文本匹配分的计算方法、系统、文本匹配方法与流程
本发明涉及文本处理领域,具体涉及一种文本匹配分的计算方法、系统、文本匹配方法。
背景技术:
1、编辑距离算法(edit distance)为一种现有文本相关性算法,是衡量两个字符串之间相似程度的度量指标。它表示将一个字符串转换为另一个字符串所需的最少编辑操作次数,每个编辑操作可以是插入、删除或替换一个字符。
2、该算法在计算词与词之间的文本相似度时具有一定优势,但计算结果会受到词长影响而产生较大偏差,例如me和mac(编辑距离2),比较于me和melbourne(编辑距离7),然而在联想场景中,显然melbourne为搜索目标的可能性高于mac。
3、其次也不能很好的适用于计算词组与词组之间的文本相似度,结果会受词数明显影响,例如:shanghai hongqiao和hongqiao district(编辑距离8)比较于shanghaihongqiao和shanghai hongqiao international airport(编辑距离21),shanghaihongqiao international airport处于劣势,但从联想场景来看,shanghai hongqiaointernational airport这一结果更符合输入意图。
4、同时,词组之间计算时,不同词序也会对结果产生显著影响,例如australiamelbourne(澳大利亚墨尔本)和melbourne australia(编辑距离为12),比较于australiamelbourne和usa melbourne(美国墨尔本)(编辑距离5),美国墨尔本存在优势,但实际上是澳大利亚墨尔本匹配度理应更高。
技术实现思路
1、本发明要解决的技术问题是为了克服现有技术中文本匹配分计算时无法摆脱词语长度的影响的缺陷,提供一种文本匹配分的计算方法、系统、文本匹配方法。
2、本发明是通过下述技术方案来解决上述技术问题:
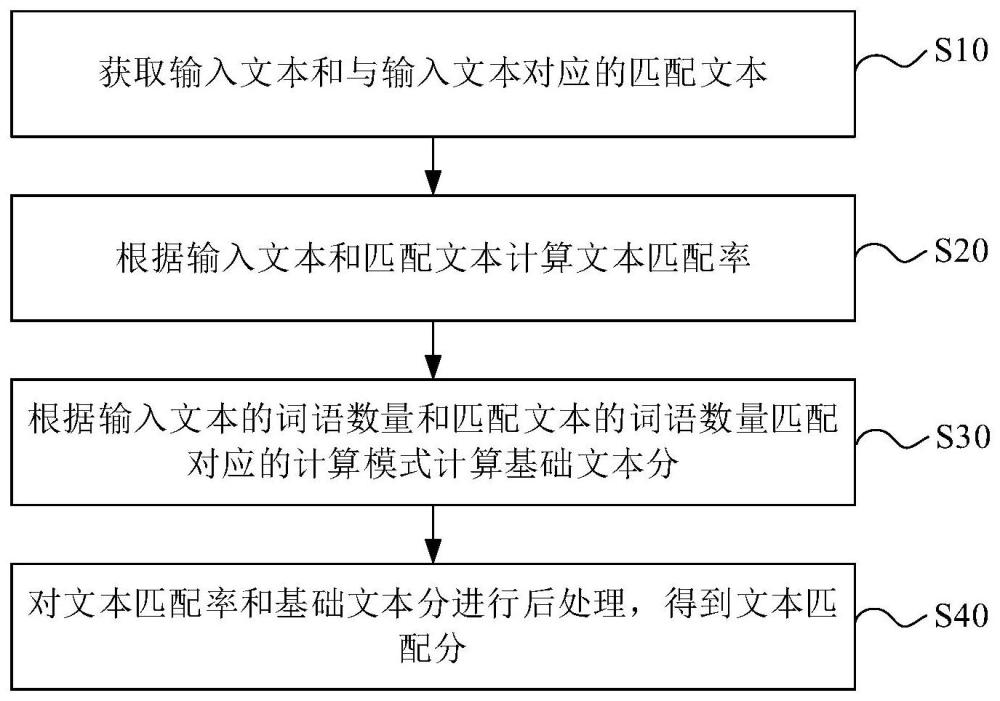
3、本发明提供一种文本匹配分的计算方法,所述计算方法用于计算输入文本和与所述输入文本对应的匹配文本之间的文本匹配分,所述计算方法包括以下步骤:
4、获取输入文本和与所述输入文本对应的匹配文本;
5、根据所述输入文本和所述匹配文本计算文本匹配率
6、根据所述输入文本的词语数量和所述匹配文本的词语数量匹配对应的计算模式计算基础文本分;
7、对所述文本匹配率和所述基础文本分进行后处理,得到文本匹配分。
8、在本方案中,对输入文本和匹配文本的词语数量进行了匹配,使得计算过程更加稳定,避免了因词语数量不同而导致的不稳定因素。该方法可以应用于各种文本匹配场景,如机器翻译、文本摘要、信息检索等,具有较高的通用性。
9、较佳地,所述根据所述输入文本的词语数量和所述匹配文本的词语数量匹配对应的计算模式计算基础文本分的步骤包括:
10、当所述输入文本和所述匹配文本均为一个词语时,根据最长公共子串算法并结合索伦森-骰子系数算法计算所述基础文本分。
11、在本方案中,当输入文本和匹配文本均为一个词时,通过结合最长公共子串算法和索伦森-骰子系数算法来计算基础文本分,可以在较短的时间内得出结果。这有助于提高信息处理速度,缩短用户等待时间。通过确定对应模式,可以减少因词语数量不同而导致的基础文本分计算偏差。从而使系统在处理不同长度文本时具有较好的稳定性,提高系统的适应性。
12、较佳地,所述根据所述输入文本的词语数量和所述匹配文本的词语数量匹配对应的计算模式计算基础文本分的步骤包括:
13、当所述输入文本为多个词语,所述匹配文本为一个词语时,根据最长公共子串算法并结合索伦森-骰子系数算法计算所述输入文本中的每个词语和所述匹配文本的若干初始文本分;
14、以所述初始文本分中的最大值为分子,所述输入文本的词语数量为分母,得到所述基础文本分。
