一种文本内容智能审校方法、系统及计算机存储介质与流程
本技术涉及自然语言处理及人工智能,具体而言,涉及一种文本内容智能审校方法、系统及计算机存储介质。
背景技术:
1、内容审校在媒体领域是一项非常重要的工作,可用于发现、纠正并改进生成的内容,以确保内容的准确性及合规性。目前,文本内容的审校通常需要大量的人工干预,这不仅费时费力,还容易出现遗漏和错误。传统的文本检查和语法检查工具在很大程度上受限于规则和已知词汇,难以应对复杂的知识性、专业性的文本内容审查需求。因此,为了提升媒体工作者或内容生产者生产内容的效率,亟需一种更智能的文本内容审校系统,能够更好地理解上下文语义并利用更丰富的知识进行审查。
2、2023年09月05日公开的中国专利cn116702758a提供了一种文本审校的方法,针对中文场景的文本审校方法,该方法借助深度神经网络技术和完备的中文纠错规则,可以实现中文拼写纠错、语法纠错、成语纠错、人名地名纠错、古诗俗语纠错、标点符号检测、日期格式检测等功能,通过对错误类型进行分类以及采取不同的通道进行处理,该方法可以有效可控地对含错中文文本进行校对。但是该方法对于不同类型的错误更多的是采取不同的通道和算法进行处理,这在一定程度上影响了其文本审校效率。
技术实现思路
1、本技术的目的在于提供一种文本内容智能审校方法、系统及计算机存储介质。通过对不同类型错误设计不同的prompt标签,不同的prompt标签灵活组合,可实现多种不同类型的文本错误校验;通过大模型的语义理解能力可省去传统文本处理流程,提供文本内容审校的效率。
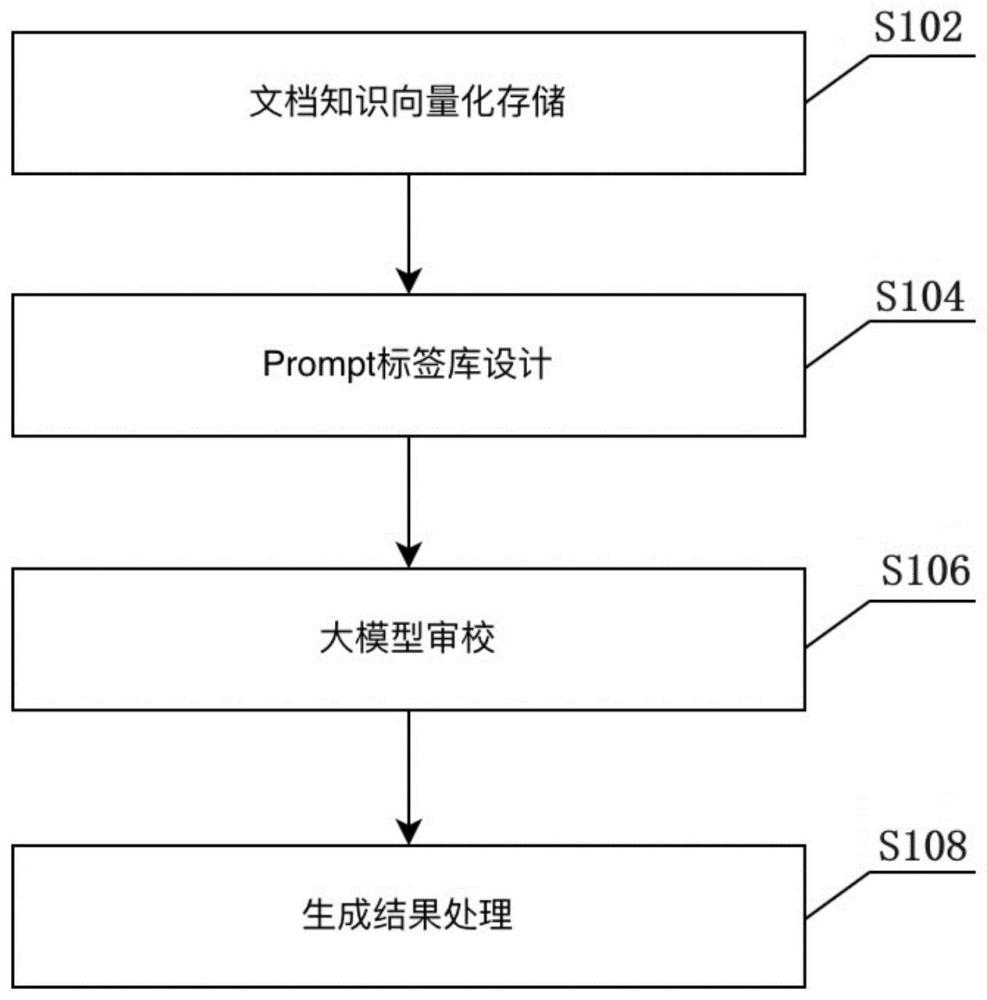
2、本技术第一方面提供了一种文本内容智能审校方法,所述方法包括以下步骤:
3、收集与检测内容相关专业领域文档,将其向量化,得到向量模型并进行存储;
4、设计文本内容错误类型的prompt标签;
5、根据与检测内容相关专业领域文档,结合prompt标签对待测文档进行大模型审校,并输出审校结果。
6、可选地,所述收集与检测内容相关专业领域文档,将其向量化,得到向量模型并进行存储,具体包括:
7、收集与检测内容相关的专业领域文档,形成文档集合,记作文档集合d;
8、在保证语义完整性的前提下,将文档集合d中每篇文章拆分成不同的片段;
9、拆分后的片段经过向量模型将片段向量化,记作文档片段向量e;
10、将文档片段向量e作为向量模型存储于向量数据库中,用于后续向量检索使用。
11、可选地,所述将文档集合d中每篇文章拆分成不同的片段,每篇文章的拆分根据标点符号来拆分。
12、可选地,所述向量模型为m3e模型或text2vec模型。
13、可选地,所述向量数据库为faiss向量数据库或milvus向量数据库。
14、可选地,所述设计文本内容错误类型的prompt标签,具体为:
15、对于每种不同类型的错误设计至少一个prompt标签,即形成<错误类型-prompt标签>的映射,通过prompt标签的组合检测不同类型的错误。
16、可选地,所述大模型为baichuan2-13b模型。
17、所述大模型的参数量为13b,是在1.4万亿中英文训练数据上训练而来,其中token词表大小为64k,模型主体结构是由transformer组成,隐藏层维度为5120,模型层数40层,注意力头数40,模型的位置编码采用alibi的线性偏置方式实现。
18、可选地,所述大模型审校,包括:
19、将原文中待检测部分的内容记为p1;
20、将p1通过向量模型转成向量,根据向量化后的结果从向量数据库中根据相关性检索到相似的文档片段知识,该部分文档片段知识记为p2;
21、由prompt标签组合的纠错类型记为p3;
