语义大数据驱动的自定义网页主题提取方法与流程
本技术涉及一种大数据自定义网页主题提取方法,特别涉及一种语义大数据驱动的自定义网页主题提取方法,属于自定义网络主题提取。
背景技术:
1、互联网变革时代,人们获取信息的方式受其影响颇大。面对互联网如此巨大的信息库,人们所能获取信息的体量也愈加庞大,但随着信息量的极速增长,针对性获取信息并维护的难度也变得更大。此时,海量的网络数据源成了甜蜜的烦恼。为了更好的利用互联网信息量大的优势,并有效规避干扰信息,结合信息提取技术和互联网信息构造自身的特点,进行互联网信息提取非常重要。
2、相比传统信息提取技术,互联网信息提取有以下区别:(1)数据源异构,传统信息提取的数据源通常为数据仓库,所存储数据较为规整。互联网信息提取的对象为整个互联网,不仅数据集的体量更加庞大,从存储环境来说,互联网信息的存储是分布式的,存放在全球各地的服务器,服务器硬件上如操作系统,数据库服务器等都有差异;从数据格式来说,不同服务器的信息组织方式也不尽相同。(2)数据半构造化,传统文本是一种无构造的序列化存储方式,而互联网信息的载体为html编码,格式非常繁杂,编码模型不够严谨统一,且含有大量标签噪声。相对于传统文本数据的无构造性,互联网信息含有一定的层次构造,其数据呈现半构造化状。传统信息提取技术所处理的对象是文本内容本身,主要还是利用自然语言处理的相关技术对文本信息提取。而互联网信息提取由于以上特征,无法套用传统信息提取技术。对于数据源的获取集成、噪声信息的容错和信息半构造化的利用都要进一步研究。
3、网页信息提取可以从繁杂的互联网信息中提取与自定义需求相关的主题数据,将获取的信息以规整的形式呈现输出。可以方便读者浏览,也可以方便研究者查询、统计和分析,使研究者对于互联网信息的处理可以接近对于传统数据库构造化信息处理的效率。进一步说,网页信息提取可以作为一个基层应用,给上层的各类数据处理应用提供信息源。从互联网所提取的规整信息,根据其领域不同,进行进一步封装,可以构建相关领域的信息模型库,进一步方便生活学习工作。现实生活中所熟知的比价应用、舆情分析系统、推荐算法、信息情报系统等,都离不开网页信息提取的底层支持。网页信息提取所提供的这些便利和效益,都例证了网页信息提取研究是极具应用前景和研发意义的。
4、现有技术的自定义网页主题提取需要解决的问题和本技术关键技术难点包括:
5、(1)面对互联网巨大信息库的信息量极速增长,针对性获取信息并维护的难度也变得更大,现有技术无法有效利用互联网信息量大的优势,无法有效规避干扰信息,缺少结合信息提取技术和互联网信息构造自身的特点进行互联网信息提取的方法,直接导致用户获取的信息并不是有效信息,读者不想看到的干扰信息也在不断增加,用户获取所需内容的难度也不断增加。比如网页中的广告推广和导航栏等噪声块对于用户阅读体验的影响;论坛里会有大量灌水信息,评论所提及的信息并非都有价值;微博等海量主题的网页里并非所有内容都是读者关心的信息,给人们针对性的阅读带来了不少障碍,缺少能够根据用户自定义信息进行网页主题有效提取的方法。
6、(2)现实生活中的比价应用、舆情分析系统、推荐算法、信息情报系统等,都离不开网页信息提取的底层支持,但现有技术的网页信息提取系统,无法将结点文本作为网页的本底内容单位,缺少结合结点文本的语义关联性和主题结点构成主题内容的构造层次规律,无法构建出结点语义模型对网页内容进行分析操作,语义分析仅应用于非构造文本,无法对网页半构造化文本进行语义分析和主题提取。缺少差异性词义匹配进行结点语义关联度的计算,语义噪声大,无法准确的反映出结点文本和主题含义关联程度。无法剔除网页内繁杂的网页元素、目不暇接的推广信息和用户不关心的主题内容,无法让用户根据需求自定义主题,直接提取自己需要阅读的内容,用户难以根据阅读需求自定义主题词或主题句,基于语义相关性在互联网中提取用户所需的主题,无法直接将读者所需的信息以最简洁的方式呈现出来。
