一种适用于电话录音和聊天记录的意图识别系统及其方法与流程
本发明属于人工智能,具体涉及一种适用于电话录音和聊天记录的意图识别系统及其方法。
背景技术:
1、人工智能(artificial intelligence,简称ai)是计算机科学的一个分支,旨在模拟和复制人类智能的行为和思维过程。人工智能技术背景涉及多个学科领域,包括计算机科学、数学、统计学、心理学等,在数学和统计学方面,人工智能技术背景涉及概率论、线性代数、优化理论等知识。这些数学和统计学方法为人工智能算法提供了理论基础和可行性分析。人工智能涉及多个学科领域的知识和技术,通过整合这些领域的成果,我们可以开发出具备智能能力的计算机系统,并应用于各种领域,如自然语言处理、图像识别、机器人等。
2、在现代社会中,电话通信是人们日常生活和商务交流不可或缺的方式之一。大部分电话通话可以由人工拨打或者通过人工智能(ai)自动拨打。然而,当通话结束后,往往无法获取与之交流的对话方的真实意图。例如,在商业环境中,无法准确把握客户的成交意愿等重要信息。这导致了人工处理电话录音和聊天记录的效率低下,同时增加了企业的运营成本。海量电话通话记录需要耗费大量时间和资源来进行人工意图识别,因此,需要提高人工处理电话记录的效率,同时也可以降低成本。现有的意图识别大部分还是依赖人工处理,效率低下,且意图识别技术的准确度不高,无法准确进行意图识别。
3、因此,亟需提供一种适用于电话录音和聊天记录的意图识别系统及其方法,以解决上述技术问题。
技术实现思路
1、针对相关技术中的问题,本发明提出一种适用于电话录音和聊天记录的意图识别系统及其方法,在现有训练模型的基础上,通过数据处理和模型的重复训练强化ai引擎的意图识别能力,以自动化方式对电话录音和聊天记录进行意图识别,快速了解用户的需求情况及原因,在处理海量电话通话记录时提高效率并降低成本。
2、本发明是这样实现的:
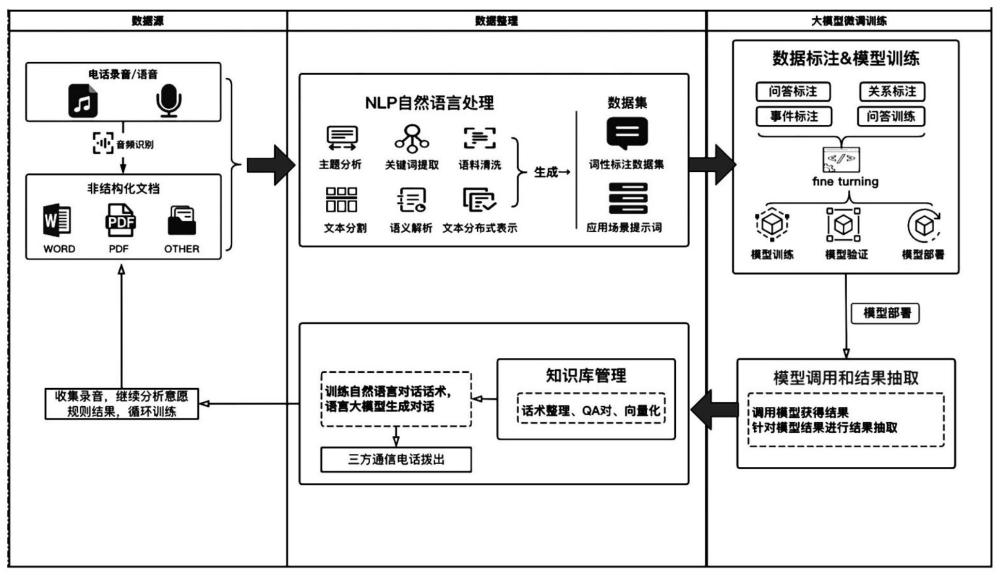
3、一种适用于电话录音和聊天记录的意图识别系统,包括:
4、数据收集模块,用于收集语音数据和聊天数据,并将语音数据和聊天数据转化为文本数据,文本数据为非结构化文档;所述数据收集模块还包括音频识别系统,通过音频识别系统将收集到的语音数据转化为文本数据;
5、数据处理模块,用于处理非结构化文档,并生成数据集;处理非结构化文档包括主题分析、关键词提取、语义解析;主题分析是对聊天记录的内容进行场景描绘;关键词提取是提取聊天记录中的不同状态的词语作为判断的关键词;语义解析是将聊天记录及场景和关键词进行解析并生成数据集;
6、模型训练模块,根据数据集对ai引擎进行数据标注和模型训练,以获得意图识别模型;
7、模型应用模块,将意图识别模型部署于模型应用模块中;
8、模型应用模块还包括测试模块,所述测试模块用于评估所述ai引擎是否达到预设期望目标;当所述ai引擎的预测结果达到预设期望目标时,所述ai引擎即为所述意图识别ai模型。
9、用户通过所述模型应用模块输入语音数据和聊天数据,所述模型应用模块接收并调用所述意图识别模型,对语音数据和聊天数据进行识别,获得模型识别结果;所述意图识别模型预设有若干个结果类别,模型应用模块将模型识别结果与若干个结果类别相互匹配,并抽取对应的结果类别。
10、语义解析技术的基本原理是将自然语言转化为计算机语言。这个过程需要涉及到自然语言处理和机器学习两个方面。自然语言处理是将自然语言转化为计算机语言的过程。这里有两个主要的环节:词法分析和句法分析。词法分析是将文本分解为单个字、词、或其他语言学领域的基本单元,句法分析是将单词组成的句子按照语法规则进行分析,从而得到一些信息,如句子的结构、主语、谓语等。然后,这两个方面的信息将被统一处理,构建形式语言表示,进而转化为计算机语言。
