一种智能问答系统及分析方法与流程
本发明涉及自然语言处理研究领域,具体涉及一种智能问答系统及分析方法。
背景技术:
1、问答系统是一种人工智能程序,旨在回答用户的问题,以此满足人们快速准确地获得信息的需求。问答系统可以在各个领域或者应用中使用,例如:客户服务、技术支持、医疗诊断、法律服务等。随着大数据技术的不断发展以及人工智能和自然语言处理技术的日趋成熟,问答系统越来越受到人们的广泛关注。
2、问答系统目前存在以下问题:
3、一、语义问题:目前大部分的智能问答系统都是基于elastic search进行检索。es采用倒排索引的结构,对用户输入的问题进行全文搜索,查找出和用户输入问题相匹配的文档。由于es底层是一个基于tf/idf词频计算的关键词搜索方案,未能将词义考虑在内,因此无法理解用户输入问题中关键字的深层次含义。
4、二、封闭性问题:问答系统都是以faq(frequently asked questions)库作为检索资源,一旦设计完成,就很少对进行更新,因此对于faq库以外的问题,系统难以给出正确的答案,满足不了用户的需求。
技术实现思路
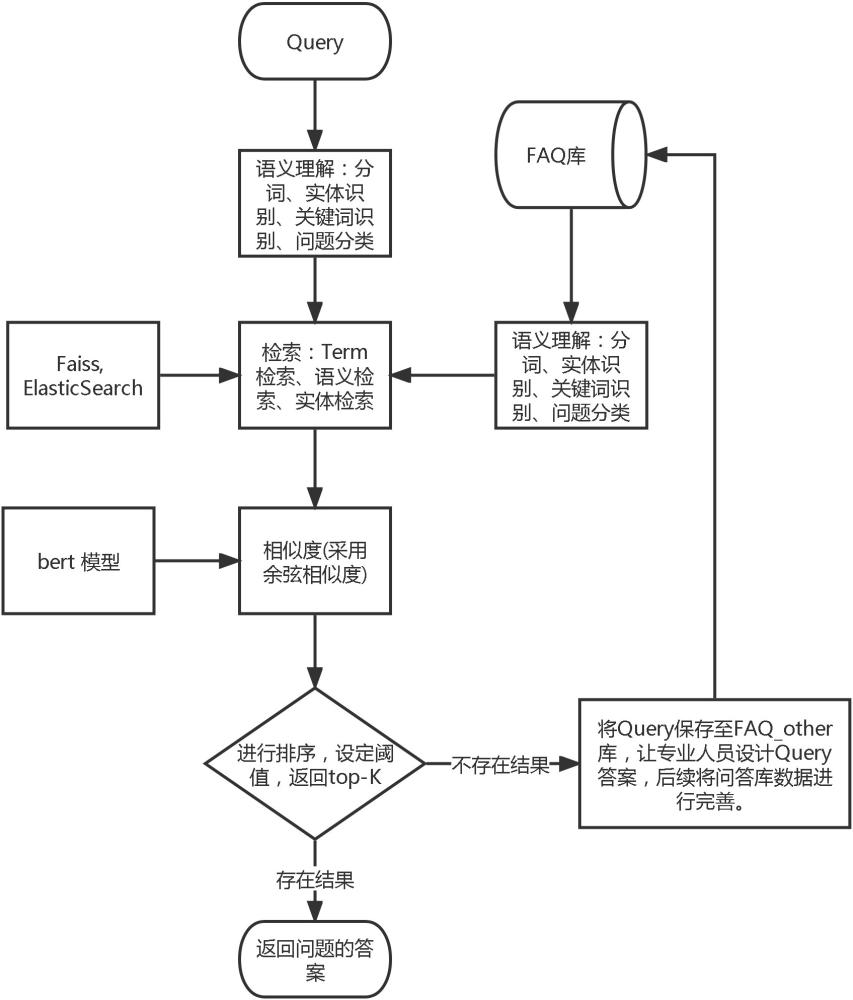
1、为了克服现有技术的不足,对于语义问题,本发明采用中文bert-wwm预训练模型,构建文本向量,利用faiss构建索引(index),并将文本向量添加到index中,然后利用faissindex进行检索,得到召回;对于封闭性问题,本发明采用存储+组织+存储的方式,定时更新faq库;针对用户输入的问题,faq库不存在答案的情况,将用户输入的问题存储至faq_other库中,利用网络爬虫技术,获取相关资料,并让专业人员组织标准答案,存储至faq_other库,最后采用增量的方式定期更新faq库。技术方案如下:
2、一种智能问答系统及分析方法,包括如下步骤:
3、步骤一:构建问答库,收集组织并存储原始问题以及与原始问题相对应的答案,将数据存储至mysql和elastic search数据库中。
4、优选的,对于mysql数据库,需设计相应的字段,包括原始问题(question)、原始问题答案(answer)、原始问题分类(category)、原始问题分词结果(word_piece)、原始问题句向量(vector)。
5、优选的,对于elastic search数据库,根据需要对字段的属性进行设计,选择ik中文分词器作为分词器插件,针对分词器的两种分词模式,使用ik_max_word(最细粒度的拆分)模式创建索引,使用ik_smart(最粗粒度的拆分)模式进行搜索,来提高用户输入问题对原始问题的命中率;在elastic search数据库中添加自定义词库,包括自定义词典,停用词词典和同义词词典,来提高搜索的准确率。
6、步骤二:对原始问题和用户输入问题进行分词处理,利用lac分词工具加载构建好的自定义词典;对用户输入问题和原始问题进行分词,利用构建好的停用词词典对分词结果进行停用词的处理,去除一些不相关的字词,利用同义词词典进行同义词的转化,将分词之后的结果存储至mysql数据库中。
7、对原始问题进行标注,划分为不同的分类主题,使用中文bert-wwm预训练模型,在数据集上进行微调,得到微调后的bert分类模型并将其保存至本地,调用微调后的bert分类模型,对用户输入问题进行分类预测。
8、步骤三:针对于es检索召回,基于步骤二,获得用户输入问题的分类,根据elasticsearch数据库,综合考虑用户输入问题、问题的分类以及问题所涉及的主体,设计搜索语句,对原始问题进行相关的检索;设置相关性得分阈值,过滤掉低于该阈值的原始问题,将搜索得到的数据按照相关性得分进行降序排列,选取其中的前15条数据,作为es检索得到的最终的数据。
9、针对于语义检索召回,调用faiss的相关接口,加载微调后的bert模型,得到向量库;构建index,并将向量添加到index中;选用暴力检索的方法flatl2,计算得到与用户输入问题最接近的15个原始问题,其中l2代表使用欧氏距离度量向量之间的相似性。
