编译方法、编译器、神经网络加速器、芯片及电子设备与流程
本发明涉及神经网络,尤其涉及一种编译方法、编译器、神经网络加速器、芯片及电子设备。
背景技术:
1、深度神经网络(deep neural network,dnn)是一种基于人工神经网络架构的机器学习方法,人工神经网络(artificial neural networks,ann)使用相互连接的节点(称为神经元)的层来处理和学习输入数据。深度神经网络是具有多个层的人工神经网络,这些层位于输入层和输出层之间。神经网络总是由相同的组件组成:神经元、突触、权重、偏差和函数,在实际应用中,这些组件通常被称作算子。常见的算子有:卷积、池化、上/下采样、激活函数、元素操作(元素加、元素减、元素乘、元素除)等。深度学习使用多个层来表示数据的不同层次的抽象,从而提高模型的准确性和泛化能力,已经广泛应用于运算机视觉、语音识别、自然语言处理、机器翻译、生物信息学、药物设计、医学图像分析等领域,产生了与人类专家水平相当甚至超越的结果。随着数据量不断地累积,以神经网络为主题的人工智能技术得到越来越广泛的应用。尽管神经网络已经被证明能够成功解决自动驾驶、人脸识别等实际问题,但由于传统硬件平台运算性能的局限性,使得神经网络在传统硬件难以高效部署。因此,需要专门为神经网络算法设计定制的硬件平台,这中硬件平台被称为神经网络加速器,其核心通常是一组专用的集成电路芯片,这种芯片被称为神经网络加速器芯片。
2、为了缓解深度学习中恶化的存储墙问题,神经网络加速器芯片通常会在靠近运算单元的位置设计片上存储,访问片上存储的延时远低于访问片外存储的延时,因此合理地利用片上存储是发挥神经网络加速器性能的关键。一般深度学习装置还具有片外存储,片外存储是指集成在芯片外部的缓存,如主板,它的速度比片内存储慢,但容量更大。
3、一般深度学习模型所需的存储空间较大,通常情况下无法直接导入到片上存储上面,而深度学习模型一开始会被导入到片外存储,如果按照一般的编译流程生成的计算图,在计算的过程中每次产生的结果都要储存到片外存储,这样不但会生产更高的功耗,增加神经网络加速器芯片的面积成本,而且搬运结果到片外存储需要的时间很长,这样会导致神经网络加速器计算阻塞,从而算力无法充分发挥。而解决这个问题的方法之一是尽量减少把结果搬运到片外存储,尽量让结果都可以存储在片上存储。同时,深度学习中算子参数的组合或者片上存储的容量发生变化都会影响数据和运算的最优拆分策略,导致生成的二进制代码不同,影响了算法的执行效率。
4、基于上述原因,由于深度学习算法的特殊性以及神经网络加速器结构的特殊性,使得深度学习领域的程序优化有两个重要特点,一是对算法和硬件的变动极其敏感,二是运算和数据间耦合度极高。因此,如何基于这些特征,提出一种面向深度学习算法的编译方法,改善编译的灵活性和编译的效率、缓解存储墙问题,提高计算效率,降低神经网络加速器芯片的面积和功耗成为了亟需解决的问题。
技术实现思路
1、本发明的目的在于提供一种编译方法、编译器、神经网络加速器、芯片及电子设备,以至少解决上述技术问题。本发明提供的诸多技术方案中的优选技术方案所能产生的诸多技术效果详见下文阐述。
2、为实现上述目的,本发明提供了以下技术方案:
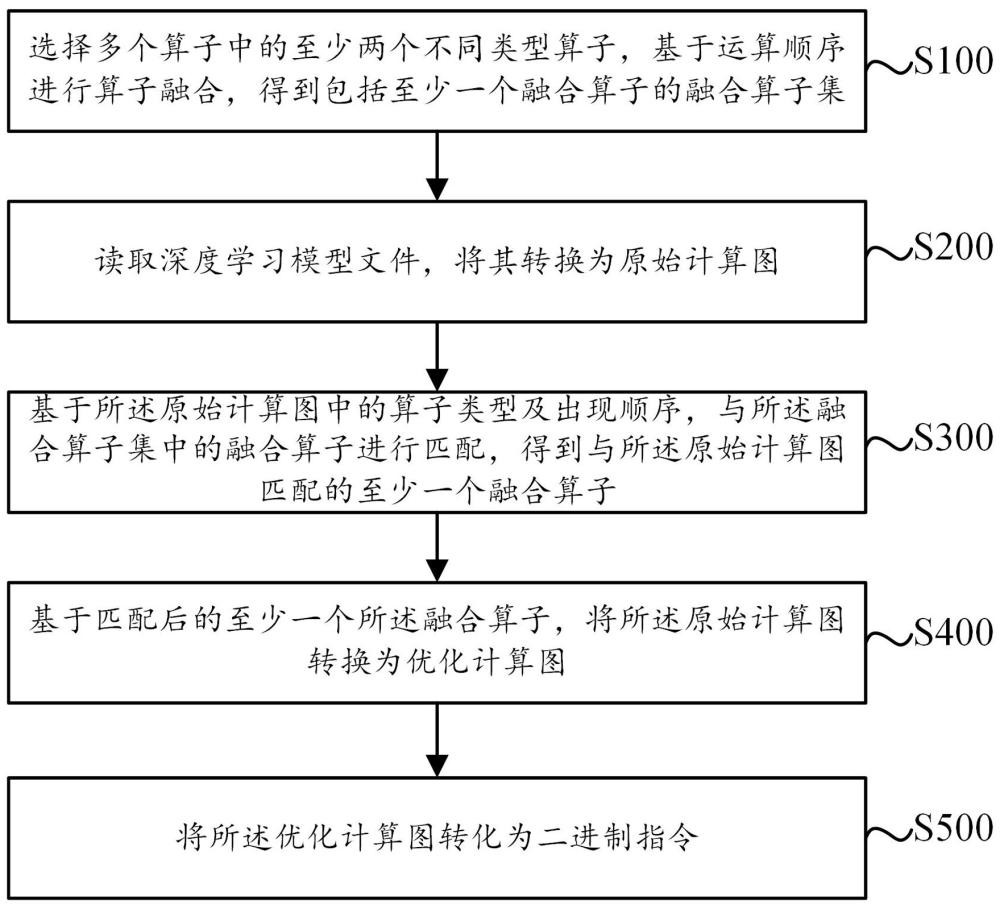
3、本发明提供一种编译方法,包括以下步骤:s100:选择多个算子中的至少两个不同类型算子,基于运算顺序进行算子融合,得到包括至少一个融合算子的融合算子集;s200:读取深度学习模型文件,将其转换为原始计算图;s300:基于所述原始计算图中的算子类型及出现顺序,与所述融合算子集中的融合算子进行匹配,得到与所述原始计算图匹配的至少一个融合算子;s400:基于匹配后的至少一个所述融合算子,将所述原始计算图转换为优化计算图;s500:将所述优化计算图转化为二进制指令。
