一种混合语音的处理方法、装置、计算机设备及存储介质与流程
本发明涉及语音处理领域,具体涉及一种混合语音的处理方法、装置、计算机设备及存储介质。
背景技术:
1、随着语音技术的不断发展,混合语音处理成为了解决复杂语音环境中的重要问题。混合语音处理的核心在于从混合的语音数据中提取出各个单独目标的语音,即语音分离技术。语音分离技术在含噪、含混响等复杂环境中尤为重要,是语音识别等后端应用的关键前端技术。
2、传统的频域处理方法在处理非平稳信号时存在局限性,难以保证语音分离的质量和实时性。其次,基于时域的语音分离方法虽然具有更高的计算效率,但在处理复杂语音环境时仍面临挑战,如噪声干扰、混响等。此外,现有的语音分离算法在应对不同场景和需求时,往往需要针对具体场景进行定制和优化,缺乏通用性和灵活性。
技术实现思路
1、有鉴于此,本发明实施例提供了一种混合语音的处理方法、装置、计算机设备及存储介质,以解决现有混合语音处理技术在复杂环境下语音分离性能不足和缺乏通用性的问题。
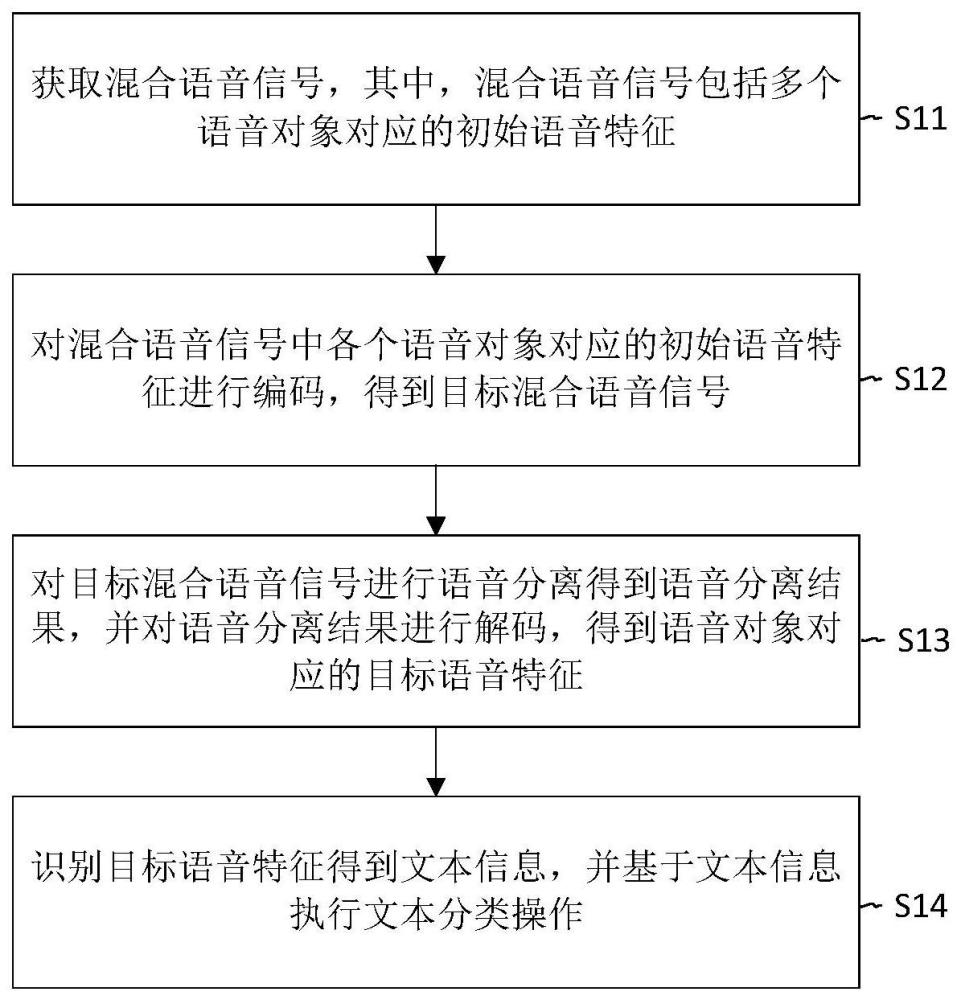
2、第一方面,本发明实施例提供了一种混合语音的处理方法,所述方法包括:
3、获取混合语音信号,其中,所述混合语音信号包括多个语音对象对应的初始语音特征;
4、对所述混合语音信号中各个语音对象对应的初始语音特征进行编码,得到目标混合语音信号;
5、对所述目标混合语音信号进行语音分离得到语音分离结果,并对所述语音分离结果进行解码,得到所述语音对象对应的目标语音特征;
6、识别所述目标语音特征得到文本信息,并基于所述文本信息执行文本分类操作。
7、进一步的,所述对所述混合语音信号中各个语音对象对应的初始语音特征进行编码,得到目标混合语音信号,包括:
8、对所述混合语音信号进行傅里叶变换,得到变换后的混合语音信号;
9、将所述变换后的混合语音信号输入编码器;
10、通过所述编码器将所述变换后的混合语音信号中各个语音对象对应的初始语音特征映射为目标维度的语音特征;
11、基于各个语音对象的语音特征构建所述目标混合语音信号。
12、进一步的,所述对所述目标混合语音信号进行语音分离得到语音分离结果,包括:
13、将所述目标混合语音信号输入语音分离网络;
14、通过所述语音分离网络识别各个所述语音对象的语音特征,并对所述语音对象的语音特征进行分离,得到所述语音分离结果。
15、进一步的,所述对所述语音分离结果进行解码,得到所述语音对象对应的目标语音特征,包括:
16、基于所述语音对象的语音特征计算所述语音对象对应的语音掩码特征;
17、对所述语音对象对应的语音掩码特征进行解码,得到所述语音对象对应的目标语音特征。
18、进一步的,所述对所述语音对象对应的语音掩码特征进行解码,得到所述语音对象对应的目标语音特征,包括:
19、将所述语音掩码特征与所述目标混合语音信号中所述语音对象对应的语音特征进行点乘得到所述语音对象对应的目标语音特征。
20、进一步的,在基于所述文本信息执行文本分类操作之前,所述方法还包括:
21、获取训练数据集,其中,所述训练数据集包括文本样本以及真实分类标签;
22、将所述文本样本输入至初始语言模型,得到样本特征;
23、利用所述全连接层对所述样本特征进行处理,得到对应的分类结果;
24、利用所述分类结果与所述真实分类标签更新所述初始语言模型的模型参数,得到文本分类模型。
25、进一步的,所述利用所述分类结果与所述真实分类标签更新所述初始语言模型的模型参数,得到文本分类模型,包括:
26、计算所述分类结果与所述真实分类标签之间的损失值;