15、在本方案中,通过对每个词语计算初始文本分,并取最大值作为基础文本分,可以避免因单个词语的相似度较低而影响整体相似度评估的结果。这种方法保证了基础文本分的公平性,使评估结果更能反映输入文本与匹配文本的相似度。通过计算每个词语的初始文本分,并以最大值作为基础文本分,可以减少因词语数量不同而导致的基础文本分计算偏差。这使得系统在处理不同长度文本时具有较好的稳定性,提高系统的适应性。结合最长公共子串算法和索伦森-骰子系数算法,可以在较短的时间内计算出每个词语的初始文本分。这有助于提高信息处理速度,缩短用户等待时间。
16、较佳地,所述根据所述输入文本的词语数量和所述匹配文本的词语数量匹配对应的计算模式计算基础文本分的步骤包括:
17、当所述输入文本为一个词语,所述匹配文本为多个词语时,根据最长公共子串算法并结合索伦森-骰子系数算法计算所述输入文本中的词语和所述匹配文本中的每个词语的若干初始文本分;
18、以所述初始文本分中的最大值为分子,所述匹配文本的词语数量为分母,得到所述基础文本分。
19、在本方案中,当输入文本为一个词语,匹配文本为多个词语时,通过最长公共子串算法和索伦森-骰子系数算法计算每个词语的初始文本分,实现了对文本的精细化评估。这有助于更好地捕捉输入文本与匹配文本之间的关联性。
20、较佳地,所述根据所述输入文本的词语数量和所述匹配文本的词语数量匹配对应的计算模式计算基础文本分的步骤包括:
21、当所述输入文本和所述匹配文本均为多个词语时,根据最长公共子串算法并结合索伦森-骰子系数算法计算每一所述输入文本中的词语和每一所述匹配文本中的词语的初始文本分;
22、根据最大无重复采样算法获取所述初始文本分中的最高分作为所述基础文本分。
23、在本方案中,当输入文本和匹配文本均为多个词语时,通过最长公共子串算法和索伦森-骰子系数算法计算每个词语的基础初始文本分,实现了对文本的全面评估。这有助于更好地捕捉输入文本与匹配文本之间的关联性。结合最长公共子串算法和索伦森-骰子系数算法,可以在较短的时间内计算出每个词语的初始文本分。同时,最大无重复采样算法有助于快速找到初始文本分中的最高分,提高信息处理速度,缩短用户等待时间。
24、较佳地,对所述文本匹配率和所述基础文本分进行后处理,得到文本匹配分的步骤包括:
25、对所述文本匹配率和所述基础文本分进行包含修正得到文本包含分;
26、对所述文本包含分进行前缀修正,得到所述文本匹配分。
27、在本方案中,通过对文本匹配率和基础文本分进行包含修正,能够更好地反映出文本的匹配程度,提高匹配的准确性。前缀修正是为了避免短文本匹配时的误差,通过此修正,能够提高长文本匹配的准确性,从而使文本匹配分的计算更加合理。
28、较佳地,所述对所述文本匹配率和所述基础文本分进行包含修正得到文本包含分的步骤包括:
29、根据所述文本匹配率、所述基础文本分和预设包含权重进行所述包含修正,得到所述文本包含分。
30、较佳地,所述对所述文本包含分进行前缀修正,得到所述文本匹配分的步骤包括:
31、根据所述文本包含分和预设前缀匹配权重进行所述前缀修正,得到所述文本匹配分。
32、本发明另一方面提供一种文本匹配分的计算系统,所述计算系统用于计算输入文本和与所述输入文本对应的匹配文本之间的文本匹配分,所述计算系统包括:
33、文本获取模块,用于获取输入文本和与所述输入文本对应的匹配文本;
34、匹配率计算模块,用于根据所述输入文本和所述匹配文本计算文本匹配率;
35、基础文本分计算模块,用于根据所述输入文本的词语数量和所述匹配文本的词语数量匹配对应的计算模式计算基础文本分;
36、文本匹配分计算模块,用于对所述文本匹配率和所述基础文本分进行后处理,得到文本匹配分。
37、本发明另一方面提供一种文本匹配方法,所述文本匹配方法运用如上所述的计算方法,所述文本匹配方法包括:
38、获取输入文本和与所述输入文本对应的匹配文本,
39、根据所述计算方法计算所述匹配文本与所述输入文本之间的文本匹配分;
40、根据所述文本匹配分将所述匹配文本中的词语进行排序,完成文本匹配。
41、本发明的积极进步效果在于:本发明对输入文本和匹配文本的词语数量进行了匹配,使得计算过程更加稳定,避免了因词语数量不同而导致的不稳定因素。该方法可以应用于各种文本匹配场景,如机器翻译、文本摘要、信息检索等,具有较高的通用性。
- 还没有人留言评论。精彩留言会获得点赞!