7、(3)现有技术无法根据用户自定义的需求从互联网中获取和需求相关的主题内容,一是无法生成网页构造树,缺少对所获取网页进行规范化处理,缺少噪声信息预过滤,无法去除网页表达形式噪声并依据网页层次生成构造树模型;二是缺少主题噪声块摘除,缺少利用调节枝叶匹配算法识别疑似噪声区域;无法通过计算链接构造平衡对疑似簇进行筛选;三是缺少语义大数据关联度的网页主题提取,无法结合结点文本的语义相关性和主题结点构成主题内容的构造层次规律,缺少构建出结点语义模型对网页内容进行解析,无法定义词条近似度并实现词条近似度算法;无法构建结点语义相关度并实现差异性词义匹配算法降低语义噪声的影响,不能反映结点文本和自定义主题的含义相关程度,无法构造结点语义模型;无法剪枝遍历主题结点集实现主题提取,用户自定义网页主题提取的准确率和效率都比较低。
技术实现思路
1、本技术提出了语义大数据驱动的自定义网页主题提取方法,对于从互联网提取的网页资源,采用简洁高效的构造树生成算法,构造网页层次模型。在层次化的网页构造树基础上,对网页内容进行噪声块识别和去噪,去除了网页表达形式和主题噪声,保留主题内容层次和内容元素。在最核心的主题提取模块,构建了词条含义近似度算法、结点语义相关度的算法、结点语义模型构造算法和主题结点集的提取算法。实现在用户给定自定义主题的情况下,从海量互联网原始网页中提取所需的自定义主题内容。提高了人们在阅读网页时的效率,剔除了网页内繁杂的网页元素、目不暇接的推广信息和用户不关心的主题内容,让用户根据需求自定义主题,直接提取自己需要阅读的内容,算法效率较高,具有较好的稳定性、鲁棒性与实用性。
2、为实现以上技术效果,本技术所采用的技术方案如下:
3、语义大数据驱动的自定义网页主题提取方法,根据用户自定义的需求从互联网中获取和需求相关的主题内容:第1部分为网页库获取,从海量的互联网资源中获取待提取网页数据;第2部分将获取的网页库进行构造化计算,生成半构造化的网页构造树内容载体;第3部分对网页构造树进一步规整,利用调节枝叶匹配和链接构造平衡算法对网页中广告、导航噪声块进行摘除;第4步为主题提取,将树结点作为本底内容对象,通过分词、词语近似度计算、结点关联度计算、结点语义模型构造和主题结点集提取,根据用户自定义需求对网页主题进行提取,封装为目标主题集呈现给用户;
4、1)生成网页构造树:首先对所获取网页进行规范化处理,使网页编码符合规整;然后进行噪声信息预过滤,去除网页表达形式噪声;之后依据网页层次生成构造树模型;
5、2)主题噪声块摘除,包括:主题噪声块定义与特征、噪声块识别算法、调节枝叶匹配模型、单结点内噪声块识别算法、链接构造平衡筛选可疑簇、构造树噪声块摘除,在层次化的网页构造树基础上,利用调节枝叶匹配算法识别疑似噪声区域;通过计算链接构造平衡对疑似簇进行筛选,摘除经确认的噪声块,使构造树只保留主题内容层次和主题内容元素;
6、3)语义大数据关联度的网页主题提取:将结点文本作为网页的本底内容单位,结合结点文本的语义相关性和主题结点构成主题内容的构造层次规律,构建出结点语义模型对网页内容进行解析;定义词条近似度并实现词条近似度算法;构建结点语义相关度并实现差异性词义匹配算法降低语义噪声的影响,准确反映结点文本和自定义主题的含义相关程度;构造结点语义模型;最后剪枝遍历主题结点集实现主题提取。
