检测大规模语言模型是否使用预设数据集进行训练的方法与流程
本技术涉及数据处理的,具体提供一种检测大规模语言模型是否使用预设数据集进行训练的方法、装置及介质。
背景技术:
1、语言模型在自然语言处理(nlp)任务中被广泛应用,如情感分析、实体命名识别、问答等。然而,人们越来越担心这些模型可能被滥用,尤其是在未经适当授权的情况下,使用了敏感或专有数据进行训练。
2、现有的用于检测大规模语言模型是否使用特定的训练数据集进行训练的方法存在一定的局限性。因此,需要一种新的方法来可靠地检测和确认大规模语言模型是否使用了特定的训练数据集,从而保护公司的财产安全和确立数据的隐私保护。
3、相应地,本领域需要一种新的检测大规模语言模型是否使用预设数据集进行训练的方案来解决上述问题。
技术实现思路
1、为了克服上述缺陷,提出了本技术,以提供解决或至少部分地解决如何判断大规模语言模型是否使用预设数据集进行训练的技术问题。
2、在第一方面,本技术提供一种检测大规模语言模型是否使用预设数据集进行训练的方法,所述方法包括:
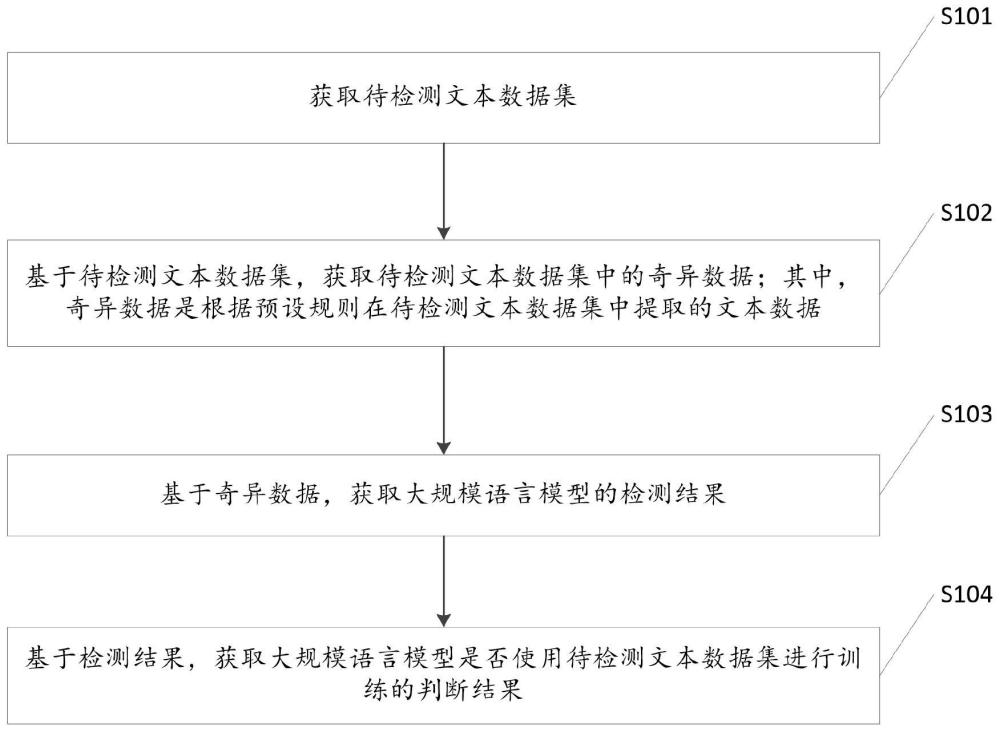
3、获取所述待检测文本数据集;
4、基于所述待检测文本数据集,获取所述待检测文本数据集中的奇异数据;其中,所述奇异数据是根据预设规则在所述待检测文本数据集中提取的文本数据;
5、基于所述奇异数据,获取所述大规模语言模型的检测结果;
6、基于所述检测结果,获取所述大规模语言模型是否使用所述待检测文本数据集进行训练的判断结果。
7、在上述检测大规模语言模型是否使用预设数据集进行训练的一个技术方案中,所述检测结果包括一致性检验结果;
8、所述基于所述奇异数据,获取所述大规模语言模型的检测结果,包括:
9、根据每个所述奇异数据构造与所述奇异数据对应的自然语言处理任务;
10、将构造的所述自然语言处理任务通过所述大规模语言模型进行检测,得到所述大规模语言模型的输出结果;
11、基于所述输出结果和所述奇异数据,获取所述一致性检验结果。
12、在上述检测大规模语言模型是否使用预设数据集进行训练的一个技术方案中,所述基于所述输出结果和所述奇异数据,获取所述一致性检验结果,包括:
13、针对每个奇异数据,判断所述输出结果是否与对应的所述奇异数据相同;
14、获取所述输出结果与所述对应的奇异数据相同的所述奇异数据的个数;
15、将所述个数在所述奇异数据的总个数中占的比例,作为所述一致性检验结果。
16、在上述检测大规模语言模型是否使用预设数据集进行训练的一个技术方案中,所述基于所述检测结果,获取所述大规模语言模型是否使用所述待检测文本数据集进行训练的判断结果,包括:
17、判断所述一致性检验结果是否大于第一预设阈值;
18、若是,则判定所述大规模语言模型使用所述待检测文本数据集进行训练;
19、若否,则判定所述大规模语言模型未使用所述待检测文本数据集进行训练。
20、在上述检测大规模语言模型是否使用预设数据集进行训练的一个技术方案中,所述检测结果包括特征分析结果;
21、所述基于所述奇异数据,获取所述大规模语言模型的检测结果,包括:
22、基于所述待检测文本数据集,获取所述待检测文本数据集中的常规数据;其中,所述常规数据是所述待检测文本数据集中除所述奇异数据以外的数据;
