基于卷积神经网络-门控循环单元的暂态评估方法
本发明涉及电力系统暂态稳定分析,特别是一种基于卷积神经网络-门控循环单元的暂态评估方法。
背景技术:
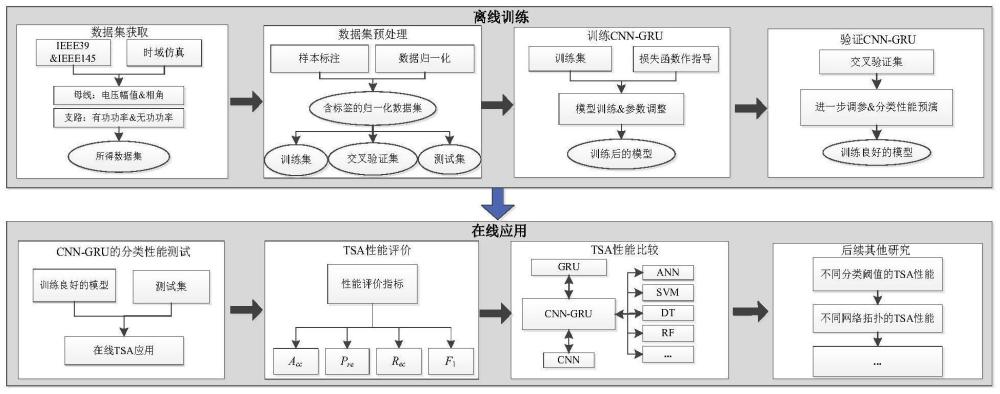
1、随着电力系统的快速发展以及大量可再生能源的不断接入,电力系统的正常运行面临着日益激增的风险以及挑战,系统在正常运行时遭受各种故障的影响,进而导致暂态失稳的可能性不断提高。一旦出现此问题并未采取控制措施,将直接导致发电机功角失步,严重时系统将解列崩溃,对大型企业的正常作业造成不可估计的损失;电力系统因故障导致暂态失稳的现象屡次发生,这些事故对电网的正常运行造成了极大冲击;现有技术的电力系统暂态稳定评估(transient stability assessment,tsa)技术中,存在单一模型导致特征提取存在局限性的问题,因此,需要设计一种基于卷积神经网络-门控循环单元的暂态评估方法来解决上述问题。
技术实现思路
1、本发明所要解决的技术问题是提供基于卷积神经网络-门控循环单元的暂态评估方法,综合考虑柔性负荷的运行特性和主动配电网不同时间尺度的运行需要,实现源网荷储的协同运行,为主动配电网的优化调度提供模型参考。
2、为实现上述技术效果,本发明所采用的技术方案是:
3、基于卷积神经网络-门控循环单元的暂态评估方法,包括:
4、s1,构建cnn卷积神经网络模型;
5、s2,构建gru门控循环单元结构;
6、s3,训练cnn+gru模型;
7、s4,输入数据预处理;
8、s5,稳态判据及样本标注;
9、s6,模型的分类性能评价指标及分类阈值。
10、优选地,步骤s1中,卷积神经网络cnn是深度学习领域中一种常用网络,cnn由输入层、隐含层以及输出层组成,但与神经网络不同的是,cnn隐含层由卷积层、池化层反复堆叠组成,其中卷积层由若干个特征平面组成,每个特征平面都由矩形排列的神经元组成,同一特征平面的神经元共享权重参数,共享的权重参数就是卷积核,卷积层利用卷积核进行卷积运算从而实现对局部数据的特征提取;池化层进行池化运算,通过该运算能显著降低数据维度并从卷积层提炼最具代表性特征;卷积层、池化层反复堆叠以实现抽象高阶特征的提取;输出层的结构与神经网络相同,一般又称为全连接层,通过全连接的方式得到输出结果;单卷积核cnn数据处理流程包括:
11、设原始输入为x=[x1,x2,x3,…,xt,…,xs]t,x为s行d列的二维矩阵即x∈rs×d;卷积层中的卷积核对原始输入x进行卷积运算,运算过程如下所示:
12、ac=f(wc*x+bc);
13、其中,wc为卷积核对应的矩阵,“*”意为卷积运算,bc为卷积核偏置项,最终通过激活函数f得到运算结果ac,随后将数据传输至池化层;
14、卷积运算后紧接着进行池化运算,利用该运算能减少冗余数据,池化运算包括最大值池化以及平均值池化,运算过程包括:
15、ap=pooling(ac);
16、池化运算对2×2的局部接受域中的数据取最大值或平均值,与卷积运算类似,依次从左向右从上到下进行扫描(步距大小保持为1),运算结束后将各部分的运算结果进行拼接最终得到ap。
17、max-pooling运算可以保留局部接受域中的最典型数据并将弱关联性部分剔除,所以在池化层中max-pooling运用最为普遍,而mean-pooling运算虽然可以对局部接受域数据求取算数平均值,权衡各数据对计算结果的影响,但存在重点数据筛选能力较差的问题,所以应用较少;卷积层与池化层重复堆叠经输出层得到模型的分类结果:
18、afc=f(apwfc+bfc);
19、y=f(afcwfc+bfc);
20、其中,wfc和bfc分别为全连接层的权重矩阵以及偏置项,y为模型计算结果;采用全连接的方式可以实现全局时序特征的组合。
21、当卷积层存在多个卷积核时,多个卷积核并列完成对局部感受域中数据的卷积运算,各自的卷积结果再分别进行池化运算,两者堆叠最后经全连接层输出计算结果,计算过程如下所示:
22、
23、
24、其中,与分别为第k个卷积核的参数矩阵以及对应的第k个偏置项,为第k个卷积核的运算结果,为第k个池化结果。
25、进一步地,cnn与传统神经网络的结果存在固有差异,所以cnn的训练过程与神经网络有所不同,神经网络训练过程只需考虑误差在不同层神经网络之间的传递问题,而cnn的误差传递方式存在以下三种情况:从全连接层传递至池化层,从池化层传递至卷积层,以及从卷积层传递至池化层。为方便推导,作两种记号:
26、(1)全连接层:为第l层中第j个节点的输入加权和,为的激活输出值;
27、(2)卷积、池化层:为第l层中第j个特征图的输入加权和,为的激活输出值;
28、故得到如下公式:
29、
30、此外,定义以下四种索引:
31、(1)设网络共有l层;
32、(2)若第l层为卷积层,则第j个节点到第l层中第i个节点的卷积核记为
33、(3)若第l层的第j个节点是由上层某些特征图卷积组合而来,则其索引记为其中,偏置项记为
34、(4)若第l-1层到第l层进行池化运算,则第j个特征图的池化参数记为
35、首先,cnn卷积层和池化层前向传播过程分别如下:
36、
37、
38、设n个带标签的样本构成样本集合,集合表示为{(z1,y1),(z2,y2),…,(zn,yn)},其分类标签定义为:
39、
40、每个标签为zn的样本经cnn运算后相应输出结果为tn,故惩罚函数定义为:
41、
42、其中,代表单个样本产生的损失值,故惩罚函数e为单个样本产生的损失值en进行求和;与神经网络的训练过程相似,cnn的反向传播过程也是寻找一组最优的系统内部参数即从而最小化e的数值;损失值在反向传播过程中首先传入cnn的最外层即全连接层并进行求导运算,推导得到:
43、
44、此后,误差从池化层传递至卷积层,求导过程有公式:
45、
46、
47、
48、其中,up(·)定义为上采样函数,该函数能依据池化后的降维结果,逆向还原出卷积层的原始数据矩阵形状;定义为两个矩阵中的对应元素相乘,与卷积运算“*”有所不同,“*”是将卷积核矩阵与局部感受域矩阵的对应元素相乘后再进行求和,故运算结果为数字,而的运算结果为矩阵;rot180(·)定义为将矩阵沿左上右下对角线在空间中翻转180度;在偏置项b求偏导数的过程中进行求和运算的原因是:只有在所有子采样运算完成之后,偏置项才会被加入;最后,误差从池化层反向传递到卷积层的求导过程有如下公式:
49、
50、
51、其中,down(·)定义为下采样函数,能够对下层已降维的数据进行数据遍历。至此,cnn的误差反向传播过程结束,最后还需利用gd不断迭代更新。
52、优选地,步骤s2中,门控循环单元包括重置门和更新门,重置门控制对前一时刻状态信息的忽略程度,更新门负责控制上一时刻状态信息对当前时刻状态的影响,两者协同工作能有效提取输入数据在较长时间序列里所包含的高阶特征,原始输入xt与前一时间周期内的状态信息ht-1经运算得到重置门结果rt与更新门zt,计算过程如下所示:
53、rt=σ(wr·[ht-1,xt])=σ(wrxxt+wrhht-1+br]);