7、优选地,主题噪声块定义与特征:对于提取网页主题的需求,与网页主题内容无关的所有网页元素都是主题噪声,网页构造树是网页的载体,对于主题噪声块的识别,依据其在构造树中所对应结点簇的特征,其特征如下:1)同一噪声块内噪声结点在树中父结点相同;2)同一噪声块的噪声结点在树中的结点相邻;3)噪声块的组成结点中包含大量链接;4)噪声的组成结点中包含结点构造具有极大相似性;
8、主题噪声块中的记录都具有相同的编码模式,共同编码模式的发现是识别主题噪声块的过程,对于此编码模式的发现参照网页构造树的两个重要特征:
9、特征1:对于符合主题噪声块特征的结点簇,相邻结点簇对应的网页元素都在相同网页的某个区域块连续出现,并且对应的html标签构造相似,即每个噪声结点簇都具有相近的编码模式,这样一个子结点簇就对应列表中一项;
10、特征2:同一个噪声块下的结点簇父结点相同,且单条噪声基本不可能起始结点和终结点分别处于不同结点簇中间位,即噪声记录起始某结点簇起始结点并结束于该结点簇或同层后续某结点簇的终结点。
11、优选地,噪声块识别算法:主题噪声块的识别是根据其特征进行区域搜寻的过程,搜寻过程分成两个阶段:(1)判定可疑区域(2)确定噪声块;
12、第1阶段根据噪声块的构造特征,即①噪声块结点相邻、②噪声块结点共父结点、③噪声块结点构造相似这三个特征在网页中进行初步定位,利用树的半构造特征通过枝叶匹配来进行噪声块的定位;
13、枝叶匹配是两个树之间变换为一致所需的最少变换,变换操作包括也仅包括插入、删除、替换操作,枝叶匹配找寻两树间最少变换映射的过程,枝叶匹配映射描述如下:
14、对于树tree,其先序遍历的第i个结点标为tree[i],对于t1和t2两棵树,其匹配映射m是结点对[t1[i],t2[j]构成的有序集,对于任何在有序集大小范围内的下标n和m,存在特征:
15、(1)当且仅当t1[n]=t1[m]时,t2[n]=t2[m];
16、(2)当t1[n]位于t1[m]左(右)侧,t2[n]也位于t2[m]左(右)侧;
17、(3)当且仅当t1[n]为t1[m]祖辈时,t2[n]也t2[m]祖辈;
18、特征(1)和(2),枝叶匹配映射一对结点t1[i],t2[j]在各自树构造中的相对位置必须相同,特征(3)在枝叶匹配映射对中结点的层次依赖关系需一致;
19、枝叶匹配可以跨层次映射,噪声块结点相邻且共父结点的特征不允许枝叶匹配时进行跨层次操作,不允许跨层次匹配的枝叶匹配操作,为调节枝叶匹配,用以计算结点簇的相似度,判断可疑区域结合调节枝叶匹配模型和构造树特征进行构造;
20、第2阶段是判定第一阶段所识别的可疑块是否确实为噪声块,根据噪声块链接构造较多的特征,计算块链接构造平衡进行判定。
21、优选地,调节枝叶匹配模型:鉴于噪声块构造特征禁止跨层操作的枝叶匹配,识别两棵结点簇中标签结点的最大匹配域,严格按照结点簇中结点顺序进行匹配比较,禁止结点间交叉层次和替换后再比较;
22、对于树t1和树t2,t1和t2中的对应结点表示为t1i,t2 j,tl和t2的匹配域为s,在匹配域s中,每一个非根结点t1i和t2 j对应的父结点也在s中,对于所包含结点最大的1个或几个匹配域即树t1和树t2的最大匹配域,定义最大匹配域结点对个数为smax:
23、
24、式中,t1k是树t1中首层第k个子结点,t2n是树t2首层第n个子结点,s({t1,…,t1k},{t21,…,t2n})是指树t1和t2中首层结点集最大匹配域的结点对数,对于s({t1,…,t1k},{t21,…,t2 n})的取值方式为:
25、(1)如果{t1,…,t1k}和{t21,…,t2 n}之一或都为空,s({t1,…,t1k}和{t21,…,t2n})=o;
26、(2)否则s({t1,…,t1k}和{t21,…,t2 n})=max(s({t1,…,t1k-1}和{t21,…,t2n-1})+stm(t1k,t2n),s({t1,…,t1k}和{t21,…,t2n-1}),s({t1,…,t1k-1}和{t21,…,t2n}));
27、对于上述最大匹配域算法,如果两树根结点的标签属性就不一致,则两树必不近似,最大匹配域为0,如果根结点标签属性一致,则采用动态规划定义矩阵s保存动态计算时的最大匹配值,从两树首层子结点集的最大匹配值依次向下计算,并保存在矩阵中,最终得出两棵树最大匹配标签结点数,将此值用来判定两树是否近似,结合树体量进行规整,将标签匹配值加倍后除以两树的标签总数:
28、
29、nodescount(t1),nodescount(t2)分别表示两树的标签总数。
30、优选地,单结点内噪声块识别算法:从给定结点中,识别出其次层结点中所包含的噪声结点,在同一结点下,可能包含不止一个噪声块,每个噪声块包含至少两个相邻且相似的结点,严格按照构造树中结点的先后顺序进行匹配,所判定父结点的次层子结点中,每n个相邻且近似度满足一定条件的结点划分为一个可疑块,对于可疑块再利用链接构造平衡判断是否为噪声块;以给定结点作为子结点,遍历其所有子结点,识别出其中噪声区域,并按照区域进行分开存放。
31、优选地,链接构造平衡筛选可疑簇:通过调节枝叶匹配在构造树识别可疑簇,其识别过程利用噪声块特征中的以下几点:1)同一噪声块内噪声结点在树中父结点相同;2)同一噪声块的噪声结点在树中的结点相邻;3)噪声块中的结点在标签构造上具有极大相似性;
32、噪声块的组成结点中包含大量链接噪声块是另一个重要特征,本技术利用这个特征提出采用链接构造平衡ngp进行可疑簇的检测,ngp反映可疑簇中链接结点数lc与文本技术点数tc的比例,表达式如下:
33、
34、在可疑簇筛选过程中,设定ngp的临界值为0.3,即如果可疑簇的ngp值大于或等于0.3,则判定此可疑簇为噪声块,此方式对噪声块进行识别具有较好的准确性;
35、对单个可疑簇的判定方法如下:
36、1)以宽度优先遍历可疑簇,根标签入队;
37、2)队首标签出队,该标签所有子标签入队,标签总数tc加1,如果为链接标签则链接标签数lc加1;
38、3)如果队中元素不为空,重复步骤2),否则下一步;
39、4)利用式3计算可疑簇链接构造平衡,计算出ngp值后即可判断当前可疑簇是否为噪声块,如果大于设定临界值则为噪声块,进行摘除。
40、优选地,词条近似度算法:对词语含义近似度进行量化,量化的数值标准规整在值域[0,1]之间,值越接近1表示词语间的意思越接近,越趋向0则差别越大,语义完全相同和完全不可相互替换时,语义近似度则分别取到1和0两个最值,在基于同义词词林的词语相似度算法中,通过在同义词林构造树中考量词语义项所处的位置,比对各义项结点间的语义距离来量化词语的语义相似度,语义距离越近则语义近似度愈大,语义距离越远则近似度越小,词语与自身本身的距离为0,近似度最大,完全不相干的词条之间不可达,相似度趋近为0;
41、计算词条间语义近似度,需要将其所包含义项逐对计算义项近似度,再整合出词条语义近似度,义项间的近似度计算要将其最深公共义项层、公共层枝叶数和义项分支距离建模整合;
42、(1)构建义项编码库:简化编码操作,保留语义体系构造,根据源编码构建义项编码库,将义项编码库定义为两个map集合,分别为义项库和编码库;
