基于FPGA加速的低比特光场图像深度估计网络及方法
本发明涉及轻量化光场深度估计网络设计与fpga实现,更具体的说,涉及一种基于fpga加速的低比特光场图像深度估计网络及方法。
背景技术:
1、高精度、快速计算的光学影像深度信息获取一直是计算机视觉的主要挑战之一。为处理该类问题,现有工作在cpu和gpu上探索快速高精度网络设计,以从复杂的光场影像中计算准确的深度信息。然而,随着无人自主系统的发展,系统续航能力受到研究者的关注。为了更好服务于无人自主系统在深空、深海、深地等领域的进一步应用,研究者们基于fpgas、asics等设备开始探索低功耗高精度快速视觉计算技术。这些方法在理论和关键技术上都取得了不错成果,但它们基于传统小孔成像进行反演计算,难以突破传统成像模型的局限。
2、相较于上述传统成像模型的方法,光场图像在空间域、视角、光谱以及时间域等多维度上具备耦合特性,为单一视角下高精度深度信息获取提供了先天优势。由于光场图像的单镜头多图片的丰富信息优势,倍受深度估计、三维重建等工作者青睐。甚至一些先进工作在gpu上已经取得了出色的效果。然而,在资源受限设备部署中,光场图像三维计算仍然面临严峻挑战。在高维计算方面,一些方法由于引入了3d卷积,增加了硬件设计的复杂度。而在资源受限方面,其他方法采用了复杂的网络结构并涉及大量的网络参数,这增加了硬件设计的不可行性。至于低功耗快速计算,现有的先进算法都需要大量的功耗来维持快速浮点数计算,这与硬件设计的初衷背道而驰。
3、深度压缩和模型量化是实现网络轻量化的关键策略。并且在模型量化中,低比特量化技术由于其卓越的硬件友好性深受研究人员青睐。shufflenet、mobilenet和efficientnet等深度压缩工作以及bnn、xnor-net、twn、dorefa-net等量化工作的出现为大规模网络架构的硬件部署奠定了坚实的理论基础,为其在资源受限环境下的实际应用提供了重要支撑。在资源受限的设备上成功部署大型网络后,工作转向了提高硬件性能,从而产生了一系列优化策略。并且,cnn加速器技术被大量应用于深度估计任务,如stereoengine、lite-stereo等双目立体匹配加速器的设计推进了深度估计领域的硬件加速。然而,目前针对光场深度估计的低功耗和快速硬件设计的相关研究极为(相对)有限,缺乏深刻而全面的探讨。
技术实现思路
1、针对现有技术存在的不足,本发明的目的在于提供一种基于fpga加速的低比特光场图像深度估计网络及方法,该发明主要用于解决光场深度估计网络的复杂性问题,在macpi基础上,通过结合前置视差信息提取操作、通道和视差维度融合以及分组卷积等关键改进,构建出一个只使用2d卷积的轻量化的硬件友好的深度估计网络,与硬件结合作为低比特低功耗光场图像深度估计加速引擎,用于实现光场图像的深度估计。
2、为实现上述目的,本发明提供了如下技术方案:
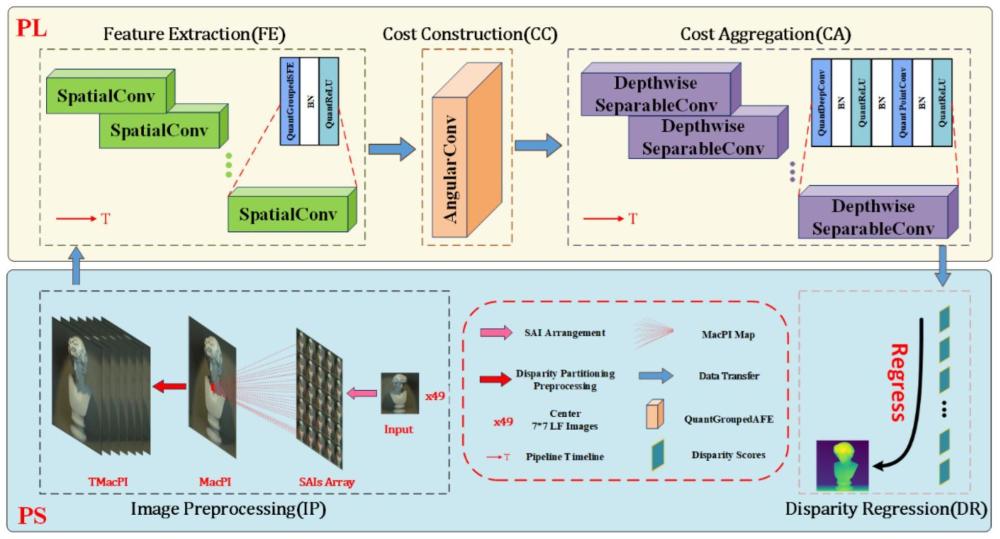
3、一种基于fpga加速的低比特光场图像深度估计网络,包括图像预处理、特征提取、代价构建、代价聚合和视差回归,其中:
4、图像预处理,将视差划分操作前置移至宏像素图像macpi之后,从macpi中提取不同视差的正确像素,获得每个视差下的准确宏像素图像amacpi;所有准确宏像素图像amacpi在通道维度上拼接,获得总的宏像素图像tmacpi;
5、特征提取,对总的宏像素图像tmacpi进行分组的空间特征提取sfe,获得每个视差下的多通道准确宏像素图像mcamacpi;
6、代价构建,对所有准确宏像素图像mcamacpi的所有角块进行分组的角度信息提取afe,为每个视差下的生成高质量低像素多通道代价体;
7、代价聚合,使用2d深度可分离卷积,对获得的代价体做深度卷积以精炼每一个通道,再做逐点卷积以融合所有通道的信息;
8、视差回归,对每个视差的多通道结果进行重新压缩,使用softmax操作在视差维度上进行操作,对代价聚合后的结果进行归一化,得到每个视差下的得分情况,再对这些得分进行视差值加权并进行累加操作,得到最终的估计结果。