10、优选的,当数据集比较大的时候,使用ivfx flat(倒排暴力索引)的方法。
11、步骤四:基于标注好的数据集,训练一个双塔模型,其次,综合步骤三中的es的检索召回和faiss的语义检索召回,此时的召回数量小于等于30条,将用户输入问题和每一个召回的原始问题输入到训练好的双塔模型中,计算出模型输出向量之间的余弦相似度,根据余弦值的大小进行降序排序,设定阈值,当最大的余弦值大于0.9时,返回一个原始问题的答案;当最大的0.5<余弦值<0.9时,返回前k个原始问题的答案;当余弦值均小于0.5时,不返回任何结果,认为没有原始问题与用户输入问题相似。
12、优选的,对于双塔模型中的两个模型,使用步骤二中微调后的bert分类模型。
13、优选的,相似度的具体地计算方法如下所示:
14、
15、其中,xi=(x1,x2,…,x748)表示用户输入问题的句向量,yi=(y1,y2,…,y748)表示原始问题的句向量,余弦值的取值范围在-1到1之间,当余弦值越接近1,夹角越接近0度,那么两个向量越相似,说明用户输入问题和原始问题越相似。
16、优选的,k的取值为5。
17、步骤五:对于用户输入问题不存在结果的情况,将用户输入问题存储至faq_other库,对用户输入问题重新组成并设计该问题的答案,并更新faq_other库,后期根据faq_other库以增量的方式定期更新faq库。
18、与现有技术相比,本发明的有益效果为:从语义的角度,能够深层次的理解用户输入的问题;能够快速准确地回答用户问题,节省用户时间;检索资源定期更新,答案更加丰富完善。
技术特征:
1.一种智能问答系统及分析方法,其特征在于,包括如下步骤:
2.根据权利要求1所述的一种智能问答系统及分析方法,其特征在于,对于mysql数据库,需设计相应的字段,包括原始问题(question)、原始问题答案(answer)、原始问题分类(category)、原始问题分词结果(word_piece)、原始问题句向量(vector)。
3.根据权利要求2所述的一种智能问答系统及分析方法,其特征在于,对于elasticsearch数据库,根据需要对字段的属性进行设计,选择ik中文分词器作为分词器插件,针对分词器的两种分词模式,使用ik_max_word(最细粒度的拆分)模式创建索引,使用ik_smart(最粗粒度的拆分)模式进行搜索,来提高用户输入问题对原始问题的命中率;在elasticsearch数据库中添加自定义词库,包括自定义词典,停用词词典和同义词词典,来提高搜索的准确率。
4.根据权利要求3所述的一种智能问答系统及分析方法,其特征在于,针对于语义检索召回,当数据集比较大的时候,使用ivfx flat(倒排暴力索引)的方法。
5.根据权利要求4所述的一种智能问答系统及分析方法,其特征在于,对于双塔模型中的两个模型,使用步骤二中微调后的bert分类模型。
6.根据权利要求4所述的一种智能问答系统及分析方法,其特征在于,相似度的具体地计算方法如下所示:
7.根据权利要求6所述的一种智能问答系统及分析方法,其特征在于,步骤4中k的取值为5。
技术总结
本发明公开了一种智能问答系统及分析方法,主要包括以下步骤:设计问答库,收集组织并存储原始问题以及与原始问题相对应的答案;对原始问题和用户输入问题进行分词处理,微调预训练模型;ES检索召回和语义检索召回;计算相似度并返回最终结果;定期更新FAQ_other库。本发明从语义的角度,利用中文BERT‑wwm预训练模型,构建文本向量,利用Faiss构建索引,并将文本向量添加到index中,然后利用Faiss index进行检索,能够深层次的理解用户输入的问题,快速准确地回答用户问题,节省用户时间;检索资源定期更新,采用增量的方式定期更新FAQ库,答案更加丰富完善。
技术研发人员:倪其伟,周金明
受保护的技术使用者:南京视察者智能科技有限公司
技术研发日:
技术公布日:2024/5/16
- 还没有人留言评论。精彩留言会获得点赞!