43、1)构建义项库:通过义项库快速确定词条共有多少义项并提取义项各自的编码,义项库的key值为词条,value值为其所有义项编码的集合;
44、构建方式:遍历源编码词条,将词条作为key值,词条每个义项编码存入其相应的value集合;
45、2)构建编码库:对于任一义项编码,通过编码库快速确定该编码所对应的义项簇共有多少词条并提取词条,编码库的key值为义项编码,value值为其对应所有词条的集合;
46、构建方式:遍历源编码义项编码,将义项编码作为key值,义项编码对应的每个词条存入其相应的value集合,将原编码整理构建成义项编码库,在后续操作中结合词林的编码特点复现词林的语义体系,简化编码的关联操作;
47、(2)最深公共义项层:词条根据语义体系树的深度不断细化,比较不同词条的语义近似性,先找到义项的最深公共结点,以判定其最深公共义项层,最深公共义项层的层次越深,义项的含义越为接近;
48、(3)公共层枝叶数:计算公共层枝叶数需要分析义项编码的层次特征,定义滑标编码,通过统计分支变更数,正确统计义项枝叶数,具体流程:将义项公共层编码作为本算法的输入,编码库的key值集合为义项编码集合,从编码集首编码开始遍历,定义游标指针judgeencode指向当前编码,定指针cursorencode指向后一编码,找到目标义项层后,在指针滑动的同时进行判定,若访问编码和游标编码的分支层编码不同,则枝叶数加一,若义项层分支遍历完毕或编码集遍历到头,则返回枝叶数n;
49、(4)义项分支距离:为两义项结点在其最深公共结点下,所处的分支间的距离,义项语义分支距离计算的是两个义项间隔的枝叶数,其计算思路是在词林中找到其中一个义项后开始统计枝叶数,直到找到另一个义项为止,在公共层枝叶数算法的基础上,添加访问标记findflag,记录是否找到其中一个义项,当findflag为false时顺序遍历词林编码,当judge指向其中一个义项后flag置为true,开始统计其与另一个义项所在公共层,从当前位置开始经过的分支,直到judge指向另一个义项,统计出的枝叶数为义项分支距离;
50、(5)义项近似度:根据词林的语义体系层次、义项在语义层次树中不同语义路径上的距离,再依据其对词条含义的影响大小,进行加权处理后可以量化出义项含义近似度,语义层次根据对义项含义的不同影响,拆分为最深公共义项层数h、公共层枝叶数n和义项分支距离k处理,为计算义项含义近似度的参数;
51、公共义项层数h的取值在[0,5]之间的整数,以标准量化层次权重因子hpw,结合义项近似度[0,1]的临界值,将参数定为:
52、
53、当h=5时,表示两义项处于同一义项簇,α的取值根据义项簇的标志位决定,当标志位为=时,表示义项簇为同义义项簇,α取值为1,当标志位为#时,表示关联义项簇,α取值为0.7,@表示义项簇封闭,只包含一个义项,不会有共义项簇的情况,不在考虑范围内;
54、义项分支层结点数n表示所在义项结点的语义密度,直接影响义项含义的近似度,义项分支结点越多,义项含义偏差越大,义项分支距离k表示所比较义项在所处公共义项层下的结点距离,在同语义层下的语义距离,距离越大,含义偏差越大,根据两者在语义体系中对于近似度的关系,量化成控制因子cc:
55、
56、控制因子只在义项在同一义项树上才生效,即h>o时才需要控制因子,将义项含义近似度以sim表示,则:
57、
58、控制因子为cc,层次权重因子为hpw;
59、(6)词条语义相似度:多义词根据其不同含义单独拆分进行编排,然后把所有义项分类编排,通过比较义项编码在语义体系中的距离关系,得出义项含义近似度,比较词条相似度将词条所有义项依次比较,取出其中的最大值;