9、进一步,使用2d卷积进行光场图像的深度估计。
10、进一步,所述图像预处理中,采用滑动窗口的方法提取每个视差下的像素,为不同视差值在macpi上应用具有不同扩张率和填充值的窗口,以实现从每个sai中提取与中心sai的每个像素点对应的相同真实位置的像素点。
11、进一步,特征提取、代价构建和代价聚合的激活与权重采用不同比特的量化,特征提取的第一层选择8bit权重量化网络,特征提取的其他层选择4bit权重和激活去量化网络,代价构建和代价聚合中将最后一个深度可分离单元设置为8bit权重量化网络,其他层的权重使用4bit权重量化网络,代价构建和代价聚合的激活使用4bit权重量化。
12、一种低比特低功耗光场图像深度估计加速引擎,基于上述的低比特光场图像深度估计网络,包括位于fpga芯片上的可编程逻辑的pl端和位于arm芯片上的处理系统的ps端,特征提取、代价构建和代价聚合在pl端进行加速处理,图像预处理和视差回归在ps端进行处理;使用矩阵向量单元mvu和滑动窗口单元swu作为计算单元和数据处理单元构建硬件卷积单元convu,在硬件加速卷积过程中执行窗口滑动和矩阵乘法运算;
13、所述滑动窗口单元swu使用循环linebuffer结构将输入特征图分解成图像矩阵,使卷积操作转化为矩阵乘法,然后将生成的矩阵通过数据流形式馈送给矩阵向量单元mvu;
14、所述矩阵向量单元mvu从滑动窗口单元swu中获取输入特征的矩阵数据流,并从权重存储单元weightmemory和阈值存储单元thresholdmemory中分别获取权重和预置阈值,然后在一组pe单元中进行计算。
15、进一步,pl端为实时性结构,为每一个卷积单元单独设置硬件结构,形成流水线的硬件结构;为实现优化硬件网络架构,将低比特光场图像深度估计网络中的权重和中间激活值存储在内存和寄存器上。
16、进一步,矩阵向量单元mvu中,卷积操作使用硬件乘法设计实现,批归一化层bn和激活函数层通过预计算转化为阈值比较操作,通过阈值比较将点积结果转化为硬件卷积单元convu的输出值。
17、一种基于fpga加速的低比特光场图像深度估计方法,基于上述的低比特光场图像深度估计网络,具体包括以下步骤:
18、步骤1.利用图像构建低比特光场图像深度估计网络;
19、步骤2.利用步骤1获得的低比特光场图像深度估计网络,并结合硬件设置,构造一个软硬件协同设计的流式网络硬件架构;
20、步骤3.根据步骤2的网络架构以及硬件架构,通过高级层次语言以及硬件编程软件编写硬件实现代码,并将代码烧录至硬件设备,获得低比特低功耗光场图像深度估计加速引擎,利用深度估计加速引擎对光场图像完成深度估计。
21、进一步,步骤1中,利用图像构建低比特光场图像深度估计网络具体步骤如下:
22、步骤1.1对图像进行预处理,获得总的宏像素图像tmacpi;
23、步骤1.2经过图像预处理的图像进行低比特轻量化的2d特征提取;
24、步骤1.3提取的特征利用2d深度可分离卷积进行低比特轻量化的2d代价构建获取代价体;
25、步骤1.4对构建的代价体进行低比特轻量化的2d代价聚合;
26、步骤1.5对聚合后的代价体进行视差回归,获得完整的低比特轻量化的光场深度估计网络。
27、综上所述,发明具有以下有益效果:
28、本发明在macpi基础上,通过结合前置视差信息提取操作、通道和视差维度融合以及分组卷积等关键改进,使用2d卷积的轻量化的硬件友好的深度估计网络,网络结构简单且精度损失小,并采用高效的硬件单元设计和软硬件协同数据流架构,构建了基于fpga的快速、低功耗、低比特的硬件加速引擎,通过融合mvu和swu,并采用了流式硬件架构以及软硬件协同的方法,设计出资源利用合理的快速低功耗的深度估计硬件加速引擎,用于解决光场深度估计网络的复杂性问题。对比mse较低的最先进网络,本发明将计算负载减少109倍以上,权重参数减少约78倍,在zcu104平台上,仅需要221k lut,1394个dsp,252.5个bram和9.493w功耗即可实现延迟低至272ns的高效加速引擎。
- 还没有人留言评论。精彩留言会获得点赞!