11、模型训练模块,通过标注后的数据对ai引擎进行模型训练,可以有效提高意图识别的准确率;经过实验测试,原始的ai引擎(如chatgpt、llama2或者国内的chatglm等)对意图识别的准确率大概为55%~60%,难以确切地识别出指定电话录音和聊天记录的真实意图,实际应用前景相当有限;经过强化训练后的ai引擎对意图识别的准确率超过85%,准确率大大提高了。
12、进一步的,还包括智能语言模块,所述智能语言模块包括知识库管理过程,所述知识库管理过程是根据模型识别结果与结果类别的匹配过程构建相应的文本交互模型,通过电话系统将所述文本交互模型翻译成语音并播放。
13、所述智能语言模块用于训练自然语言对话话术,并基于语言大模型生成对话;
14、进一步的,模型训练完后,只具备api调用的文本交互模型,需要借助第三方的电话系统,将文本翻译成语音并拨打出去,同时实现通话对话,ai负责确定回复,电话系统负责翻译成语音并播放。
15、进一步的,所述数据集包括词性标注数据集,将聊天记录中相同词性的内容提取后进行标注。
16、对话过程中会存在一些相同或近似意思表示的词语,通过词性标注数据集进行提炼并标注,比如在对话中出现关于体检原因的内容:居民说:“不够年龄/不够65岁/没有到65/没满65/不足六十五岁/不是老年人/年底才满65/还差几个月/我还没有到65”,则原因是:无65岁老人。
17、进一步的,所述模型训练模块中,向ai引擎输入数据集和场景提示词;
18、场景提示词为对聊天记录的场景进行描述,提出意图识别请求。
19、场景提示词由开发人员或用户提供;ai引擎对数据集的训练过程即是对数据的逻辑处理过程,对于较为成熟的第三方ai模型,直接输入场景提示词即可自动、快速的理解开发人员的数据处理需求,ai引擎可以根据场景提示词、利用数据集对自身进行特定方向的强化训练。
20、比如,我想请你担任自然语言处理专家,从输入给你的文本数据中分析数据,文本数据是来自广州的社区医院的电话机器人,打电话给居民邀请他们来参加体检,请逐行分析数据并提取居民的体检意愿。
21、进一步的,所述语音数据包括电话录音或语音,所述非结构化文档包括word和pdf。
22、进一步的,处理非结构化文档还包括语料清洗、文本分割和文本分布式表示;
23、语料清洗是删除聊天记录中的无关内容;
24、语料清洗去掉聊天记录中一些无关的内容可以降低干扰度。
25、文本分割是将大文本分割成小段文本;
26、通过文本分割将一整段大文本进行分割,切割成小段文本,方便数据处理模块进行分析。
27、文本分布式表示是对多个小段文本同时进行分析。
28、文本分布式表示与文本分割相结合,拆解成多个小段文本后,数据处理模块可以并行分析。
29、进一步的,处理非结构化文档为人工操作或nlp处理中的一种或组合。
30、natural language processing即nlp是一种通过计算机技术处理和分析人类语言的领域,常见的nlp处理任务包括文本分割、词性标注、文本分类、机器翻译、文本生成等等,前期会通过人工操作,后续再结合nlp进行自动处理,不断提高其准确率。
31、进一步的,所述模型训练模块中,所述ai引擎为第三方的预训练模型。
32、预训练模型,即已经被训练过的大语言模型,比如chatgpt、llama2或者国内的chatglm等,对输入的请求数据集进行训练,第三方的预训练模型较为成熟稳定,包括了大多数的场景,在此基础上进一步训练更加便捷,结果也会更为精确。
33、进一步的,所述模型训练为问答训练,根据数据标注提供的训练数据,通过ai引擎实现自动回答问题;所述数据标注包括问答标注、关系标注和事件标注;
34、问答标注是对于给定的问题和文本进行定义并标记关键词;比如,“什么是人工智能?”和“人工智能是一种模拟人类智能的技术。”,则问答标注将问题分类为“定义”,并标记出关键词“人工智能”。
35、关系标注是对于文本中的实体之间关系进行标注;比如,在一个文本中“苹果公司总部位于美国加利福尼亚州库比蒂诺市。”关系标注则涉及标记实体“苹果公司”和“美国加利福尼亚州库比蒂诺市”之间的关系为“总部所在地”。
