一种分布式数据库查询的优化方法、装置及存储介质与流程
本技术涉及数据库,更具体的说,涉及一种分布式数据库查询的优化方法、装置及存储介质。
背景技术:
1、一般面向大数据的分布式关系型数据库,逻辑上可分为两层:计算引擎层和存储引擎层。其中,计算引擎层负责结构化查询语言(structured query language,sql)语句解析、分布式执行计划生成、优化和执行,存储引擎层负责数据的存储和读取。
2、目前,计算引擎是按照自己的哈希算法,对查询语句中涉及到参与连接的两张表的数据,同时按连接键做哈希,然后根据哈希分布规则,将数据重分布到对应的节点,在对应的节点完成哈希连接,生成结果集。但是,数据重分布的过程会产生大量的网络流量,增加查询的响应时间。
技术实现思路
1、有鉴于此,本技术实施例公开一种分布式数据库查询的优化方法、装置及存储介质,消除不必要的数据重分布过程,降低网络负载,减少查询的响应时间。
2、本技术实施例提供的技术方案如下:
3、第一方面,本技术实施例提供了一种分布式数据库查询的优化方法,所述方法包括:
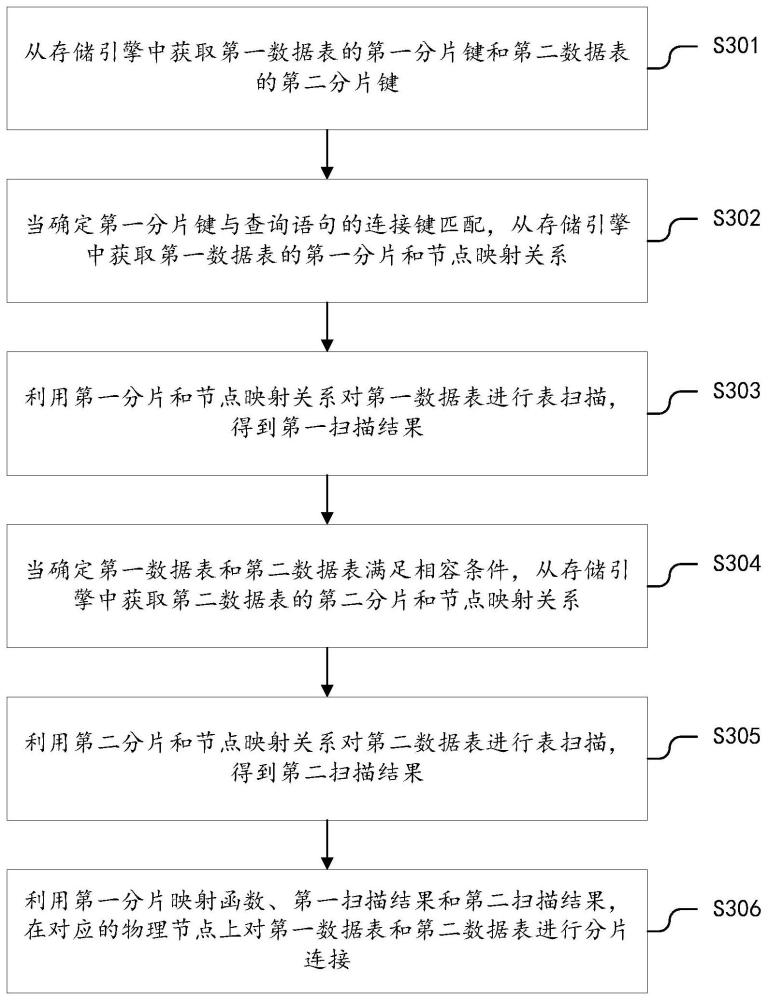
4、从存储引擎中获取第一数据表的第一分片键和第二数据表的第二分片键;
5、当确定所述第一分片键与查询语句的连接键匹配,从所述存储引擎中获取所述第一数据表的第一分片和节点映射关系;
6、利用所述第一分片和节点映射关系对所述第一数据表进行表扫描,得到第一扫描结果;
7、当确定所述第一数据表和所述第二数据表满足相容条件,从所述存储引擎中获取所述第二数据表的第二分片和节点映射关系;所述相容条件包括:所述第一分片键与所述第二分片键相同,且所述第一数据表的第一分片映射函数与所述第二数据表的第二分片映射函数一致,且所述第一数据表的逻辑分片数与所述第二数据表的逻辑分片数是整数倍关系,且所述第一分片和节点映射关系与所述第二分片和节点映射关系一致;
8、利用所述第二分片和节点映射关系对所述第二数据表进行表扫描,得到第二扫描结果;
9、利用所述第一分片映射函数、所述第一扫描结果和所述第二扫描结果,在对应的物理节点上对所述第一数据表和所述第二数据表进行分片连接。
10、在一种可能的实现方式中,所述方法还包括:
11、当确定所述第一数据表和所述第二数据表不满足所述相容条件,获取所述第一分片映射函数;
12、对所述第二数据表进行表扫描,得到第三扫描结果;
13、利用所述第一分片映射函数、所述第一分片和节点映射关系和所述第三扫描结果对所述第二数据表进行数据重分布,得到重分布结果;
14、利用所述第一分片映射函数、所述第一扫描结果和所述重分布结果,在对应的物理节点上对所述第一数据表和所述第二数据表进行分片连接。
15、在一种可能的实现方式中,所述当确定所述第一分片键与查询语句的连接键匹配,从所述存储引擎中获取所述第一数据表的第一分片和节点映射关系,包括:
16、当确定所述第一分片键、所述第二分片键与查询语句的连接键均匹配,且所述第一数据表的逻辑分片数多于所述第二数据表的逻辑分片数,从所述存储引擎中获取所述第一数据表的第一分片和节点映射关系。
17、在一种可能的实现方式中,所述利用所述第一分片映射函数、所述第一扫描结果和所述第二扫描结果,在对应的物理节点上对所述第一数据表和所述第二数据表进行分片连接之前,所述方法还包括:
18、确定所述第一数据表为分片连接的左表,所述第二数据表为分片连接的右表。
19、在一种可能的实现方式中,所述第一扫描结果包括n个第一子扫描结果,一个所述第一子扫描结果对应一个所述第一数据表的逻辑分片,所述n为大于等于2的正整数;
20、所述第二扫描结果包括m个第二子扫描结果,一个所述第二子扫描结果对应一个所述第二数据表的逻辑分片,所述m为大于等于2的正整数。
21、在一种可能的实现方式中,所述n大于所述m,所述方法还包括:
22、利用所述第一分片映射函数对所述第二扫描结果进行拆分,得到第四扫描结果;所述第四扫描结果包括n个第四子扫描结果;