4、优选的,所述s300步骤具体包括:s310:从所述原始计算图的输出节点反向遍历,直到找到输入节点,得出所有的从输入到输出节点的初始执行路径;s320:找出全部的所述初始执行路径中的重复部分并进行标记,然后将所有的所述初始执行路径合并为一条结果执行路径;s330:在所述结果执行路径上遍历全部的节点,基于全部的节点得到全部的算子类型及出现顺序,找出满足所述融合算子集的算子类型及操作顺序的节点,得到至少一组融合节点;s340:基于所述融合节点的算子类型及操作顺序,得到与所述原始计算图匹配的至少一个所述融合算子。
5、优选的,所述算子包括卷积运算、池化运算、上下采样运算、激活函数运算、元素运算、块归一化运算、层归一化运算中的至少一种。
6、优选的,所述激活函数运算包括relu激活函数运算、leakly_relu激活函数运算、hard swish激活函数运算、sigmoid激活函数运算、silu激活函数运算、prelu激活函数运算、tanh激活函数运算、elu激活函数运算、softmax激活函数运算、switch激活函数运算、maxout激活函数运算、及softplus激活函数运算中的至少一种;所述元素运算包括加运算add、减运算sub、乘运算mul、除运算div、余数mod、补码neg、递增inc、递减dec、最大值max、最小值min、以及绝对值abs中的至少一种。
7、优选的,基于所述卷积运算、激活函数运算、池化运算、以及元素运算的单向操作指令序列,得到图像处理融合算子。
8、优选的,所述图像处理融合算子中,在进行所述元素运算的操作后,还包括上下采样运算操作。
9、优选的,所述图像处理融合算子中,在进行所述激活函数运算、池化运算操作之间,还包括块归一化运算操作。
10、优选的,基于卷积运算、第一算子、第二算子、第三算子、以及第四算子的单向操作指令序列,得到综合融合算子;所述第一算子、第二算子、第三算子、以及第四算子均为池化运算、上下采样运算、激活函数运算、元素运算、块归一化运算、层归一化运算中的任意一种,且各不相同。
11、优选的,所述s200步骤中,所述原始计算图为有向图,通过对其进行拓扑转换得到如下拓扑排序:
12、y1 = op1(x),
13、y2 = op2(y1),
14、yn = opn(yn-1),
15、其中,y1,y2,...,yn-1表示中间计算结果,yn表示输出结果,op1,op2,opn表示相同或不同类型的算子。
16、优选的,所述s500步骤中,基于代价模型的启发式搜索策略,所述优化计算图使用卷积核生成器输出二进制指令。
17、一种编译器,用于运行以上任一项所述的编译方法,包括:数据接收模块、编译模块、及指令获取模块;所述数据接收模块用于接收不同格式的深度学习模型文件的模型数据,并解析得到所述原始计算图;所述编译模块通过计算图引擎对所述原始计算图进行算子融合,将所述原始计算图转换为所述优化计算图,并编译为算子指令;所述指令获取模块用于接收所述算子指令,对所述算子指令进行调整、封装及格式转换操作,得到转换指令;所述编译模块还将所述转换指令转换为二进制指令。
18、优选的,所述计算图引擎通过nnapi编程库的操作创建与调用api进行操作。
19、一种神经网络加速器,包括以上任一项所述的一种编译器。
20、一种芯片,包括以上所述的编译器或包括以上所述的神经网络加速器。
21、一种电子设备,包括以上所述的编译器或包括以上所述的神经网络加速器。
22、实施本发明上述技术方案中的一个技术方案,具有如下优点或有益效果:
23、本发明中,通过对原始计算图中的算子进行算子融合,可以减少单个算子之间的内存数据搬运次数及数据搬运量,最终减少深度学习模型文件中整体算子的执行时间,缓解了神经网络运算中的存储墙问题,从而深度学习可实现更高的计算效率,进而降低神经网络芯片的面积和功耗。进一步地,还可以使用融合算子来表示深度学习算法里面常用的算子组合,甚至整个模型,改善了编译的灵活性和编译的效率,进一步提高深度学习的执行效率。
- 还没有人留言评论。精彩留言会获得点赞!