36、事件标注是对文本中的事件类型、触发词以及参与者进行标注;比如,“罗杰·费德勒赢得了温网男单决赛。”事件标注包括识别事件类型为“体育比赛胜利”,指定触发词为“赢得”,标记参与者为“罗杰·费德勒”和“温网男单决赛”。
37、进一步的,问答标注相对于问答训练是一项数据准备任务,用于提供训练数据,为问答训练提供了必要的数据和信息基础。
38、进一步的,所述知识库管理过程包括话术整理、问答对话及向量化;
39、话术整理是通过话术库的问答数据形成完整的问答流程;比如,机器人提问:问题q1;居民回答:回复a1(或回复a2、a3、a4);机器人根据a1的回复继续提问b1,(相应的,如果居民回复a2,则提问b2);如同ai电话,以此种方式来构成完整的应答流程。
40、问答对话是用于优化对话过程中的语料格式;问答对话是用于ai模型训练的比较好的语料格式;
41、比如,{问:有运费险嘛?答:(有的姐姐)};
42、{问:为什么我申请不了运费险?答:(申请售后的时候会自动扣减,超出运费险范围外需要自费哦)};
43、{问:为什么还要我支付运费?答:(因为要等这边收到货验收没有问题退款的时候姐姐订单申请就好了)}。
44、向量化是将非数值型数据转换为数值型向量。向量化就是一个将自然语言翻译成机器语言的过程;在机器学习和自然语言处理等领域中,向量化是一种常见的数据预处理技术,用于将文本、图像、音频等非结构化或高维数据表示为数值型特征向量。常见的中文向量化工具有:word2vec、fasttext。
45、一种适用于电话录音和聊天记录的意图识别其方法,应用于上述的一种适用于电话录音和聊天记录的意图识别系统上,包括以下步骤:
46、s1、收集电话录音或语音,将其转化为非结构化文档;
47、s2、对非结构化文档进行处理,生成数据集;
48、s3、根据数据集对ai引擎进行数据标记和模型训练,以获得意图识别模型,所述意图识别模型预设有若干个结果类别,模型应用模块将模型识别结果与若干个结果类别相互匹配,并抽取对应的结果类别,并根据匹配结果进行模型验证;并将意图识别模型部署在模型应用模块中;
49、s4、用户通过所述模型应用模块输入电话录音或语音,所述模型应用模块接收并调用所述意图识别模型,对电话录音或语音进行识别,获得模型识别结果;
50、s5、根据模型识别结果与结果类别的匹配过程,从话书库调取相应的问答,构建相应的文本交互模型;
51、s6、将文本交互模型转化为语音并播放;再次收集电话录音或语音,重复执行s1,对意图识别模型持续优化。
52、与现有技术相比,本发明取得以下有益效果:
53、本发明提供了一种适用于电话录音和聊天记录的意图识别系统及其方法,涵盖了通过经过强化训练的人工智能(ai)对电话录音和聊天记录进行文本分析,以提取通话方的意图。
54、该系统旨在解决目前人工处理电话记录所面临的效率低、成本高的问题。本系统使用经过强化训练的人工智能算法,对通话方的意图进行准确分析和提取,该系统基于文本分析技术,能够自动处理海量电话录音和聊天记录,并从中提取出关键信息,如客户的成交意愿等,以自动化方式对电话录音和聊天记录进行意图识别。
55、与传统的人工意图识别方式相比,本系统具有显著优势。它不仅能够在短时间内处理大量通话记录,还能够提供更准确、一致的意图识别结果。通过使用经过强化训练的ai算法,本系统可以学习和适应各种通话场景,使其在多种情况下都能实现高效的意图识别。
56、本系统通过使用经过强化训练的ai算法,该系统能够自动化地对大量通话记录进行分析,提取关键信息并准确识别对话方的意图,解决目前人工处理电话记录所面临的效率低、成本高的问题,同时这将在商业环境中提高工作效率、降低成本,并为企业决策和客户服务提供更可靠的依据。
- 还没有人留言评论。精彩留言会获得点赞!