54、zt=σ(wz·[ht-1,xt])=σ(wzhht-1+wzxxt+bz]);
55、其中,wr和wz分别为重置门和更新门的权重矩阵,br与bz为rt与zt的偏置项,权重矩阵以及偏置项均在门控循环单元的训练过程中反复更新,σ(·)定义为sigmoid函数,使重置门和更新门各自的输出rt与zt压缩在0~1;然后,ht-1在rt的控制下与xt进行运算得到候选隐藏状态计算过程如下所示:
56、
57、其中,whx与whh均为的权重矩阵,bh为的偏置项,代表矩阵中对应元素相乘;当rt=0时,则这意味着当前的候选隐藏状态完全遗忘之前所有的状态信息,即对之前的状态信息进行了重置,这也是重置门的名字由来;当rt=1时,则这意味着当前的候选隐藏状态完整保留了之前所有的状态信息,状态信息未进行重置;
58、ht-1与在更新门的输出zt的权衡下经计算得到当前的状态信息ht,再通过输出层得到输出,输出层结构与神经网络相同:
59、
60、yt=σ(wo·ht);
61、其中,更新门的作用大小与zt的取值有关,zt越大,则当前状态更新程度越高;反之,则更新的程度越低;当zt=0时得到ht=ht-1,此时更新门不发挥任何作用,前一时间周期的状态信息完整继承给当前时间周期,即状态信息不发生更新;当zt=1时得到表示当前时间周期的状态信息全部取决于当前的候选隐藏状态,而与之前的状态信息无关;所以,更新门的作用大小与zt的取值有关,zt越大,则当前状态更新程度越高;反之,则更新的程度越低。最后,gru依次读取后续时间序列片段,不断利用更新门权衡先前时间周期的状态信息在当前的占比,读取结束即可获得整个时间序列的状态信息特征。
62、门控循环单元的训练参数有:wrx、wrh、wzx、wzh、whx、whh:
63、wr=wrx+wrh;
64、wz=wzx+wzh;
65、wh=whx+whh;
66、其中,wr、wz和wh分别为重置门、更新门以及候选隐藏状态的综合待更新参数;
67、输出层对单个样本的输入与输出分别如下所示:
68、
69、
70、继而得到所有样本的损失值,惩罚函数如下所示:
71、
72、其中,et代表单个样本的损失值,e代表所有t个样本的损失值叠加,yd为各样本的标签值;采用反向传播算法训练网络,得到各参数的更新方法如下所示:
73、
74、
75、
76、
77、
78、
79、
80、各中间参数具体如下:
81、
82、δh.t=δy,two+δz,t+1wzh+δt+1whh·rt+1+δh,t+1wrh+δh,t+1·(1-zt+1);
83、
84、δt=δh,t·zt·φ’;
85、δr,t=ht-1·[(δh,t·zt·φ’)whh]·σ’;
86、gru具有特殊的重置门及更新门结构,因此在其训练过程中涉及大量繁琐的参数并具有更复杂的调参过程,但相较于lstm,gru缺少了一个门函数使模型参数量大大减少,故gru训练时间更短、参数拟合能力更强。
87、优选地,步骤s3中,构建cnn+gru模型包括建立cnn+gru输入与输出之间的映射关系,具体如下:
88、通过大量样本训练cnn+gru模型,待参数调整完成后再投入在线应用;其中所有
89、样本由电气量随时间变化的数字信息以及对应扰动条件下的稳定性标签两部分组成,前者通过调取时域仿真的历史记录得到,后者通过先验知识计算得出。
90、进一步地,步骤s4中,输入数据预处理时,合理选择原始输入的特征对模型的tsa性能有很大的影响,所选特征越具有代表性,训练后的模型对稳定、失稳样本的分类能力越强,故在特征选择中主要考虑以下四种因素:
91、(1)在特征选取过程中应尽量减少甚至避免掺杂人类的主观性,客观选择模型所需的各类特征,否则可能导致cnn+gru的训练失效;
92、(2)所选特征可通过pmu直接量测、测量简单并且实时有效。通常将电压幅值以及相角纳入候选特征范围,因为pmu具有实时测量电力系统各个节点的电压幅值以及相角的功能,而获取功角差通过pmu容易产生测量延时以及数据误差,所以一般不将功角差纳入候选特征范围;
93、(3)所选特征需可靠反应故障后电网的暂态信息特征。与发电机功角及转动惯量相比,节点电压更适合作为模型的候选特征,因为故障后的电网电压具有局部变化迅速、区域性较强的特点,而发电机的功角与转动惯量存在暂态信息匹配滞后的问题,对暂态信息的反应不灵敏且不可靠,所以不适合作为候选特征。此外,支路有功以及无功潮流隐含电网拓扑结构的特征,所以也是候选特征的选择之一;
94、(4)所选特征应尽可能有规律地进行排列,特征排列方式会直接影响训练过程中模型对数据的可读性。所选特征需按时间顺序依次排列。
95、优选地,步骤s4中,输入数据预处理包括:
96、s401,数据选择和排列:
97、选择电网各节点的电压幅值以及相角、各支路的有功以及无功作为cnn+gru的输入特征,所得特征排列顺序如下所示:
98、x=[v1,v2,…,vm,θ1,θ2,…,θm,p1,p2,…,pt,q1,q2,…,qt];
99、其中,x中元素均为d维向量,d表示采样次数,m、t分别代表网络的节点数、支路数。
100、进一步地,各个节点具有一个节点电压幅值对应一个相角值的属性,故x中的电压幅值v元素与相角θ元素数目必然一致,此外,采样区间应尽量包括数量恰当的暂态信息,区间不宜过长或过短,如果过短将导致数据的时序关联性过高、数据差异性降低,即不同数据之间高度相似,最终导致gru从宏观角度提取数据特征的性能被限制,反之,cnn从局部角度提取数据特征的性能受限;因此,所有样本具有恰当的原始数据量为发挥cnn+gru的tsa性能提供了保障。
101、进一步地,为保证样本采样形式统一及训练cnn+gru的样本性质一致,所有样本均取故障前若干周期tp-k到故障切除后的若干周期tc+k作为有效的采样区间[tp-k,tc+k],但因每条样本的故障持续时间不同,所以每条样本的故障切除时刻tc互不相同,tc+k也互不相同。
102、进一步地,将tc最晚的样本定义为smax并把smax的采样点数sp作为所有样本的采样基准值,显然,smax具有最晚的tc+k以及最长的有效采样区间[tp-k,tc+k],而其他样本必然具有s≤smax的特征。进行暂态稳定分析需读入不同样本进行模型训练,为保证输入数据的维度一致即sp一致,s≤smax样本的空缺数据必须进行补0处理。
103、s402,为了避免训练过程模型在局部最优解周边反复震荡,无法收敛到局部最优解,并且将有量纲数据转化为无量纲数据,增强数据的可比性,在模型训练之前务必需对数据进行归一化;采用z-score归一化在模型训练之前对数据进行归一化:
104、
105、归一化的对象是公式中所有向量元素,例如v1、θ1、p1以及q1;式中,x代表向量中的某个元素,xmean表示对应向量中所有元素的平均值,xstd代表向量中所有元素的标准差,xnormal为对应x的归一化结果;以p1为例详细说明:p1为具有d个采样点的向量。xmean和xstd分别为d个元素的有功功率平均值以及标准差,归一化后各支路在任意时刻的有功功率数值均压缩到0~1且无量纲。
106、优选地,步骤s5中,稳态判据及样本标注包括离线训练以及在线应用两个阶段:
107、s501,离线训练阶段:
108、给定一组数据,已知其预期输出,不断调整模型参数构建输入与输出之间准确的映射关系;其中映射标签在离线训练前粘贴于所有样本上,多机系统中利用故障后各发电机功角的数值计算系统的暂态稳定指数得到样本标签;tsi以及样本的标签计算方法如下所示,0、1分别定义为稳定样本与失稳样本:
109、
110、
111、其中,δδmax表示任意两台发电机之间的最大功角差。如果|δδmax|大于360°,即tsi<0,则系统判为失稳,样本标注为1;如果|δδmax|小于360°,则系统稳定且样本标注为0。
112、优选地,步骤s6的分类性能评价指标及分类阈值中,电力系统tsa属于样本的二分类问题,包括漏判样本以及误判样本,分别定义为fn以及fp;正确分类的样本包括稳定样本和失稳样本,分别定义为tp和tn;漏判样本是指:标注为稳定的样本错分成了失稳样本,因此相应的继电保护装置会误动,但因系统处于稳定状态,所以误动不会给系统造成过大影响;误判是指:标注为失稳的样本错分成了稳定样本,此时保护装置会发生拒动,未做出任何反应维持系统稳定状态,严重时导致系统解列并引发大规模的停电,显然与漏判相比,误判对电力系统正常运行造成的损害更加严重,故二分类问题更加关注失稳样本的分类问题以及误判现象。
113、引入准确率acc、精确率pre、召回率rec及fβ分数共四种统计学指标评估模型的分类性能,对pre、rec两项指标进行修改,得到以下公式:
114、
115、
116、
117、
118、其中,acc表示评价模型的分类正确率;pr用于衡量标注为失稳的样本占分类为失稳样本的比例,表示评价模型对失稳样本的分类正确率,即模型的查准率;rec用于衡量分类为失稳的样本占标注为失稳样本的比例,从原始数据的角度评价模型对失稳样本的分类正确率,即模型的查全率;
119、因为pre与rec之间存在矛盾关系,采用fβ将pre和rec两个分值进行综合权衡:
120、当β=0.5时,pre的权重是rec的两倍;当β=2时,rec的权重是pre的两倍;rec与pre权重保持一致,取β=1并得到以下公式:
121、
122、cnn+gru中的输出层最后一层直接输出模型的分类结果,该结果的本质为样本稳定的概率,此概率若大于预先设定数值则将该样本判断为稳定样本,反之,若小于预设数值则判断为失稳样本;上述预设数值即为cnn+gru的分类阈值,如下所示:
123、
124、其中,γ为预设数值,即分类阈值,pz(c0|x)为样本x稳定的概率,pz(c1|x)为样本x失稳的概率,样本失稳以及样本稳定为互补事件,故pz(c0|x)+pz(c1|x)=1;如果γ越大,则样本判断为稳定的门槛越高,判断为失稳的门槛越低,漏判现象增多,误判现象减少;γ越小,则样本判断为失稳的门槛越高,判断为稳定的门槛越低,误判现象增多,漏判现象减少;当γ=0.5时,样本判为稳定以及失稳的门槛持平。
125、本发明提供的基于卷积神经网络-门控循环单元的暂态评估方法的有益效果如下:
126、本方法充分吸纳卷积神经网络与门控循环单元模型各自对短期局部、长期宏观特征的提取能力,克服卷积神经网络模型特征提取性能的局限性,从而进一步提高模型的tsa性能。所提模型凭借其独特的长短期特征提取能力,能自动构建原始输入与样本稳定标签之间的映射关系,提高模型对失稳样本的拟合程度、平衡两类样本的数量,通过优化参数计算避开繁琐的调参过程,提高所提模型的工程应用效率,对电力系统的稳态判据具有重要意义。
- 还没有人留言评论。精彩留言会获得点赞!