基于人工智能图像识别技术的面部特征提取系统的制作方法
本申请涉及智能提取领域,且更为具体地,涉及一种基于人工智能图像识别技术的面部特征提取系统。
背景技术:
1、声像档案是指以音频和视频形式记录的档案资料。它们可以包括会议、培训、演讲、采访等各种类型的声音和图像记录。声像档案承载着珍贵的信息和记忆,对于研究、教育、娱乐和文化传承都具有重要意义。
2、但由于现有的声像档案传统的声像档案通常以线性方式存储,要找到特定的声音或图像记录需要进行物理检索,耗时且容易出错,且无法依靠人脸的面部信息进行匹配并进行检索。而且传统档案中的信息没有索引或标签,需要人工浏览或依赖记忆来找到所需内容,耗时较长,效率较低。
3、因此,期待一种优化的基于人工智能图像识别技术的面部特征提取系统。
技术实现思路
1、为了解决上述技术问题,提出了本申请。本申请的实施例提供了一种基于人工智能图像识别技术的面部特征提取系统,其采用基于深度神经网络模型的人工智能技术,获取人物在活动中记录下的视频,并对其进行人脸面部图像识别和面部特征分析处理来确定该视频人物是否和现存面部特征库匹配。通过该方法能够快速准确地定位和检索声像档案中的特定人脸面部信息,避免了传统物理检索的耗时和出错问题,提高了声像档案管理的效率和使用的便捷性。
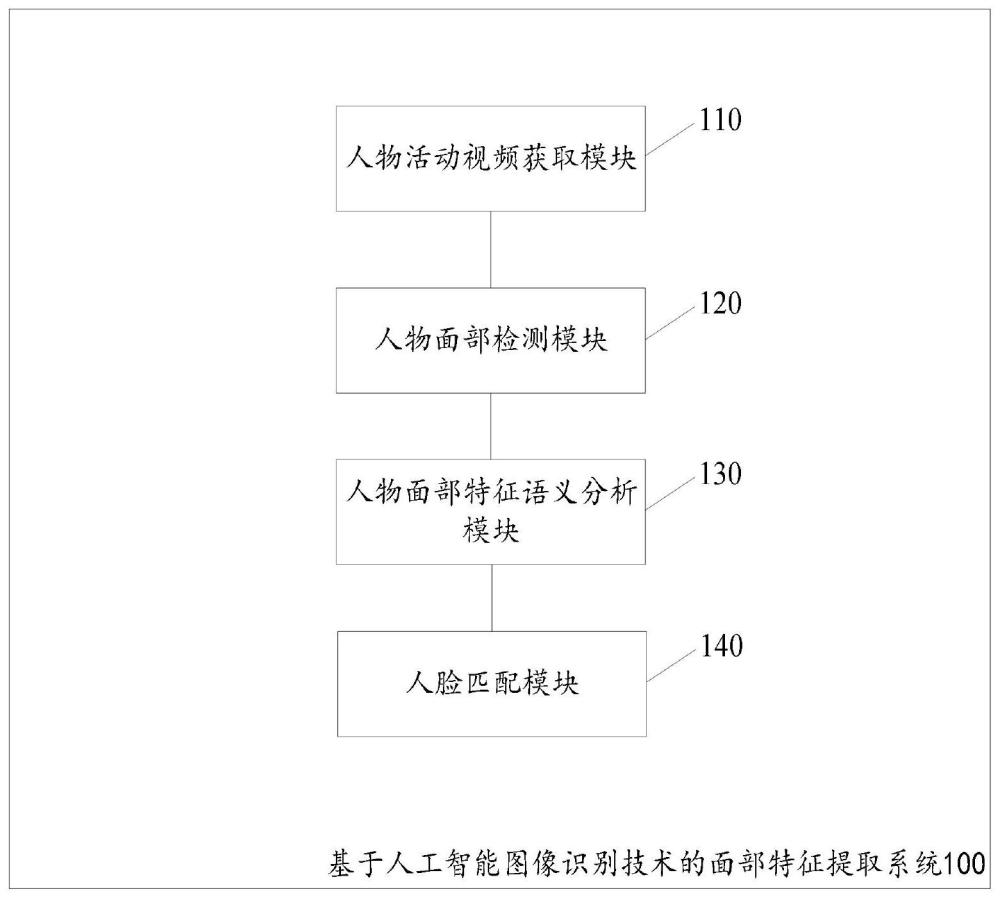
2、根据本申请的一个方面,提供了一种基于人工智能图像识别技术的面部特征提取系统,其包括:
3、人物活动视频获取模块,用于获取人物在活动中记录下的视频;
4、人物面部检测模块,用于对所述人物在活动中记录下的视频进行人物面部检测以得到人脸面部检测关键帧的的序列;
5、人物面部特征语义分析模块,用于对所述人脸面部检测关键帧的的序列进行面部特征语义分析处理以得到人脸面部全局语义理解特征向量;
6、人脸匹配模块,用于基于所述人脸面部全局语义理解特征向量,确定该视频人物是否和现存面部特征库匹配。
7、与现有技术相比,其采用基于深度神经网络模型的人工智能技术,获取人物在活动中记录下的视频,并对其进行人脸面部图像识别和面部特征分析处理来确定该视频人物是否和现存面部特征库匹配。通过该方法能够快速准确地定位和检索声像档案中的特定人脸面部信息,避免了传统物理检索的耗时和出错问题,提高了声像档案管理的效率和使用的便捷性。
技术特征:
1.一种基于人工智能图像识别技术的面部特征提取系统,其特征在于,包括:
2.根据权利要求1所述的基于人工智能图像识别技术的面部特征提取系统,其特征在于,所述人物面部检测模块,包括:
3.根据权利要求2所述的基于人工智能图像识别技术的面部特征提取系统,其特征在于,所述人脸目标检测单元,用于:将所述人物活动关键帧的序列通过人脸目标检测模块进行人脸面部检测以得到所述人脸面部检测关键帧的的序列。
4.根据权利要求3所述的基于人工智能图像识别技术的面部特征提取系统,其特征在于,所述人物面部特征语义分析模块,包括:
5.根据权利要求4所述的基于人工智能图像识别技术的面部特征提取系统,其特征在于,所述人脸面部特征语义理解单元,用于:将所述人脸面部检测关键帧的的序列通过包含嵌入层的vit模型以得到所述人脸面部局部语义理解特征向量的序列。
6.根据权利要求5所述的基于人工智能图像识别技术的面部特征提取系统,其特征在于,所述人脸面部特征全局语义融合单元,用于:将所述人脸面部局部语义理解特征向量的序列通过双向lstm模型以得到人脸面部全局语义理解特征向量。
7.根据权利要求6所述的基于人工智能图像识别技术的面部特征提取系统,其特征在于,所述人脸匹配模块,包括:
8.根据权利要求7所述的基于人工智能图像识别技术的面部特征提取系统,其特征在于,所述面部特征优化单元,用于:对所述人脸面部全局语义理解特征向量进行节点间拓扑平滑运动交互以得到所述优化人脸面部全局语义理解特征向量。
9.根据权利要求8所述的基于人工智能图像识别技术的面部特征提取系统,其特征在于,所述面部特征优化单元,用于:以如下优化公式对所述人脸面部全局语义理解特征向量进行节点间拓扑平滑运动交互以得到所述优化人脸面部全局语义理解特征向量;
技术总结
本申请涉及智能提取领域,其具体地公开了一种基于人工智能图像识别技术的面部特征提取系统,其采用基于深度神经网络模型的人工智能技术,获取人物在活动中记录下的视频,并对其进行人脸面部图像识别和面部特征分析处理来确定该视频人物是否和现存面部特征库匹配。通过该方法能够快速准确地定位和检索声像档案中的特定人脸面部信息,避免了传统物理检索的耗时和出错问题,提高了声像档案管理的效率和使用的便捷性。
技术研发人员:陈晓亮,安雯,韩志军,王霞,高晓红,丰卫东,程伟亭,张昊
受保护的技术使用者:国网山西省电力公司超高压变电分公司
技术研发日:
技术公布日:2024/3/17
- 还没有人留言评论。精彩留言会获得点赞!