一种基于网络爬虫的软件满意度评价方法与流程
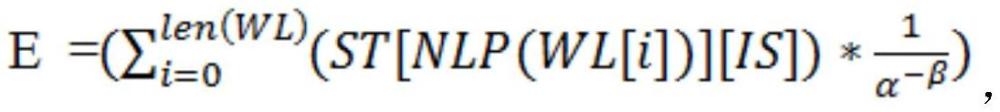
本发明提供了一种基于网络爬虫的软件满意度评价方法,属于计算机大数据。
背景技术:
1、在当前的数字化时代,软件应用已经成为人们工作和日常生活的必备工具。然而,市场上存在着大量的软件产品,用户往往需要面临选择的难题。为了评估软件的质量和性能,用户满意度成为了一个重要的指标。
2、用户评论作为评价软件品质的重要依据之一,被其他用户广泛参考,然而网络上存在大量网络水军发布虚假评论,与普通用户评论混杂一起。面对此现象现有解决方案并不完善,缺少一个标准化的评判系统,使其他用户难以准确评估软件的真实质量。
技术实现思路
1、本专利提出一种基于网络爬虫的软件满意度评价方法,能够对软件评论的参考度和情感评价进行综合评估,评估准确,考虑因素全面,能够供其他用户参考。
2、实现本发明上述目的所采用的技术方案为:
3、一种基于网络爬虫的软件满意度评价方法,包括以下步骤:
4、(1)在不同的应用商店和/或网站,利用网络爬虫程序对目标软件的评论数据进行爬取,并对获取的评论数据进行预处理,对预处理后评论数据进行本地存储;
5、(2)提取预处理后评论数据中的关键词和/或短语,构建情感词库分值表st,类别pi分为积极、较积极、中性、较消极和消极五类,给每一类别分配分值is;对关键词和/或短语进行分析,判断其情感倾向对应类别,得出筛选后评价词列表wl,最后根据评价词列表wl来计算评价值e,并根据评价值e的范围划分对应的评论得分cs;
6、(3)构建参考值系统
7、(3.1)对预处理后评论数据中的评论文本长度cl进行提取,并通过爬取计算出评论文本平均长度根据评论文本长度cl和评论文本平均长度计算文本倍值tt,并根据文本倍值tt的范围划分对应的文本参考值tr;
8、(3.2)对预处理后评论数据中的图片和视频文件进行提取,识别图像中的关键特征,推算出图片文件pi内容与被评价软件的相关度rri,并统计累计图片文件出现次数pn;通过出现次数pn计算图片上传值pu;
9、读取视频信息获取时评时长,并加以累计得出所有视频总时长vt,将所有视频文件整合至一个视频文件,对视频内容识别得出内容与该软件相关度vl;通过视频总时长vt计算视频上传值vu;
10、利用相关度rri和vl,以及图片上传值pu和视频上传值vu计算出文件参考值pr;
11、(3.3)获取版本日志列表标签以及版本日期列表,将版本vi共分为大版本、小版本和补丁三种,根据当前评论发布时间得出评论时的版本vo,与最新版本vn求差值,根据版本差值计算补丁差p,并根据补丁差p的范围划分对应的版本参考值vr;
12、(3.4)分别向文本参考值tr、文件参考值pr以及版本参考值vr赋予不同的权重,并叠加计算当前评论参考值a;
13、(4)用步骤(3)中参考值系统对爬取的评论进行参考值计算,预设c为参考值条件,筛选参考值a大于等于c的评论fc;使用步骤(2)中评价系统对筛选后评论fc进行评价值计算当前评论的评价值ei,并结合对应评论的参考值ai得出该评论综合得分,最后算出软件满意度得分软件满意度得分越高时用户满意度越高,反之越低,最后根据软件满意度得分的范围划分对应的评价状况。
14、进一步的,步骤(1)中数据的预处理,包括去除重复评论、去除无效评论、去除广告和垃圾信息。
15、进一步的,步骤(2)中通过查找html标签、css选择器定位和提取目标数据,编写正则表达式匹配到评论文本和文件地址,根据文件地址后缀名判断出视频文件,利用googlecloud speech-to-text自动语音识别工具将视频中音频转换为文本内容,使用textrank技术提取评论文本和视频转化后文本中的关键词和/或短语。
16、进一步的,步骤(2)中类别pi分为p1积极、p2较积极、p3中性、p4较消极和p5消极五类,给每一类别分配分值is分别为10、8、5、-10、-15;
17、评价值e的计算公式为:其中α为该情感类别出现次数;β取值0.2-0.4,情感类别越中性β值越大;
18、根据评价值e的范围划分对应的评论得分cs,具体为:e≥30时评论得分cs=100,20≤e<30时评论得分cs=90,10≤e<20时评论得分cs=75,5≤e<10时评论得分cs=60,-5≤e<5时评论得分cs=45,e<-5时评论得分cs=0。
