跨模态关系感知的暴力行为检测方法及系统
本发明涉及监控视频异常检测领域,具体涉及一种跨模态关系感知的暴力行为检测方法及系统。
背景技术:
1、随着社会不断发展和人们对公共安全的日益关注,预防和打击暴力行为的需求变得越来越迫切。辱骂、打架、斗殴和枪击等暴力行为不仅会对个人身心健康产生负面影响,而且对整个社会的公共安全构成了严重威胁。因此,对公共场所的监控侦测和防止这些犯罪行为变得越来越重要。
2、然而,现有的监控系统主要依赖人工检查,导致监测效率低下和误报率高,同时报警设备的功能也受限,长时间监控大量视频内容很容易使安保人员工作效率降低,这影响了监控的有效性。因此,应该开发高效、准确的自动暴力检测方法及系统,能够自动识别和报警针对暴力行为的事件。
技术实现思路
1、本发明要解决的技术问题是克服现有技术的缺陷,提供一种跨模态关系感知的暴力行为检测方法,它可以同时处理视频和音频数据,并通过结合它们的视觉和音频信息来捕捉时序相关性,更全面地理解和识别视频中的暴力事件,提高暴力检测的准确性和鲁棒性。
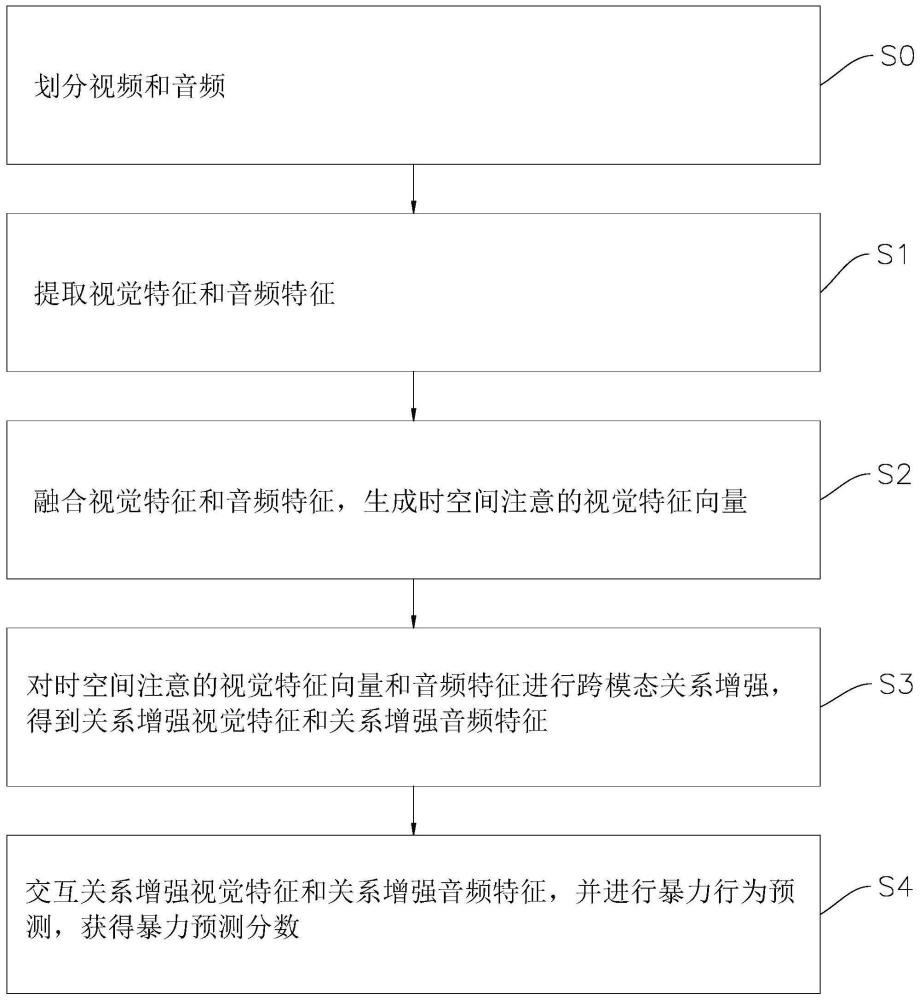
2、为了解决上述技术问题,本发明的技术方案是:一种跨模态关系感知的暴力行为检测方法,方法包括:
3、s1,从对应的视频片段和音频片段中提取视觉特征和音频特征
4、s2,融合所述视觉特征和所述音频特征生成时空间注意的视觉特征向量
5、s3,对所述时空间注意的视觉特征向量和所述音频特征进行跨模态关系增强,得到关系增强视觉特征和关系增强音频特征
6、s4,交互所述关系增强视觉特征和所述关系增强音频特征并进行暴力行为预测,获得暴力预测分数ys。
7、进一步,方法还包括:
8、s0,将视频划分为不重叠的多个视频片段,将音频划分为重叠的多个音频片段,每个音频片段与对应的视频片段的结尾对齐。
9、进一步,s2具体包括:
10、s21,先使用非线性全连接层将音频特征和视觉特征投影到相同维度dv,随后通过逐元素乘法融合,最后通过全局平均池化在时间维度上压缩融合特征,输出时间注意力图具体如公式(1)所示:
11、
12、其中,表示逐元素乘法,σ表示sigmoid函数,δavg表示全局平均池化,w1为可学习的参数,与是音频、视频全连接层;
13、s22,利用时间注意力图对视觉特征进行加权求和,得到音频引导的时间注意力特征具体如公式(2)所示;
14、
15、s23,通过时间注意力模块后的音频引导的时间注意力特征输入到空间注意力模块,得到音频引导的空间注意力特征和空间注意力图具体如公式(3)所示;
16、
17、其中,w2为可学习的参数,为空间全连接层,conv为卷积核大小为1的一维卷积;
18、s24,利用空间注意力图对音频引导的时间注意力特征进行加权求和,产生时空间注意的视觉特征向量作为输出,如公式(4)所示:
19、
20、进一步,步骤s3中,得到关系增强视觉特征的具体步骤为:
21、s31,通过线性层变换将时空间注意的视觉特征向量投影到查询特征中,所述查询特征表示为dm为隐藏层的维数,将时空间注意的视觉特征向量与音频特征xa连接起来以获得融合记忆特征将融合记忆特征mav通过线性层变换为键值特征和数值特征具体计算如公式(5)所示;
22、
23、其中wq,wk,与wv均为可学习参数,gij为自适应位置先验,具体计算为:
24、gij=exp(-|wg(i-j)2+b|) (6)
25、其中i与j表示片段的相对距离,wg与b是两个可学习参数,分别用于控制中心位置的邻域和调整当前片段的权重;
26、s32,输出关系增强视觉特征具体计算如公式(7)所示;