27、利用反向传播算法计算所述损失值对于所述初始语言模型的模型梯度;
28、根据所述模型梯度以及优化算法更新所述初始语言模型的模型参数,直至所述初始语言模型的模型梯度达到预设条件,将所述初始语言模型作为所述文本分类模型。
29、第二方面,本发明实施例提供了一种混合语音的处理装置,所述装置包括:
30、获取模块,用于获取混合语音信号,其中,所述混合语音信号包括多个语音对象对应的初始语音特征;
31、编码模块,用于对所述混合语音信号中各个语音对象对应的初始语音特征进行编码,得到目标混合语音信号;
32、分离模块,用于对所述目标混合语音信号进行语音分离得到语音分离结果,并对所述语音分离结果进行解码,得到所述语音对象对应的目标语音特征;
33、分类模块,用于识别所述目标语音特征得到文本信息,并基于所述文本信息执行文本分类操作。
34、第三方面,本发明实施例提供了一种计算机设备,包括:存储器和处理器,存储器和处理器之间互相通信连接,存储器中存储有计算机指令,处理器通过执行计算机指令,从而执行上述第一方面或其对应的任一实施方式的方法。
35、第四方面,本发明实施例提供了一种计算机可读存储介质,该计算机可读存储介质上存储有计算机指令,计算机指令用于使计算机执行上述第一方面或其对应的任一实施方式的方法。
36、本技术实施例提供的方法具有以下有益效果:
37、本技术实施例提供的方法通过获取混合语音信号为后续步骤(如语音分离、特征提取、识别等)提供了基础数据。混合语音信号中包含多个语音对象的初始语音特征,可以从中提取出多个人的语音信息。对于多人对话、会议记录、多人语音交互等场景效果明显,可以实现对多个语音对象的独立分析和处理。通过获取混合语音信号并对其进行处理,提高了语音处理的效率,节省了计算资源和时间。
38、本技术实施例提供的方法通过对混合语音信号进行傅里叶变换,将其从时域转换到频域,这有助于后续步骤中提取和分析语音的频域特征。通过编码器将频域中的语音特征映射到目标维度的语音特征,以便有效地学习和提取语音信号中的复杂特征。通过基于各个语音对象的语音特征构建目标混合语音信号,生成一个能够代表原始混合语音信号的新信号,该信号在后续处理中(如语音分离)更加有效和高效。
39、本技术实施例提供的方法利用专门的语音分离网络,精确地识别和分离混合语音信号中的各个语音对象特征,有效减少噪声和干扰,使得目标语音更加清晰。通过计算并解码语音掩码特征,准确恢复原始语音信号,提高了语音处理的效率和准确性。通过点乘操作解码语音掩码特征,获得高维度的语音特征,为后续的语音识别和文本分类提供了高质量的数据支持。
40、本技术实施例提供的方法通过对目标语音特征进行识别,可以准确地提取出其中的文本信息。实现了语音特征与文本信息的高效转化。基于提取的文本信息执行文本分类操作,可以实现自动化的文本处理和分析,提高了文本处理的效率,减少人工干预的需求。通过对文本信息进行分类,可以为后续的决策和应用提供有力的数据支持。
41、本技术实施例提供的方法通过使用训练数据集,其中包含文本样本和对应的真实分类标签,可以对初始语言模型进行有针对性的训练。将文本样本输入初始语言模型可以得到样本特征,实现了对文本数据的特征提取和表示,为后续的分类任务提供了有效的数据输入。利用全连接层对样本特征进行处理,得到对应的分类结果,实现了对提取的特征进行加权和激活,从而生成分类决策。通过不断调整全连接层的参数,可以优化模型的分类性能。通过计算分类结果与真实分类标签之间的损失值,并利用反向传播算法计算模型梯度,实现了对初始语言模型参数的调整和优化。
- 还没有人留言评论。精彩留言会获得点赞!