60、义项库中词条为key值,value值的集合为其所有义项编码的集合,比较两个词条的含义近似度时,将其义项编码集合的编码互相依次比较近似度,取最大值作为词语的近似度值。
61、优选地,结点语义关联度:
62、1)语义关联度定义:指网页里各项内容和用户自定义主题所表达含义的关联程度,将构造树的基本语义单位视为叶子结点,从叶子结点向上,先聚集成小簇,小簇再逐层向上归并直到根结点;
63、计算网页中各个语义单元与自定义主题在含义上的关联性,根据对于提取主题在广度和精度上的需求,对网页主题进行基于文本语义的提取,结点文本是网页构造树中最基本的语义单元,词条是组成语义单元的最基本单位,判断主题结点文本与需求主题的语义关联性,计算组成结点文本的词条集与自定义主题的关联性;
64、2)构造主题词集与文本词集对网页语义体系进行主题内容筛选时,比较的语义对象为自定义主题与各结点文本,比较其间关联度,将文本分解为最基础的有独立含义的语义单元,将自定义主题与各结点文本分别做分词处理,保留词性存入关联集合,构建完整词条集;
65、采用利用隐马的多层次模型进行分词处理,对与自定义主题和结点文本,分别用nlpir进行分词并标注词性,将划分的词条依原序存放在集合,每个词条后以”/”为界限标上词条的词性,构建主题词条集和文本词条集;
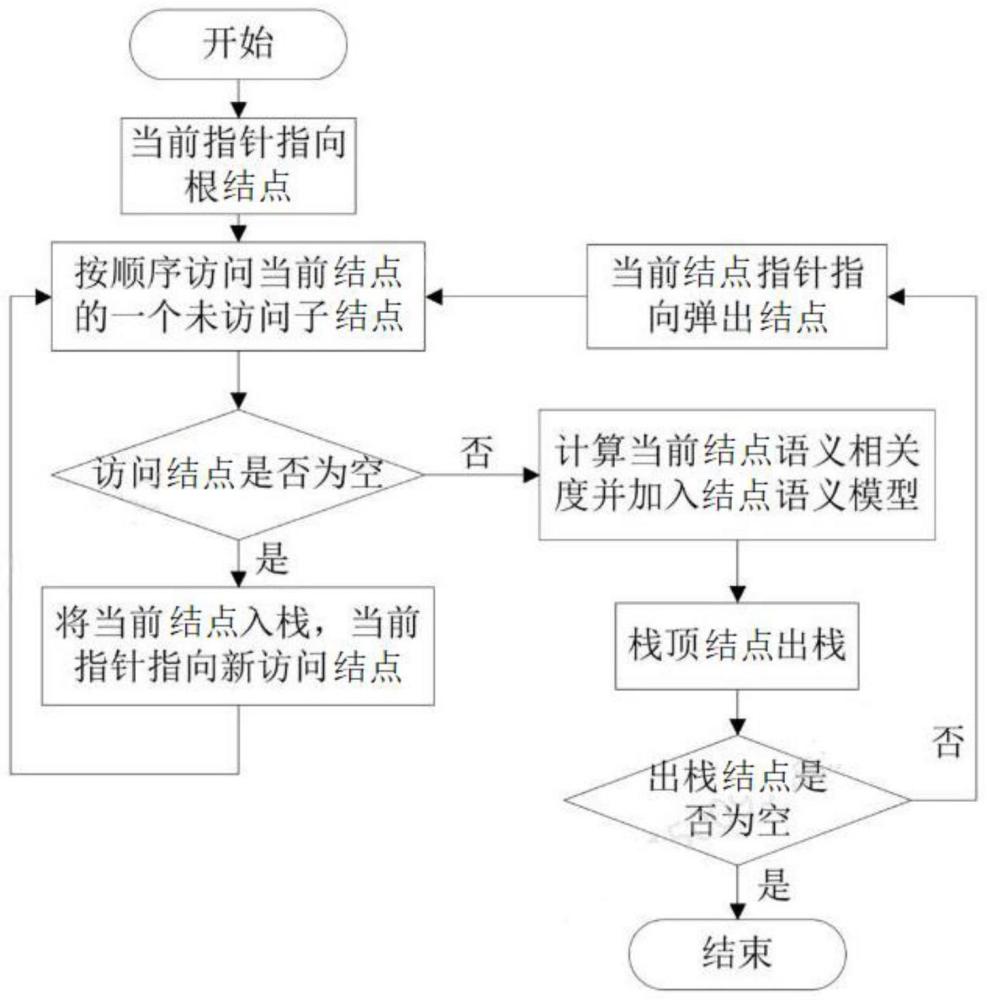
66、3)差异性词义匹配:将语义噪声分为无义词噪声和无关词噪声,无义词噪声为汉语词性中的虚词,也可人为界定添加与处理需求无关的词汇,如果主题词集和文本词集里包含停用词表里的词条,则进行清洗剔除;
67、无关词噪声是词性偏差过大的词条,在构造词集时添加词性属性,就是为了此时进行无关词噪声剔除,只在关键词集和文本词集中比对相同词性的词条,忽略掉无关词之间的语义噪声干扰,实现差异性词义匹配;
68、4)结点语义关联度计算:比对去除停用词的关键词集和文本词集,依次比对词集中的词条,如果不是无关噪声词,则计算其近似度simi(i为关联词对序号),所比对的关联词对数记为n,词集结点文本与自定义主题的关联度公式为:
69、
70、在网页构造树中,分为叶子结点ln和非叶子结点nln,叶子结点自身文本即其包含的全部主题内容,非叶子结点包含的主题内容则为其包括所有结点的内容,其结点语义关联度的计算有差异:
71、1-)对于叶子结点ln,其结点语义关联度即其自身文本与自定义主题的关联度,则叶子结点的语义关联度公式为:
72、
73、2-)对于非叶子结点,为其孩子结点语义关联度的均值,对于孩子数量为n的非叶子结点,孩子结点为nchildi(i为孩子序号),则其语义关联度公式为:
74、
75、叶子结点为ln,非叶子结点为nln。
76、优选地,后序构造结点语义模型:以map集合构建构造树结点与结点关联度的映射关系,map集合key值为结点,value值为对应语义关联权重,此映射集合和原构造树共同表示结点语义模型,从叶子结点向上构造结点语义模型,利用后序遍历构造结点语义模型,保证每个结点在计算语义关联度时,其子结点都已完成计算且存放在结点语义模型中;
77、步骤一:当前指针指向根结点;
78、步骤二:判定当前结点是否存在未访问子结点;
79、步骤三:如果存在,当前结点入栈,当前指针指向首个未访问子结点,继续执行步骤二;如果不存在,计算当前结点语义关联度并加入结点语义模型;
80、步骤四:栈顶结点出栈,如果非空,则当前指针指向弹出结点,继续执行步骤二;如果为空,构造算法结束;
81、对构造树结点逆序访问,计算每个非叶子结点的语义关联度时,其孩子结点的关联度均计算完毕并存放在结点语义模型,结点语义模型的每个结点标注关联度值,并保留原构造树构造。