23、将所述常规数据和所述奇异数据通过预先训练好的通用语言检测模型进行特征提取,得到第一特征提取结果;其中,所述通用语言检测模型未使用所述奇异数据进行训练;
24、将所述常规数据和所述奇异数据通过所述大规模语言模型进行特征提取,得到第二特征提取结果;
25、基于所述第一特征提取结果和所述第二特征提取结果,获取所述特征分析结果。
26、在上述检测大规模语言模型是否使用预设数据集进行训练的一个技术方案中,所述第一特征提取结果包括所述常规数据的第一特征和所述奇异数据的第一特征;所述第二特征提取结果包括所述常规数据的第二特征和所述奇异数据的第二特征;
27、所述基于所述第一特征提取结果和所述第二特征提取结果,获取所述特征分析结果,包括:
28、基于所述常规数据的第一特征和所述奇异数据的第一特征,获取第一特征相似度;
29、基于所述常规数据的第二特征和所述奇异数据的第二特征,获取第二特征相似度;
30、获取所述第二特征相似度和所述第一特征相似度的差值,作为所述特征分析结果。
31、在上述检测大规模语言模型是否使用预设数据集进行训练的一个技术方案中,所述基于所述检测结果,获取所述大规模语言模型是否使用所述待检测文本数据集进行训练的判断结果,包括:
32、判断所述特征分析结果是否大于第二预设阈值;
33、若是,则判定所述大规模语言模型使用所述待检测文本数据集进行训练;
34、若否,则判定所述大规模语言模型未使用所述待检测文本数据集进行训练。
35、在上述检测大规模语言模型是否使用预设数据集进行训练的一个技术方案中,所述基于所述第一特征提取结果和所述第二特征提取结果,获取所述特征分析结果,包括:
36、分别对所述常规数据的第一特征、所述奇异数据的第一特征、所述常规数据的第二特征和所述奇异数据的第二特征进行特征降维;
37、基于特征降维后的所述常规数据的第一特征、所述奇异数据的第一特征、所述常规数据的第二特征和所述奇异数据的第二特征,获取所述特征分析结果。
38、在上述检测大规模语言模型是否使用预设数据集进行训练的一个技术方案中,所述基于所述检测结果,获取所述大规模语言模型是否使用所述待检测文本数据集进行训练的判断结果,包括:
39、通过可视化分析方法,对所述特征分析结果中特征降维后的所述常规数据的第一特征、所述奇异数据的第一特征、所述常规数据的第二特征和所述奇异数据的第二特征的分布情况进行分析,以获得所述判断结果。
40、在上述检测大规模语言模型是否使用预设数据集进行训练的一个技术方案中,所述基于所述待检测文本数据集,获取所述待检测文本数据集中的奇异数据,包括:
41、基于所述预设规则,对所述待检测文本数据集进行数据挖掘,以获取所述奇异数据;
42、其中,所述数据挖掘包括数据频率分析挖掘、机器学习挖掘、人工挖掘、专家知识挖掘、统计挖掘中的至少一种。
43、在第二方面,提供一种控制装置,该控制装置包括至少一个处理器和至少一个存储装置,所述存储装置适于存储多条程序代码,所述程序代码适于由所述处理器加载并运行以执行上述检测大规模语言模型是否使用预设数据集进行训练的方法的技术方案中任一项技术方案所述的检测大规模语言模型是否使用预设数据集进行训练的方法。
44、在第三方面,提供一种计算机可读存储介质,该计算机可读存储介质其中存储有多条程序代码,所述程序代码适于由处理器加载并运行以执行上述检测大规模语言模型是否使用预设数据集进行训练的方法的技术方案中任一项技术方案所述的检测大规模语言模型是否使用预设数据集进行训练的方法。
