一种多方言语音识别方法、系统、设备及介质与流程
本发明涉及语音识别,更具体的说是涉及一种多方言语音识别方法、系统、设备及介质。
背景技术:
1、为了满足实际应用需求,开发能够准确识别多种方言的语音识别系统具有重要意义,可以提高人们的生活质量和工作效率。通过该系统,不仅可以有效减少方言使用者与机器交互时的误解和沟通障碍,还能提供更加个性化和定制化的服务。在人机交互中,与机器人进行方言的语音交互可以提供更加自然和亲切的交流方式。这种交互方式让用户感到更舒适自在,更轻松地表达自己的意图和需求,增加用户与机器人之间的互动体验。此外,方言的使用还能促进文化交流和保护地域文化,使人与机器之间的交流更加丰富多样。
2、然而,传统的语音识别系统通常只能处理标准语言,对方言的识别效果较差。这导致了在使用语音识别技术的应用中,比如智能助理、语音导航等,对于方言使用者来说存在一定的困扰。
3、因此,如何提供一种多方言语音识别方法和系统是本领域技术人员亟需解决的问题。
技术实现思路
1、有鉴于此,本发明提供了一种多方言语音识别方法、系统、设备及介质,可以有效解决传统语音识别系统在处理方言识别时的问题,提高识别准确性和鲁棒性。
2、为了实现上述目的,本发明采用如下技术方案:
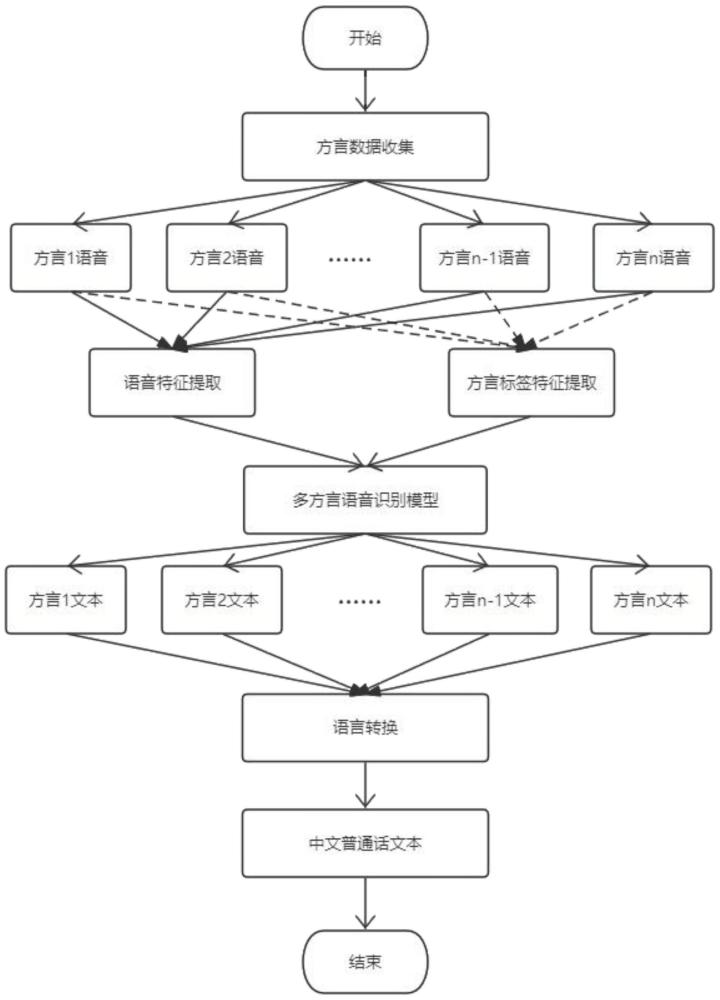
3、第一方面,本发明提供了一种多方言语音识别方法,包括:
4、获取方言数据;
5、提取方言数据的语音特征表示以及方言标签特征表示;
6、将语音特征表示以及方言标签特征表示作为多方言语音识别模型的输入,输出每种方言对应的方言语音识别文本;
7、将方言语音识别文本转换为普通话文本。
8、优选地,语音特征表示具体获取步骤包括:
9、对方言数据进行预处理;
10、将预处理后的方言语音信号进行分帧和加窗处理;
11、对加窗后的帧进行快速傅里叶变换,得到频域信号;
12、通过梅尔滤波器组对频域信号进行滤波,并对输出的能量值进行对数运算,得到对数能量值序列;
13、将对数能量值序列进行离散余弦变换,得到梅尔频率倒谱系数;
14、将梅尔频率倒谱系数中的第一个能量特征去除,得到语音特征表示。
15、优选地,通过词嵌入方法提取方言数据的方言标签特征表示。
16、优选地,多方言语音识别模型为transformer模型;
17、在模型训练阶段包括:
18、编码器负责接收语音特征表示和方言标签特征表示,并通过自注意力机制进行特征提取和抽象表示;
19、解码器则负责生成相应的输出;
20、输出层通过softmax单元输出每种方言对应的方言语音识别文本。
21、优选地,将方言语音识别文本转换为普通话文本具体包括:
22、将方言语音识别文本与预设的第一阈值进行对比;
23、若小于等于第一阈值,则通过预设的规则将方言语音识别文本转换为普通话文本;
24、若大于第一阈值,通过机器翻译模型将方言语音识别文本转换为普通话文本。
25、第二方面,本发明提供了一种多方言语音识别系统,包括:
26、数据获取模块:用于获取方言数据;
27、特征提取模块:用于提取方言数据的语音特征表示以及方言标签特征表示;
28、多方言语音识别模块:用于将语音特征表示以及方言标签特征表示作为多方言语音识别模型的输入,输出每种方言对应的方言语音识别文本;
29、语言转换模块:将方言语音识别文本转换为普通话文本。
30、优选地,特征提取模块获取语音特征表示具体处理过程为:
31、对方言数据进行预处理;
32、将预处理后的方言语音信号进行分帧和加窗处理;
33、对加窗后的帧进行快速傅里叶变换,得到频域信号;
34、通过梅尔滤波器组对频域信号进行滤波,并对输出的能量值进行对数运算,得到对数能量值序列;