82、优选地,剪枝遍历结点语义模型提取主题:在结点语义模型的构造中,上层结点与深层结点,为包含关系,若上层语义结点符合需求,则语义结点包含的所有语义簇均为所需主题,无需重复验证提取;若上层语义结点不符合要求,则向其深层继续验证是否符合提取要求;
83、通过剪枝遍历语义结点集,实现关联主题的提取:
84、步骤1:结点语义模型顶层结点进入验证队列;
85、步骤2:提取验证队列首结点,若结点语义关联度小于自定义主题临界值,则所有子结点加入验证队列;若结点语义关联度大于自定义主题临界值,对结点剪枝,子结点不加入验证队列,该结点自身加入主题结点集;
86、步骤3:验证队列不为空时,重复步骤2,直到验证队列的结点验证完毕;
87、步骤4:遍历主题结点集合,对于每个主题结点,访问结点所有子结点内容,实现关联主题提取。
88、与现有技术相比,本技术的创新点和优势在于:
89、(1)本技术提出了语义大数据驱动的自定义网页主题提取方法,对于从互联网提取的网页资源,采用简洁高效的构造树生成算法,构造网页层次模型。在层次化的网页构造树基础上,对网页内容进行噪声块识别和去噪,去除了网页表达形式和主题噪声,保留主题内容层次和内容元素。在最核心的主题提取模块,构建了词条含义近似度算法、结点语义相关度的算法、结点语义模型构造算法和主题结点集的提取算法。实现在用户给定自定义主题的情况下,从海量互联网原始网页中提取所需的自定义主题内容。提高了人们在阅读网页时的效率,剔除了网页内繁杂的网页元素、目不暇接的推广信息和用户不关心的主题内容,让用户根据需求自定义主题,直接提取自己需要阅读的内容,算法效率较高,具有较好的稳定性、鲁棒性与实用性。
90、(2)本技术提出了生成网页构造树算法,首先对所获取网页进行规范化处理,使网页编码符合规整;然后进行噪声信息预过滤,去除网页表达形式噪声;之后依据网页层次构造出构造树模型。提出了主题噪声块摘除方法,在层次化的网页构造树基础上,利用调节枝叶匹配算法识别疑似噪声区域;通过计算链接构造平衡对疑似簇进行筛选,摘除经确认的噪声块,使构造树只保留主题内容层次和主题内容元素。提出了语义大数据关联度的网页主题提取,将结点文本作为网页的本底内容单位,结合结点文本的语义相关性和主题结点构成主题内容的构造层次规律,构建出结点语义模型对网页内容进行解析。突破了传统语义分析应用于非构造文本的局限性,实现了对网页半构造化文本进行语义分析和主题提取。定义词条近似度并实现了词条近似度算法;构建结点语义相关度并实现差异性词义匹配算法降低语义噪声的影响,准确反映结点文本和自定义主题的含义相关程度;构造结点语义模型;最后剪枝遍历主题结点集实现主题提取,实现了基于用户自定义的主题提取内容并取得了良好的实践效果。同时能为比价应用、舆情分析系统、推荐算法、信息情报系统提供网页信息提取的底层支持。
91、(3)本技术的创新点还包括,一是提出了将结点文本作为网页的本底内容单位,结合结点文本的语义关联性和主题结点构成主题内容的构造层次规律,构建出结点语义模型对网页内容进行分析操作,突破了传统语义分析应用于非构造文本的局限性,实现了对网页半构造化文本进行语义分析和主题提取。二是提出了差异性词义匹配进行结点语义关联度的计算,降低了语义噪声的影响,较准确的反映出结点文本和自定义主题的含义关联程度。让用户根据阅读需求自定义主题词或主题句,然后基于语义相关性在互联网中提取用户所需的主题,直接将读者所需的信息以最简洁的方式呈现出来,用户自定义主题内容提取效果较好。
- 还没有人留言评论。精彩留言会获得点赞!