一种基于语言大模型和视觉编码器的多模态网络谣言检测方法
本发明属于自然语言处理,具体涉及一种基于语言大模型和视觉编码器的多模态网络谣言检测方法。
背景技术:
1、随着新媒体时代信息媒介的多元化发展,各种内容大量活跃在媒体内中,与此同时各类虚假信息也充斥着社交媒体,影响着公众的判断和决策。因此,及时辨别和纠正虚假信息是一项迫切的任务。
技术实现思路
1、针对现有技术存在的缺陷和不足,本发明提供一种基于语言大模型和视觉编码器的多模态网络谣言检测方法。
2、为了解决现有技术信息分辨的难题,本发明借助了大数据分析和人工智能技术,通过分析海量的文本、图像等多模态信息,开发了一系列先进的算法和模型,旨在帮助识别和消除虚假信息。通过自动分析信息的来源、内容、上下文等关键因素,以确定信息的真实性。如果实现能够发现虚假信息,可以进一步采取相应的措施,包括标记、删除或提供真实信息,以确保用户获得准确、可信的信息。
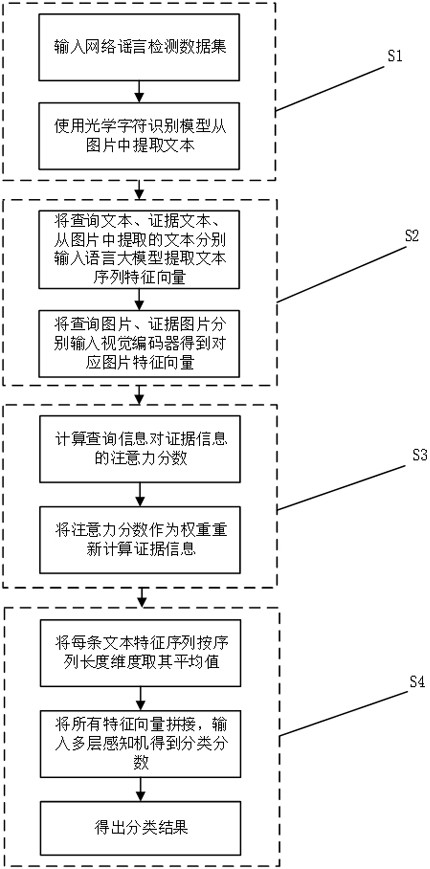
3、其首先获取网络谣言检测数据集,将其中所有图片通过光学字符识别模型提取为文本,然后把查询文本、证据文本、从图片中提取的文本分别输入语言大模型得到对应的文本特征序列向量,把查询图片、证据图片分别输入视觉编码器得到对应的图片特征向量。通过多头注意力机制,计算查询信息对证据信息的注意力分数,并将其作为权重重新计算证据信息。随后将每条文本特征序列按序列长度维度取其平均值作为代表信息,最后将图片特征向量、请查询本特征向量、证据文本特征向量拼接,输入多层感知机后得出分类结果。
4、本发明解决其技术问题具体采用的技术方案是:
5、一种基于语言大模型和视觉编码器的多模态网络谣言检测方法,包括以下步骤:
6、步骤s1:获取网络谣言检测数据集,使用光学字符识别模型将数据集中图片内含文字提取为可处理的文本;
7、步骤s2:使用经过预训练的带有编码功能的语言大模型,将查询文本、证据文本以及从图片中提取的文本分别输入语言大模型提取文本序列特征向量,并将请求图片、证据图片分别输入视觉编码器模型,得到对应图片特征向量;
8、步骤s3:使用注意力机制,计算所有查询信息对证据信息的注意力分数,并根据注意力分数作为权重重新计算证据信息;
9、步骤s4:将查询信息与经过注意力机制计算的证据信息的特征向量按序列长度维度取平均值作为代表信息,并且将其拼接为单条向量,将其输入到多层感知机中,得到分类分数,最后得出分类结果。
10、进一步地,步骤s1具体包括以下步骤:
11、步骤s11:获取网络谣言检测数据集,进行数据预处理,以完成标签提取,其中包括查询文本q_text、查询图片q_img、证据文本e_text、证据图片e_img;
12、步骤s12:载入光学字符识别模型,输入查询图片q_img、证据图片e_img,从图片中提取查询图片内含文本q_img_text、证据图片内含文本e_img_text,具体计算方式如下:
13、q_img_text=ocr(q_img)
14、e_img_text=ocr(e_img)
15、其中ocr表示光学字符识别模型。
16、进一步地,步骤s2具体包括以下步骤:
17、步骤s21:载入经过预训练的带有编码功能的语言大模型lm,将查询文本q_text、证据文本e_text、查询图片内含文本q_img_text、证据图片内含文本e_img_text作为输入,得到其对应的文本序列特征向量,具体计算方式如下:
18、qt_emb=lm(q_text)
19、et_emb=lm(e_text)
20、qit_emb=lm(q_img_text)
21、eit_emb=lm(e_img_text)
22、qt_emb,qit_emb∈r1×l_num×l_dim
23、
24、
25、其中qt_emb表示查询文本特征向量,et_emb表示证据文本特征向量,qit_emb表示查询图片内含文本特征向量,eit_emb表示证据图片内含文本特征向量,l_num表示语言模型支持的最大文本长度,l_dim代表语言模型的向量维度大小,net表示证据文本数量,nei表示证据图片数量;
26、步骤s22:载入经过预训练的视觉编码器模型vm,将请求图片q_img、证据图片e_img作为输入,得到其对应的图片特征向量,具体计算方式如下:
27、qi_emb=vm(q_img)
28、ei_emb=vm(e_img)
29、qi_emb∈r1×v_num×v_dim
30、ei_emb∈rn_ei×v_num×v_dim
31、其中qi_emb表示查询图片特征向量,ei_emb表示证据图片特征向量,v_num表示视觉编码器模型序列长度、v_dim代表视觉编码器模型的向量维度大小。
32、进一步地,步骤s3具体包括以下步骤:
33、步骤s31:根据步骤s21、步骤s22得出的特征向量,使用注意力机制,计算查询文本特征向量qt_emb、查询图片内含文本特征向量qit_emb、查询图片特征向量qi_emb对证据文本特征向量et_emb、证据图片内含文本特征向量eit_emb、证据图片特征向量ei_emb的注意力分数,具体计算方式如下:
34、attn_qet=attention(qt_emb,et_emb)
35、attn_qeit=attention(qt_emb,eit_emb)
36、attn_qitet=attention(qit_emb,et_emb)
37、attn_qiteit=attention(qit_emb,eit_emb)
38、attn_qiei=attention(qi_emb,ei_emb)
39、其中,attn_qet表示查询文本特征向量qt_emb对证据文本特征向量et_emb的注意力分数,attn_qeit表示查询文本特征向量qt_emb对证据图片内含文本特征向量eit_emb的注意力分数,attn_qitet表示查询图片内含文本特征向量qit_emb对证据文本特征向量et_emb的注意力分数,attn_qiteit表示查询图片内含文本特征向量qit_emb对证据图片内含文本特征向量eit_emb的注意力分数,attn_qiei表示查询图片特征向量qi_emb对证据图片特征向量ei_emb的注意力分数,attention(·,·)操作表示为:
40、
41、
42、其中dk表示k的维度;
43、步骤s32:根据步骤s31计算的注意力分数作为权重,重新计算证据信息,具体计算过程如下:
44、qet=attn_qet*et_emb
45、qeit=attn_qeit*eit_emb
46、qitet=attn_qitet*et_emb
47、aiteit=attn_qiteit*eit_emb
48、qiei=attn_qiei*ei_emb
49、其中qet、qitet表示据文本特征向量et_emb经过注意力计算后的特征向量,
50、qeit、qiteit表示证据图片内含文本特征向量eit_emb经过注意力计算后的特征向量,qiei表示图片特征向量ei_emb经过注意力计算后的特征向量。
51、进一步地,步骤s4具体包括以下步骤:
52、步骤s41:将查询信息与s32得出的证据信息拼接为单条向量,并按其序列长度维度取平均值作为代表信息,具体计算如下:
53、all=cat(qt_emb,qit_emb,qi_emb,qet,qeit,qitet,aiteit,qiei)
54、feature=mean(all)
55、其中cat(·)表示拼接操作,mean(·)表示取平均值操作,all表示将所有特征向量按序列维度进行对齐拼接后的特征向量,feature表示最后用于表示整条查询证据信息的特征向量;
56、步骤s42:将步骤s41得出的特征向量输入到多层感知机中,得到分类分数,具体计算过程如下:
57、logits=mlp(feature)
58、其中mlp(·)操作为多层感知机,表示为:
59、mlp(x)=fc(wax)
60、其中,fc(·)为激活函数,w_a表示可学习的权重矩阵;
61、步骤s43:根据步骤s42得出的分类分数,得出分类结果,具体计算过程如下:
62、label=argmax(logits)
63、其中,label表示分类结果:0表示为非谣言、1表示为谣言、2表示为不可判断,argmax(·)表示获取矩阵最大值索引操作。
64、以及,一种基于语言大模型和视觉编码器的多模态网络谣言检测系统,其特征在于:基于计算机系统,在运行时使用如上所述的基于语言大模型和视觉编码器的多模态网络谣言检测方法。
65、以及,一种非暂态计算机可读存储介质,其上存储有计算机程序,其特征在于:在运行时使用如上所述的基于语言大模型和视觉编码器的多模态网络谣言检测方法。
66、相比于现有技术,本发明及其优选方案至少具有以下有益效果:
67、1、高效的谣言检测能力:构建了一种基于先进的注意力计算和查询证据特征向量信息提取网络,能够高效准确地识别和定位网络谣言中的关键信息和特征。这有助于提高网络谣言检测的准确率和效率。
68、2、与其他谣言检测方法不同,仅需要使用文本的类别标注信息,无需额外的繁琐标注,降低了数据准备和标记的复杂性。
69、3、针对网络谣言的特殊性质,充分利用文本中的细微差异和特征信息,如文本的复杂结构和情感特征,从而提供了关键的识别信息,有助于更准确地检测网络谣言。
70、4、网络谣言往往具有相似的语言结构和上下文关联,考虑了准确和多样化的文本局部区域定位,并提取了局部区域之间的结构语义信息。这一特点有助于降低网络谣言检测中不同谣言之间的混淆,提高了检测的精确性。
- 还没有人留言评论。精彩留言会获得点赞!