35、将对数能量值序列进行离散余弦变换,得到梅尔频率倒谱系数;
36、将梅尔频率倒谱系数中的第一个能量特征去除,得到语音特征表示。
37、优选地,特征提取模块通过词嵌入方法提取方言数据的方言标签特征表示。
38、优选地,多方言语音识别模型为transformer模型;
39、在模型训练阶段包括:
40、编码器负责接收语音特征表示和方言标签特征表示,并通过自注意力机制进行特征提取和抽象表示;
41、解码器则负责生成相应的输出;
42、输出层通过softmax单元输出每种方言对应的方言语音识别文本。
43、优选地,语言转换模块具体处理过程为:
44、将方言语音识别文本与预设的第一阈值进行对比;
45、若小于等于第一阈值,则通过预设的规则将方言语音识别文本转换为普通话文本;
46、若大于第一阈值,通过机器翻译模型将方言语音识别文本转换为普通话文本。
47、第三方面,本发明提供了一种计算机设备,包括:
48、存储器,用于存储计算机程序;
49、处理器,用于执行所述计算机程序时实现所述一种多方言语音识别方法的步骤。
50、第四方面,本发明提供了一种计算机可读存储介质,所述计算机可读存储介质上存储有计算机程序,所述计算机程序被处理器执行时实现所述一种多方言语音识别方法的步骤。
51、经由上述的技术方案可知,与现有技术相比,本发明公开提供了一种多方言语音识别方法、系统、设备及介质,通过使用基于深度学习的语音识别技术,结合多方言语音数据集进行训练和优化,实现对多种方言的准确识别,提高了识别准确性和鲁棒性。
技术特征:
1.一种多方言语音识别方法,其特征在于,包括:
2.根据权利要求1所述的一种多方言语音识别方法,其特征在于,语音特征表示具体获取步骤包括:
3.根据权利要求1所述的一种多方言语音识别方法,其特征在于,通过词嵌入方法提取方言数据的方言标签特征表示。
4.根据权利要求1所述的一种多方言语音识别方法,其特征在于,多方言语音识别模型为transformer模型;
5.根据权利要求1所述的一种多方言语音识别方法,其特征在于,将方言语音识别文本转换为普通话文本具体包括:
6.一种多方言语音识别系统,其特征在于,包括:
7.根据权利要求6所述的一种多方言语音识别系统,其特征在于,特征提取模块获取语音特征表示具体处理过程为:
8.根据权利要求6所述的一种多方言语音识别系统,其特征在于,特征提取模块通过词嵌入方法提取方言数据的方言标签特征表示。
9.根据权利要求6所述的一种多方言语音识别系统,其特征在于,多方言语音识别模型为transformer模型;
10.根据权利要求6所述的一种多方言语音识别系统,其特征在于,语言转换模块具体处理过程为:
11.一种计算机设备,其特征在于,包括:
12.一种计算机可读存储介质,其特征在于,所述计算机可读存储介质上存储有计算机程序,所述计算机程序被处理器执行时实现如权利要求1至5任一项所述一种多方言语音识别方法的步骤。
技术总结
本发明公开了一种多方言语音识别方法、系统、设备及介质,方法包括:获取方言数据;提取方言数据的语音特征表示以及方言标签特征表示;将语音特征表示以及方言标签特征表示作为多方言语音识别模型的输入,输出每种方言对应的方言语音识别文本;将方言语音识别文本转换为普通话文本。通过使用基于transformer的语音识别技术,结合多方言语音数据集进行训练和优化,实现对多种方言的准确识别,提高了识别准确性和鲁棒性。
技术研发人员:王建英,苏江
受保护的技术使用者:暗物质(北京)智能科技有限公司
技术研发日:
技术公布日:2024/5/16
- 还没有人留言评论。精彩留言会获得点赞!