45、本技术上述一个或多个技术方案,至少具有如下一种或多种
46、有益效果:
47、在实施本技术的技术方案中,本技术通过获取待检测文本数据集,基于待检测文本数据集,获取待检测文本数据集中的奇异数据,其中,奇异数据是根据预设规则在待检测文本数据集中提取的文本数据,基于奇异数据,获取大规模语言模型的检测结果,基于检测结果,获取大规模语言模型是否使用待检测文本数据集进行训练的判断结果。通过上述配置方式,首先,通过待检测文本数据集获取奇异数据,再根据奇异数据,获取大规模语言模型的检测结果,通过检测结果可以确定大规模语言模型是否使用奇异数据进行训练,进而通过检测结果能够准确判断大规模语言模型是否使用预设数据集进行训练。
48、方案1.一种检测大规模语言模型是否使用预设数据集进行训练的方法,其特征在于,所述方法包括:
49、获取所述待检测文本数据集;
50、基于所述待检测文本数据集,获取所述待检测文本数据集中的奇异数据;其中,所述奇异数据是根据预设规则在所述待检测文本数据集中提取的文本数据;
51、基于所述奇异数据,获取所述大规模语言模型的检测结果;
52、基于所述检测结果,获取所述大规模语言模型是否使用所述待检测文本数据集进行训练的判断结果。
53、方案2.根据方案1所述的检测大规模语言模型是否使用预设数据集进行训练的方法,其特征在于,所述检测结果包括一致性检验结果;
54、所述基于所述奇异数据,获取所述大规模语言模型的检测结果,包括:
55、根据每个所述奇异数据构造与所述奇异数据对应的自然语言处理任务;
56、将构造的所述自然语言处理任务通过所述大规模语言模型进行检测,得到所述大规模语言模型的输出结果;
57、基于所述输出结果和所述奇异数据,获取所述一致性检验结果。
58、方案3.根据方案2所述的检测大规模语言模型是否使用预设数据集进行训练的方法,其特征在于,
59、所述基于所述输出结果和所述奇异数据,获取所述一致性检验结果,包括:
60、针对每个奇异数据,判断所述输出结果是否与对应的所述奇异数据相同;
61、获取所述输出结果与所述对应的奇异数据相同的所述奇异数据的个数;
62、将所述个数在所述奇异数据的总个数中占的比例,作为所述一致性检验结果。
63、方案4.根据方案3所述的检测大规模语言模型是否使用预设数据集进行训练的方法,其特征在于,
64、所述基于所述检测结果,获取所述大规模语言模型是否使用所述待检测文本数据集进行训练的判断结果,包括:
65、判断所述一致性检验结果是否大于第一预设阈值;
66、若是,则判定所述大规模语言模型使用所述待检测文本数据集进行训练;
67、若否,则判定所述大规模语言模型未使用所述待检测文本数据集进行训练。
68、方案5.根据方案1所述的检测大规模语言模型是否使用预设数据集进行训练的方法,其特征在于,所述检测结果包括特征分析结果;
69、所述基于所述奇异数据,获取所述大规模语言模型的检测结果,包括:
70、基于所述待检测文本数据集,获取所述待检测文本数据集中的常规数据;其中,所述常规数据是所述待检测文本数据集中除所述奇异数据以外的数据;
71、将所述常规数据和所述奇异数据通过预先训练好的通用语言检测模型进行特征提取,得到第一特征提取结果;其中,所述通用语言检测模型未使用所述奇异数据进行训练;
