一种基于DDQN算法的配送车辆动态调度优化方法
本发明涉及生鲜配送车辆调度,具体为一种基于ddqn算法的配送车辆动态调度优化方法。
背景技术:
1、近年来,我国肉类、水果、蔬菜等生鲜产品市场需求快速增长;由于生鲜产品的易腐性和保质期限制,时效性要求非常高,确保及时送达对于保持产品的新鲜度和质量至关重要,配送车辆必须在最短的时间内将产品从供应链中的中转站或仓库送达到目的地,以确保产品的新鲜度和质量;生鲜产品的订单需求通常多样化,各类产品具有不同的特性和处理要求,例如需要冷藏、冷冻或保持特定的湿度等,车辆调度时需要考虑不同类型产品的特殊需求;需要利用深度强化学习的技术提高生鲜配送动态车辆调度的效率。
2、相关技术中,在研究生鲜配送车辆调度时,往往把把该类问题视为mdp(markovdecision process),假设分配发生在固定的时间间隔内;由于分配的时候要考虑所有可能,多对多分配调度问题会导致分配空间的组合复杂性过高,不仅系统资源利用率和调度效率较低还会简化分配限制因素,容易造成生鲜配送延迟,导致生鲜产品时效性下降。为了解决上述问题,本发明提出了一种基于ddqn算法的配送车辆动态调度优化方法。
技术实现思路
1、(一)解决的技术问题
2、本发明的目的在于提出一种基于ddqn算法的生鲜配送动态车辆调度优化方法以解决背景技术中所提出的问题。本发明显著降低了分配空间的组合复杂性,在考虑多个分配限制因素的同时,表现出更好的平均分配时间。通过提高系统资源利用率和调度效率,解决了生鲜配送延迟导致生鲜产品时效性下降的问题。
3、(二)技术方案
4、为了实现上述目的,本发明采取的技术方案为:
5、一种基于ddqn算法的配送车辆动态调度优化方法,包括以下步骤:
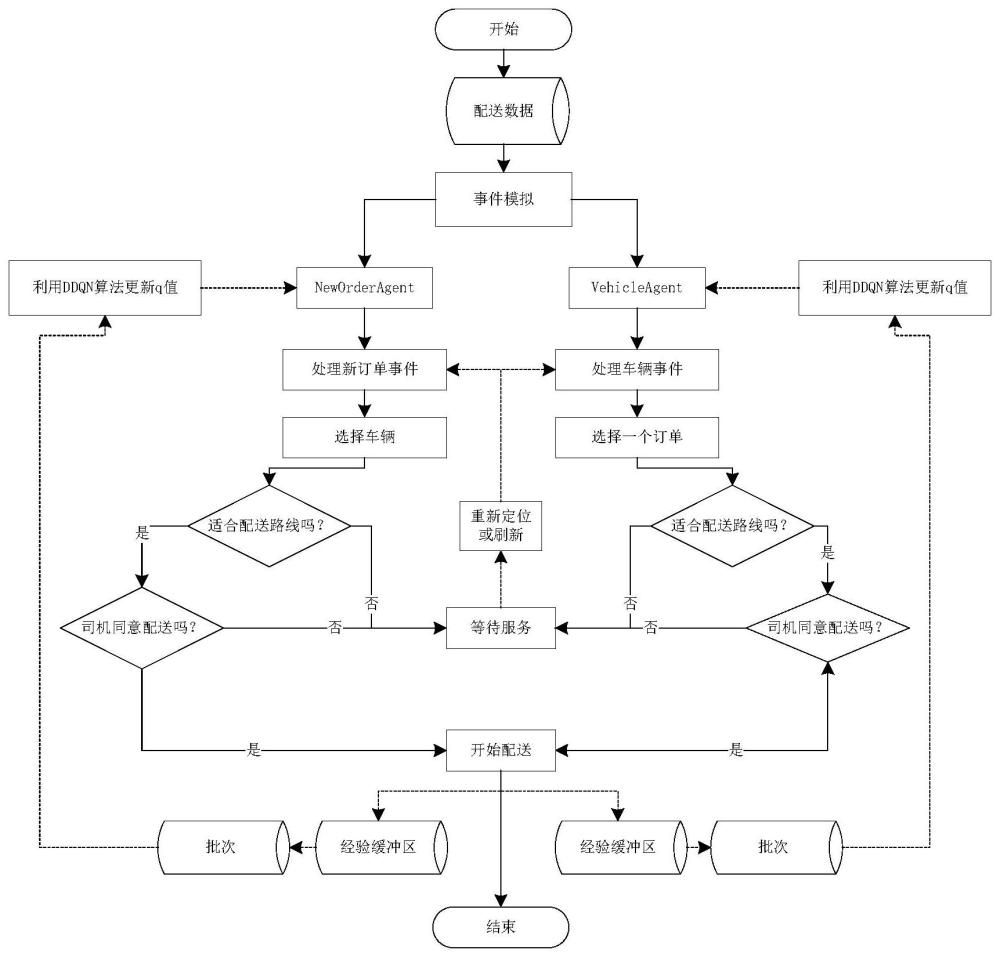
6、s1、将生鲜配送中的动态车辆调度问题视为基于smdp(semi-markov decisionprocess)框架的连续时间过程:本方法根据生鲜配送订单随时间随机出现、连续分配之间时间间隔随机的特性,拟定了基于事件的smdp公式,并定义了smdp的基本构成:环境、状态、动作空间、奖励函数和环境动力学。在系统中,明确定义两个触发分配的重要事件:“新订单事件”和“车辆事件”,将原本的多对多分配调度问题简化为一对多分配调度问题。
7、s2、利用离散事件模拟器(discrete event simulation,des)进行模拟:本方法使用python配置模拟器。模拟器的组成包括三类对象:基本实体、agent和环境。该模拟器的工作原理是维护按时间顺序排列的订单列表,并使用特定的处理例程来处理这些事件。
8、在模拟过程中,考虑了驾驶员一方拒绝配送订单的可能性,用概率分布表示驾驶员拒绝的概率,并使用β密度函数对其进行建模,最后,agent利用该概率执行伯努利试验来确定是否拒绝订单。
9、s3、训练agent:本方法结合了真实世界数据和模拟数据,运用ddqn(double deepq-learning)算法来同时训练双agent,使它们能够针对"新订单"和"车辆"这两个事件做出调度分配。为了解决传统q-learning训练中存在的高估偏差问题,采用了double q-learning算法。
10、优选的,所述s1具体包括以下步骤:
11、s1-1、表示环境:
12、本发明使用一个基于纬度和经度的简单坐标系统来表示车辆和目的地的位置,将环境表示为可以发出配送订单的空间;
13、s1-2、拟定的基于事件的smdp公式:
14、smdps(semi-markov decision processes)是指由多个smdp组成的集合,目标函数如下:
15、
16、其中,sk表示在决策时期tk的状态,连续决策时期tk和tk+1之间的时间间隔是随机变量,在区间上积分奖励函数,并且e-βt表示连续时间的离散时间贴现因子γ的极限形式,其中e-β=γ;。
17、本发明定义了系统中的两个重要事件:“新订单的出现”(新订单事件)和"车辆容量空余"(车辆事件),它们会触发调度分配。在新订单事件中,问题被简化为选择最适合车辆来配送指定新订单;在车辆事件中,问题被简化为选择最适合的一系列订单让指定车辆进行配送。
18、s1-3、定义状态和动作空间:
19、系统的状态取决于触发的事件。在车辆事件时,状态由特定车辆表示,动作由未分配的订单确定;在新订单事件时,状态由特定订单表示,并通过考虑可用车辆来建立动作。同时,本发明还添加了三个上下文特征:资源需求比、周期特征1和周期特征2。agent的数据结构与特定事件一致,能够根据相关信息做出明智的分配。
20、s1-4、定义奖励功能:
21、agent根据配送行程持续时间和车辆揽货时间获得奖励。普通奖励r由两部分组成:当agent负责新订单事件时,表示从始发地到目的地所需的估计时间,此时超参数b基于现实经验数据制定,表示生鲜品类的保鲜时限,低b值鼓励agent提高该订单的优先级,以间接减少配送的总持续时间;当agent负责车辆事件时,表示车辆揽货时间,超参数b表示生鲜品类的保鲜时限,低b值鼓励agent选择离取货地点近的车辆,以间接减少车辆揽货时间;
22、s1-5、环境动力学中的逻辑定义:
23、环境随着时间的推移而不断演变,状态转换发生在离散的时间点,而在一段随机的时间内可以保持在给定的状态。环境包括六个主要的随机性来源:订单在环境中以随机时间出现,车辆在地点之间的移动需要不同的持续时间,车辆具有不同的可用性(包括容量、冷藏设备和其他要求),驾驶员以一定概率可能拒绝agent提供的调度建议,客户的最长容忍车辆揽货时间具有未知的概率分布,不同生鲜品类的保鲜时限长短有所不同。
24、优选的,所述基本实体的类定义为order类和vehicle类。order类表示客户发出的订单请求,主要属性包括创建时间、起点、目的地和客户最长容忍车辆揽货时间。vehicle类表示模拟器中的车辆,主要属性包括当前位置、路线规划和车辆可用性(包括容量、冷藏设备以及其他要求)。
25、优选的,所述agent的类定义为vehicleagent类和neworderagent类。vehicleagent类负责从订单池中选择订单,而neworderagent类负责选择车辆,两个agent类非常相似,主要区别于它们的动作集;
26、优选的,所述环境(environment)类是模拟器的核心,它配置多个模拟参数(如车队中的车辆数量、车辆的平均速度和每日最大订单数),控制整个生鲜配送车辆调度流程。
27、优选的,所述“新订单事件”触发时,neworderagent立即扫描车队中的所有车辆,选择可用性、容量最适合的车辆。如果选择的车辆也适合配送路线,智能体将启动分配并在司机确认后开始配送。如果所选车辆不适合配送路线,系统将把订单放置在未响应订单池中,直到它被分配到适合的车辆。
28、优选的,所述“车辆事件”触发时,vehicleagent查询订单池,以确定配送要求、货物大小适合的订单。如果选择的订单也适合配送路线,智能体会启动分配并在司机进行确认之后开始取货配送;如果所选订单不适合配送路线,则系统将车辆放在车辆池中,直到它被分配到合适订单;