27、
28、进一步,s4具体包括:
29、s41,通过逐元素乘法将关系增强音频特征和关系增强视觉特征进行融合,得到联合特征xav;
30、s42,将关系增强音频特征和关系增强视觉特征拼接并和联合特征xav一起送入cmre模块,以提升对视觉信息和音频信息的理解和感知能力,输出增强特征xh;
31、s43,将增强特征xh输入mlp以捕获高级语义;
32、s44,使用时间卷积层捕获历史观测值并获得预测分数其中,
33、总体过程表示如公式(9)所示;
34、
35、其中,σ表示sigmoid函数,conv(·)表示卷积核大小为k的1d卷积,mlp(·)为多层感知机,cmre(·)为跨模态关系增强模块,concat(·)为连接操作,为逐元素乘法,b′为可学习参数,最后输出暴力预测分数
36、进一步,s1中,采用预训练的i3d模型提取视频片段中的视觉特征采用预训练的vggish模型提取音频片段中的音频特征
37、本发明还提供了一种跨模态关系感知的暴力行为检测系统,包括:
38、特征提取模块,用于从对应的视频片段和音频片段中提取视觉特征和音频特征
39、音频引导的时空注意力模块,用于融合所述视觉特征和所述音频特征生成时空间注意的视觉特征向量
40、跨模态关系增强模块,用于对所述时空间注意的视觉特征向量和所述音频特征进行跨模态关系增强,得到关系增强视觉特征和关系增强音频特征
41、音视频交互模块,用于交互所述关系增强视觉特征和所述关系增强音频特征并进行暴力行为预测,获得暴力预测分数ys。
42、采用上述技术方案后,本发明提出的跨模态关系增强的查询源自单独的一种模态,而键和值则源自输入的两种模态,通过这种方式,来自一种模态的单个片段可以根据学习到的模态内和模态间关系聚合来自两种模态的所有相关片段的有用信息。此外,本发明利用音视频交互来融合跨模态增强的视觉特征和音频特征,能够更全面、准确地表达跨模态信息,并从音视频数据中发现更深层次的关联和语义信息。综上,本发明可以同时处理视频和音频数据,并通过结合它们的视觉和音频信息来捕捉时序相关性,更全面地理解和识别视频中的暴力事件,提高暴力检测的准确性和鲁棒性。
技术特征:
1.一种跨模态关系感知的暴力行为检测方法,其特征在于,
2.根据权利要求1所述的跨模态关系感知的暴力行为检测方法,其特征在于,
3.根据权利要求1所述的跨模态关系感知的暴力行为检测方法,其特征在于,
4.根据权利要求1所述的跨模态关系感知的暴力行为检测方法,其特征在于,
5.根据权利要求1所述的跨模态关系感知的暴力行为检测方法,其特征在于,
6.根据权利要求1所述的跨模态关系感知的暴力行为检测方法,其特征在于,
7.一种跨模态关系感知的暴力行为检测系统,其特征在于,
技术总结
本发明涉及监控视频异常检测领域,具体涉及一种跨模态关系感知的暴力行为检测方法及系统,方法包括:S1,从对应的视频片段和音频片段中提取视觉特征和音频特征S2,融合所述视觉特征和所述音频特征生成时空间注意的视觉特征向量S3,对所述时空间注意的视觉特征向量和所述音频特征进行跨模态关系增强,得到关系增强视觉特征和关系增强音频特征S4,交互所述关系增强视觉特征和所述关系增强音频特征并进行暴力行为预测,获得暴力预测分数y<supgt;S</supgt;。本发明可以同时处理视频和音频数据,并通过结合它们的视觉和音频信息来捕捉时序相关性,更全面地理解和识别视频中的暴力事件,提高暴力检测的准确性和鲁棒性。
技术研发人员:李志新,朱子蒙
受保护的技术使用者:常州大学
技术研发日:
技术公布日:2024/3/27
- 还没有人留言评论。精彩留言会获得点赞!