一种多节点并发的海量文件备份恢复方法及系统与流程
本发明涉及数据备份与恢复,具体是一种多节点并发的海量文件备份恢复方法及系统。
背景技术:
1、在多节点多分片场景下需要进行流式备份,来消除减少缓存空间和i/o读写的负担。而备份程序又需要多进程并发来提高吞吐效率。此时需要综合考虑备份和恢复时的资源消耗与效率平衡。
2、现有的主流海量文件备份系统会以文件为存储粒度,将文件信息存入第三方数据库中,在备份时会将文件信息插入数据库中,在搜索和恢复文件时会从数据库中查找记录。主流的海量文件备份系统通常使用第三方数据库,如mongdb,来进行索引数据管理。当文件数量超过百万时,会产生一张大表,检索效率会极大的降低。当恢复指定文件时,每次查询必要的文件信息都要耗费大量时间。
技术实现思路
1、为了解决上述问题,本发明提出了一种多节点并发的海量文件备份恢复方法及系统,采用并发传输交叉数据块的备份方式,将所有文件数据流式传入数量较少的存储对象中,来大幅提高检索效率。
2、为了达到上述目的,本发明是通过以下技术方案来实现的:
3、本发明的一种多节点并发的海量文件备份恢复方法,包括以下操作:
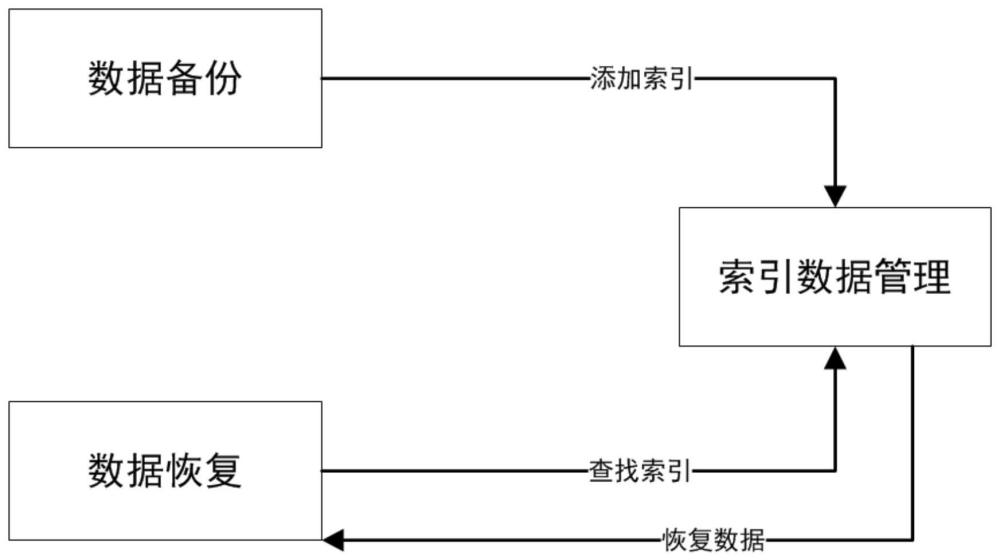
4、数据备份,扫描文件生成索引并添加索引;
5、索引数据管理,包括写入、查找和读取索引文件;
6、数据恢复,查找索引并将查找到的索引恢复到目标路径;
7、数据库分片在进行数据备份操作时,数据库实例中每个数据库分片的每个备份插件均启动一个管道,管理进程同时启动多个java进程,每个java进程对应一个数据库分片,且java进程和备份插件之间通过管道进行交互,多个备份插件同时并发接收传入的数据块,并将数据块写入管道,java进程将对应的数据库分片的所有数据汇总,并上传至介质服务器中,且每个java进程均创立独立的数据存储对象;
8、在进行数据恢复操作时,由数据库实例将恢复请求发送给备份插件,备份插件通过请求管道将恢复请求发送给java进程,java进程接收到恢复请求后,汇总不同请求管道的请求文件,通过查找并读取索引文件,汇总数据块索引中的所有数据块并合并成一个顺序的下载链,按照下载链下载数据块的同时,java进程将已下载的数据块通过管道分发给请求数据的备份插件,备份插件将数据块传递给数据库分片的相关恢复作业进行恢复。
9、本发明的进一步改进在于:所述索引数据管理具体包括:采用超级索引记录数据库分片信息和对应的存储对象中的索引文件地址,实现在分布式场景下按数据库分片查找对应的索引数据;
10、采用索引文件记录索引中各类文件所在的位置和备份的文件信息,索引文件在结构上包括文件节点,hash数组,hash链表和头文件;
11、采用数据存储对象存储备份的文件的数据,且数据存储对象划分为多个相同大小的数据块,单个文件划分到不同的数据块进行存储;
12、采用数据块索引记录每个文件所对应的数据块链表,数据块索引的索引内容包含文件名hash值的inode,数据块的编号列表和在源文件中的偏移位。
13、本发明的进一步改进在于:采用数据存储对象存储备份的文件的数据时,若单一文件的数据无法填满一个数据块,则将数据块分割分配给不同的文件。
14、本发明的进一步改进在于:所述索引文件的文件节点由节点号inode和文件信息构成,其中,对目录或文件的绝对路径进行hash计算得到节点号inode,并用节点号inode作为全局的文件的识别标识。
15、本发明的进一步改进在于:所述索引文件的hash数组和hash链表由对节点号inode进行取模运算得到,具体包括对每个文件节点的节点号inode进行取模,得到取模值,将相同模的inode组成了hash链表,在hash链表中记录inode和对应的文件节点记录在整个索引文件中的偏移量。
16、本发明的进一步改进在于:所述头文件中记录有和索引文件中记录关联的目标文件名和数据块索引的相关信息,文件节点的数量以及文件分组。