29、优选的,所述s3具体包括以下步骤:
30、s3-1、收集数据:
31、模拟器利用真实数据中的出发地、目的地位置和到达时间,并使用概率分布进行数据模拟,将真实世界和模拟数据结合起来,用于训练本发明的agent。
32、s3-2、分类agent:
33、由于在dvdp的smdp公式中,分配发生在两种不同类型的事件中,因此本发明训练两种不同的代理:neworderagent和vehicleagent。
34、s3-3、采样转换:
35、在训练过程的初始阶段,agent了解环境中的行为后果后会随机做出动作并收集一系列的经验转换(由元组表示:当前状态,下一个状态,动作,奖励,事件持续时间)。随着模拟的进行,这些转换被存储在一个称为“经验缓冲区”(experience buffer,eb)的池中;为了保证训练所需的样本多样性、打破时间上的相关性并减少数据的非平稳性,agent通过从“经验缓冲区”中随机选择一批经验转换组成批次(batch)。
36、s3-4、深度神经网络驱动:
37、每个agent都有两个深度神经网络,它们除参数外具有相同的结构。当“经验缓冲区”积累了一定数量的样本后,批次中的经验元组相互连接,表示特定上下文中车辆和订单之间的潜在分配。
38、这些经验元组被输入执行梯度步骤,通过反向传播算法更新深度神经网络的参数。其中一个神经网络在每一步都执行梯度下降,而另一个神经网络在一定数量的步骤之后才进行参数更新,以控制网络参数同步。
39、深度神经网络结合ddqn(double deep q-learning)算法,使用两个函数qa和qb,每个q函数使用另一个q函数的值更新下一个状态,以驱动agent更准确地估计当前状态和动作的q值,以qa为例:
40、
41、其中,s表示智能体所处的环境状态;a表示智能体在给定状态下选择的行动;s’表示在执行动作a后智能体进入的新状态;r表示智能体在执行动作后从环境中获得的即时奖励;γ=e-βτ为折扣因子,表示对未来奖励的重要性衰减率;α为学习率,表示在更新q值时的学习速率,其决定了新的估计值在更新q值时对旧的估计值的相对重要性,表示在状态s’下选择具有最大q值的动作a;。
42、agent会根据估计的q值选择具有最大q值的动作。neworderagent将新到达的订单分配给可用车辆,而vehicleagent安排容量空余的车辆服务于等待的订单。
43、(三)有益效果
44、与现有技术相比,本发明提供了一种基于ddqn算法的生鲜配送动态车辆调度优化方法,具备以下有益效果:
45、1、本发明通过将深度强化学习技术引入生鲜配送车辆调度技术领域,将生鲜配送动态车辆调度问题视为基于smdp框架的连续时间过程,大大缩短了agent的调度时间;运用ddqn算法来训练双agent各自针对“新订单事件”、“车辆事件”双事件做出调度决策,大大降低了决策空间的组合复杂性,在考虑多个分配限制因素的同时,提高了系统资源利用率和调度效率。
46、2、本发明通过提高系统资源利用率和调度效率,进而保障生鲜的时效性和确保订单及时送达,有效解决了生鲜配送延迟导致生鲜产品时效性下降的问题;同时考虑多个分配限制因素,可以更全面地评估和满足订单的多样化需求,并确保在满足限制条件的前提下进行高效的分配,有效解决了由温度控制不当、储存空间不足、配送路线不合理等车辆分配不合理的情况导致生鲜产品品质受损的问题。
- 还没有人留言评论。精彩留言会获得点赞!