述待检测文本输入到训练完成的领域外意图检测模型中,输出待检测文本是否为领域外意图的检测结果;本发明将变分自编码器和对比学习结合,使模型仅需要较少领域内标注数据训练,就能准确分辨领域内和领域外意图。利用变分自编码器的重构误差,使模型生成更容易分辨的特征表示。此外,该方法在训练时,生成对抗样本以增强数据,并结合对比学习和对抗训练,提升模型的判别能力。本发明利用变分自编码器和对比学习,加强模型对意图特征的学习,提升了领域外意图检测的准确性和泛化能力。
技术研发人员:雷建军,刘靖豪
受保护的技术使用者:重庆邮电大学
技术研发日:
技术公布日:2024/3/24
- 还没有人留言评论。精彩留言会获得点赞!