23、所述利用所述第一分片映射函数、所述第一扫描结果和所述第二扫描结果,在对应的物理节点上对所述第一数据表和所述第二数据表进行分片连接,包括:
24、利用所述第一分片映射函数、所述第一扫描结果和所述第四扫描结果,在对应的物理节点上对所述第一数据表和所述第二数据表进行分片连接。
25、第二方面,本技术实施例提供了一种分布式数据库查询的优化装置,所述装置包括:
26、获取模块,用于从存储引擎中获取第一数据表的第一分片键和第二数据表的第二分片键;
27、所述获取模块,还用于当确定所述第一分片键与查询语句的连接键匹配,从所述存储引擎中获取所述第一数据表的第一分片和节点映射关系;
28、表扫描模块,用于利用所述第一分片和节点映射关系对所述第一数据表进行表扫描,得到第一扫描结果;
29、所述获取模块,还用于当确定所述第一数据表和所述第二数据表满足相容条件,从所述存储引擎中获取所述第二数据表的第二分片和节点映射关系;所述相容条件包括:所述第一分片键与所述第二分片键相同,且所述第一数据表的第一分片映射函数与所述第二数据表的第二分片映射函数一致,且所述第一数据表的逻辑分片数与所述第二数据表的逻辑分片数是整数倍关系,且所述第一分片和节点映射关系与所述第二分片和节点映射关系一致;
30、所述表扫描模块,还用于利用所述第二分片和节点映射关系对所述第二数据表进行表扫描,得到第二扫描结果;
31、连接模块,用于利用所述第一分片映射函数、所述第一扫描结果和所述第二扫描结果,在对应的物理节点上对所述第一数据表和所述第二数据表进行分片连接。
32、在一种可能的实现方式中,所述装置还包括:数据重分布模块;
33、所述获取模块,还用于当确定所述第一数据表和所述第二数据表不满足所述相容条件,获取所述第一分片映射函数;
34、所述表扫描模块,还用于所述对所述第二数据表进行表扫描,得到第三扫描结果;
35、所述数据重分布模块,用于利用所述第一分片映射函数、所述第一分片和节点映射关系、所述第三扫描结果对所述第二数据表进行数据重分布,得到重分布结果;
36、所述连接模块,还用于利用所述第一分片映射函数、所述第一扫描结果和所述重分布结果,在对应的物理节点上对所述第一数据表和所述第二数据表进行分片连接。
37、第三方面,本技术实施例提供了一种分布式数据库查询的优化装置,包括:
38、存储器,用于存储指令;
39、处理器,用于执行所述存储器中的所述指令以执行以上第一方面任一项所述的分布式数据库查询的优化方法。
40、第四方面,本技术实施例提供了一种计算机可读存储介质,包括指令,当其在计算机上运行时,使得计算机执行以上第一方面任一项所述的分布式数据库查询的优化方法。
41、第五方面,本技术实施例提供一种计算机程序产品,所述计算机程序产品在终端设备上运行时,使得所述终端设备执行以上第一方面任一项所述的分布式数据库查询的优化方法。
42、基于上述技术方案,本技术具有以下有益效果:
43、本技术实施例公开了一种分布式数据库查询的优化方法、装置及存储介质。其中,该方法包括:从存储引擎中获取第一数据表的第一分片键和第二数据表的第二分片键;当确定第一分片键与查询语句的连接键匹配,从存储引擎中获取第一数据表的第一分片和节点映射关系;利用第一分片和节点映射关系对第一数据表进行表扫描,得到第一扫描结果;当确定第一数据表和第二数据表满足相容条件,从存储引擎中获取第二数据表的第二分片和节点映射关系;利用第二分片和节点映射关系对第二数据表进行表扫描,得到第二扫描结果;利用第一分片映射函数、第一扫描结果和第二扫描结果,在对应的物理节点上对第一数据表和第二数据表进行分片连接。可见,本技术实施例中计算引擎会参考存储引擎的分片和节点映射关系、分片映射函数进行表扫描、分片连接,当参与连接的第一数据表和第二数据满足相容条件,会消除第一数据表和第二数据表的数据重分布过程,从而能降低网络负载,减少查询的响应时间。
- 还没有人留言评论。精彩留言会获得点赞!