22、将p1,p2,p3进行组合得到(p1,p2,p3)组合;
23、将(p1,p2,p3)组合的提示词输入至大模型中,利用大模型根据提示词基于p2的文档片段知识,来检测p1中存在的p3类型的错误,并生成相应的修改建议结果。
24、本技术第二方面提供了一种文本内容智能审校系统,该系统包括:存储器及处理器,所述存储器中包括一种文本内容智能审校方法的程序,所述文本内容智能审校方法的程序被所述处理器执行时实如下方法的步骤:
25、收集与检测内容相关专业领域文档,将其向量化,得到向量模型并进行存储;
26、设计文本内容错误类型的prompt标签;
27、根据与检测内容相关专业领域文档,结合prompt标签对待测文档进行大模型审校,并输出审校结果。
28、可选地,所述收集与检测内容相关专业领域文档,将其向量化,得到向量模型并进行存储,具体包括:
29、收集与检测内容相关的专业领域文档,形成文档集合,记作文档集合d;
30、在保证语义完整性的前提下,将文档集合d中每篇文章拆分成不同的片段;
31、拆分后的片段经过向量模型将片段向量化,记作文档片段向量e;
32、将文档片段向量e作为向量模型存储于向量数据库中,用于后续向量检索使用。
33、可选地,所述将文档集合d中每篇文章拆分成不同的片段,每篇文章的拆分根据标点符号来拆分。
34、可选地,所述向量模型为m3e模型或text2vec模型。
35、可选地,所述向量数据库为faiss向量数据库或milvus向量数据库。
36、可选地,所述设计文本内容错误类型的prompt标签,具体为:
37、对于每种不同类型的错误设计至少一个prompt标签,即形成<错误类型-prompt标签>的映射,通过prompt标签的组合检测不同类型的错误。
38、可选地,所述大模型为baichuan2-13b模型。
39、所述大模型的参数量为13b,是在1.4万亿中英文训练数据上训练而来,其中token词表大小为64k,模型主体结构是由transformer组成,隐藏层维度为5120,模型层数40层,注意力头数40,模型的位置编码采用alibi的线性偏置方式实现。
40、可选地,所述大模型审校,包括:
41、将原文中待检测部分的内容记为p1;
42、将p1通过向量模型转成向量,根据向量化后的结果从向量数据库中根据相关性检索到相似的文档片段知识,该部分文档片段知识记为p2;
43、由prompt标签组合的纠错类型记为p3;
44、将p1,p2,p3进行组合得到(p1,p2,p3)组合;
45、将(p1,p2,p3)组合的提示词输入至大模型中,利用大模型根据提示词基于p2的文档片段知识,来检测p1中存在的p3类型的错误,并生成相应的修改建议结果。
46、本技术第三方面提供了一种计算机可读存储介质,所述计算机可读存储介质中包括文本内容智能审校方法程序,所述文本内容智能审校方法程序被处理器执行时,实现所述文本内容智能审校方法的步骤。
47、由上可知,本技术提供的一种文本内容智能审校方法、系统及计算机存储介质。本技术通过对不同类型错误设计prompt标签,不同的prompt标签灵活组合可校验多种不同类型的错误,避免了对不同错误训练不同的模型来检测。通过大模型的语义理解能力可省去传统文本处理流程,且一个大模型可以处理多种错误类型,简单高效。通过结合文档知识,可针对一些复杂的专业性、知识性和时效性错误进行检测,而目前基于规则或者传统模型方法无法检测出这些错误。
48、本技术的其他特征和优点将在随后的说明书阐述,并且,部分地从说明书中变得显而易见,或者通过实施本技术实施例了解。本技术的目的和其他优点可通过在所写的说明书、权利要求书、以及附图中所特别指出的结构来实现和获得。
- 还没有人留言评论。精彩留言会获得点赞!