72、将所述常规数据和所述奇异数据通过所述大规模语言模型进行特征提取,得到第二特征提取结果;
73、基于所述第一特征提取结果和所述第二特征提取结果,获取所述特征分析结果。
74、方案6.根据方案5所述的检测大规模语言模型是否使用预设数据集进行训练的方法,其特征在于,
75、所述第一特征提取结果包括所述常规数据的第一特征和所述奇异数据的第一特征;所述第二特征提取结果包括所述常规数据的第二特征和所述奇异数据的第二特征;
76、所述基于所述第一特征提取结果和所述第二特征提取结果,获取所述特征分析结果,包括:
77、基于所述常规数据的第一特征和所述奇异数据的第一特征,获取第一特征相似度;
78、基于所述常规数据的第二特征和所述奇异数据的第二特征,获取第二特征相似度;
79、获取所述第二特征相似度和所述第一特征相似度的差值,作为所述特征分析结果。
80、方案7.根据方案6所述的检测大规模语言模型是否使用预设数据集进行训练的方法,其特征在于,所述基于所述检测结果,获取所述大规模语言模型是否使用所述待检测文本数据集进行训练的判断结果,包括:
81、判断所述特征分析结果是否大于第二预设阈值;
82、若是,则判定所述大规模语言模型使用所述待检测文本数据集进行训练;
83、若否,则判定所述大规模语言模型未使用所述待检测文本数据集进行训练。
84、方案8.根据方案6所述的检测大规模语言模型是否使用预设数据集进行训练的方法,其特征在于,所述基于所述第一特征提取结果和所述第二特征提取结果,获取所述特征分析结果,包括:
85、分别对所述常规数据的第一特征、所述奇异数据的第一特征、所述常规数据的第二特征和所述奇异数据的第二特征进行特征降维;
86、基于特征降维后的所述常规数据的第一特征、所述奇异数据的第一特征、所述常规数据的第二特征和所述奇异数据的第二特征,获取所述特征分析结果。
87、方案9.根据方案8所述的检测大规模语言模型是否使用预设数据集进行训练的方法,其特征在于,所述基于所述检测结果,获取所述大规模语言模型是否使用所述待检测文本数据集进行训练的判断结果,包括:
88、通过可视化分析方法,对所述特征分析结果中特征降维后的所述常规数据的第一特征、所述奇异数据的第一特征、所述常规数据的第二特征和所述奇异数据的第二特征的分布情况进行分析,以获得所述判断结果。
89、方案10.根据方案1所述的检测大规模语言模型是否使用预设数据集进行训练的方法,其特征在于,所述基于所述待检测文本数据集,获取所述待检测文本数据集中的奇异数据,包括:
90、基于所述预设规则,对所述待检测文本数据集进行数据挖掘,以获取所述奇异数据;
91、其中,所述数据挖掘包括数据频率分析挖掘、机器学习挖掘、人工挖掘、统计挖掘中的至少一种。
92、方案11.一种控制装置,包括至少一个处理器和至少一个存储装置,所述存储装置适于存储多条程序代码,其特征在于,所述程序代码适于由所述处理器加载并运行以执行方案1至10中任一项所述的检测大规模语言模型是否使用预设数据集进行训练的方法。
93、方案12.一种计算机可读存储介质,其中存储有多条程序代码,其特征在于,所述程序代码适于由处理器加载并运行以执行方案1至10中任一项所述的检测大规模语言模型是否使用预设数据集进行训练的方法。
- 还没有人留言评论。精彩留言会获得点赞!