17、本发明的一种多节点并发的海量文件备份恢复系统,包括数据备份模块、索引数据管理模块和数据恢复模块;
18、所述数据备份模块,用于扫描文件生成索引并调用索引数据管理模块的接口添加索引;
19、所述索引数据管理模块,用于写入、查找和读取索引文件;
20、所述数据恢复模块,用于调用索引数据管理模块的接口查找索引并将其恢复到目标路径;
21、所述数据备份模块的结构包括多个管道、java进程、数据库实列的多个数据库分片、介质服务器、管理进程,所述数据库分片的每个备份插件均启动一个管道,管理进程同时启动多个java进程,每个java进程对应一个数据库分片,备份插件和java进程之间通过管道进行交互,且java进程与介质服务器直接通过网络长链接进行数据交互,多个备份插件同时并发接收传入的数据块,并将数据块写入管道,java进程将对应的数据库分片的所有数据进行汇总,并上传至介质服务器,每个java进程均创建独立的数据存储对象;
22、所述数据恢复模块的结构包括多个管道、请求管道、java进程、数据库实列的多个数据库分片、介质服务器,所述数据恢复模块进行恢复操作时,由数据库实例将恢复请求发送给备份插件,备份插件通过请求管道将恢复请求发送给java进程,java进程接收到恢复请求后,汇总不同请求管道的请求文件,通过查找并读取索引文件,汇总数据块索引中的所有数据块并合并成一个顺序的下载链,按照下载链下载数据块的同时,java进程将已下载的数据块通过管道分发给请求数据的备份插件,备份插件将数据块传递给数据库分片的相关恢复作业进行恢复。
23、本发明的进一步改进在于:所述索引数据管理模块包括超级索引、索引文件、数据存储对象和数据块索引;
24、所述超级索引,用于在分布式场景下按数据库分片查找对应的索引数据,记录有数据库分片信息和对应的存储对象中的索引文件地址;
25、所述索引文件,用于索引中各类文件所在的位置和备份的文件信息,在结构上包括文件节点,hash数组,hash链表和头文件;
26、所述文件节点由节点号inode和文件信息构成,其中,对目录或文件的绝对路径进行hash计算得到节点号inode,并用节点号inode作为全局的文件的识别标识;
27、所述hash数组和hash链表由对节点号inode进行取模运算得到,具体包括对每个文件节点的节点号inode进行取模,得到取模值,将相同模的节点号inode组成hash链表,在hash链表中记录节点号inode和对应的文件节点记录在整个索引文件中的偏移量;
28、所述头文件中记录有和索引文件中记录关联的目标文件名和数据块索引的相关信息,文件节点的数量以及文件分组;
29、所述数据存储对象,用于存储备份的文件的数据;
30、所述数据块索引,用于记录每个文件所对应的数据块链表,数据块索引的索引内容包含文件名hash值的inode,数据块的编号列表和在源文件中的偏移位。
31、本发明的进一步改进在于:所述数据存储对象被划分为多个相同大小的数据块,单个文件划分到不同的数据块进行存储,若单个文件的数据无法填满一个数据块,则将对应的数据块分割分配给不同的文件。
32、本发明的有益效果是:本发明提供了一种并发传输交叉数据块的备份方式,将所有文件数据流式传入数量较少的存储对象中,来大幅提高检索效率。本发明相对于现有技术具有以下优点:
33、占用系统资源少,通过对索引和目录存储的设计,源码部分大小不超过200 kb。备份百万小文件产生的索引文件不超过100mb,在读取时可以轻易的全部加载到主流设备的内存中。
34、响应快,在查询和恢复目录或文件时只需少量几次io操作,而io操作的次数并不会随着目录或文件的数量线性增长。
35、扩展性强,可支持网络存储,压缩,重删,加密等扩展,对运行环境没有要求,使用方便,降低开发和维护难度。
36、4.支持并发的流式读写,不占用缓存空间,可极大的发挥出硬件性能。
- 还没有人留言评论。精彩留言会获得点赞!