19、进一步的,步骤(3.1)中使用选择器或xpath工具,从爬虫数据中选择并提取文本内容,利用正则表达式对文本中内容进行匹配,替换掉特殊符号,仅保留评论文本并得出当前被评判评论文本长度cl;
20、将累计被爬取评论文本总长度记为ct,ct从0开始,每处理好一段评论文本ci,将ct更改为ct+文本ci长度;最后根据ct与爬取评论数量cn计算出评论平均长度并保存至本地,
21、文本倍值tt=当前评论文本长度cl/评论平均长度当cl越大于tt时,评论参考价值越高,反之参考价值越低,文本倍值tt的范围划分对应的文本参考值tr具体为:tt≥300%时文本参考价值tr=100%,200%≤tt<300%时文本参考价值tr=80%,100%≤tt<200%时文本参考价值tr=60%,20%≤tt<100%时文本参考价值tr=30%,tt<20%时文本参考价值tr=0%。
22、进一步的,步骤(3.2)中使用选择器或xpath工具从评论数据中精确地选择到img和video标签,编写正则表达式精确匹配当前评论中所出现文件地址路径,通过地址路径后缀判断图片或视频文件;
23、使用opencv技术识别图像中的关键特征,相关度rri最大为100%,最小为0%,累计图片文件出现次数pn,pn起始值为0,每检查到一张图片是pn+1;使用video构造函数读取视频信息获取时评时长;利用ffmpeg框架将所有视频文件整合至一个视频文件;使用卷积神经网络算法对视频内容识别;相关度vl最大为100%,最小为0%;
24、图片上传值pu以及视频上传值vu的计算方式如下:pn≥9时图片上传值pu=100%,7≤pn<9时图片上传值pu=90%,5≤pn<7时图片上传值pu=80%,3≤pn<5时图片上传值pu=70%,1≤pn<3时图片上传值pu=50%,pn=0时图片上传值pu=0%;vt≥60秒时视频上传值vu=100%,40秒≤vt<60秒时视频上传值vu=85%,20秒≤vt<40秒时视频上传值vu=75%,10秒≤vt<20秒时视频上传值vu=65%,1秒≤vt<10秒时视频上传值vu=50%,vt=60秒时视频上传值vu=0%;
25、文件参考值pr的计算公式为:
26、其中x与文件上传值fv相关,当文件上传值fv越大时x取值越大,反之越小,文件上传值fv起始值为0,每累计一张图片和视频时长每超过5的倍数则自增1。
27、进一步的,步骤(3.3)中使用选择器或xpath工具获取版本日志列表标签,编写正则表达式精确匹配到软件历史版本号和相应的推送日期得出版本日期列表;版本进制关系为10,补丁差p的计算公式为当补丁差p值越小时,版本参考值vr越大,反之版本参考值vr越小,补丁差p的范围对应的版本参考值vr具体为:pn=0时版本参考值vr=100%,0<pn<10时版本参考值vr=90%,10≤pn<50时版本参考值vr=80%,50≤pn<100时版本参考值vr=60%,pn≥100时版本参考值vr=50%。
28、进一步的,步骤(3.4)中还设置一个匿名参考值o,向文本参考值tr、文件参考值pr以及版本参考值vr和匿名参考值o赋予不同的权重x、y、z、m,x+y+z+m=100,且要求x>y>z>m。
29、进一步的,步骤(4)中软件满意度得分的计算公式为:其中len(fc)为评论fc的总条数。
30、进一步的,步骤(4)中软件满意度得分的范围划分对应的评价状况具体为:90时评价为体验优良,时评价为体验不错,时评价为体验一般,时评价为体验不佳。
31、与现有技术相比,本发明提供的基于网络爬虫的软件满意度评价方法具有以下优点:1、本发明中的原始评论数据来源自各个应用商店和下载网站,其覆盖面广,更能全面整体的反应目标软件的评价状况。同时本发明中对所获取的评论数据进行了预处理,包括去除重复评论、去除无效评论(如广告、垃圾信息)等,因此能够更为客观、准确的反应目标软件的评价状况。2、本发明中不单单根据情感词库进行分类并分配分值,同时还充分考虑到了各个评论的文本参考值、文件参考值以及版本参考值并赋予不同权重,因此对软件的评价方式更为合理。
- 还没有人留言评论。精彩留言会获得点赞!