一种基于强化学习的数据定价方法、装置、设备和介质
本发明涉及数据交易领域,特别涉及一种基于强化学习的数据定价方法、装置、计算设备和计算机存储介质。
背景技术:
1、随着大数据、机器学习、人工智能等技术的持续发展,这些技术已经逐步深入到社会经济生活的各个方面。许多企业都在此基础上推进数字化转型,而在这一过程中,这些企业都积累了大量数据,这些数据成为了它们宝贵的资产。但出于对数据隐私保护和企业资产保护的考虑,企业通常都不愿意直接出售源数据,但同时又希望能够利用其他企业的数据来改善自身采用的相关数据模型。因此,基于协同训练的场景成为了未来数据交易的一个重要方向。协同训练是指通过多个企业共同训练一个模型的方式,每个企业贡献出自己的数据,从而获得更好的模型效果。基于协同训练的这种数据交易方式不仅可以提高数据的使用效率,还可以通过联邦学习等手段保护企业的数据隐私和资产。基于此,协同训练将在数据交易中扮演越来越重要的角色。
2、在协同训练的交易场景中,由于来自于不同数据所有者的数据集对最后的机器学习模型有不同的贡献,因此需要一种算法来评估各个数据所有者的数据集对模型的贡献,以此为基础进一步进行收入分配。基于协同训练场景的数据交易定价就是为了解决收入分配问题。
3、目前,为了量化每个数据集的价值,一种的方式是将加入该数据集后训练得到的模型性能增益作为该数据集的价值,即loo方法(leave-one-out,留一法)。但此方法存在两个问题,首先如果存在两个相同的数据集,利用loo方法计算的数据集价值就为0;其次,由于数据量过少会使数据集对整体模型的性能增益忽略不计,会使此种情况下loo方法进行评估的数据价值结果基本均为0,因此,loo方法无法对单个数据样本或数据量较少的数据集进行价值评估。另一种方法是利用data-shapley算法,将数据样本或数据集视为联合博弈中的参与者,每个待评估的数据样本或数据集对应一个参与者,基于部分数据集合训练的到的模型性能对应这些参与者合作产生的奖励。但采用data-shapley算法会使得计算复杂度随着样本集合的增大而指数级地增长,在面对复杂样本时计算效率过低。
4、近一段时间,yoon等人提出了一个元学习框架dvrl(data valuation usingreinforcement learning,利用强化学习的数据价值评估),通过一个数据估值计算器(dve,data value estimator)选择“有价值”的数据进行训练,以数据点被选择的“概率”作为该数据点的“价值”。dvrl在针对多个数据集进行价值评估的场景下,效果比loo和基于联合博弈的shapley系列算法更优。然而,当前dvrl只解决了在数据拥有方各自拥有一部分样本和全部特征的场景下进行数据定价的问题,现实中还包括其他情况。例如,在担保行业企业授信场景下,多个数据拥有方全部样本的一部分特征;在营销场景下,每家公司则通常只拥有一部分样本和一部分特征。而当前dvrl无法有效针对这两种情形进行评估。
技术实现思路
1、为了解决上述技术问题,本发明提供了一种基于强化学习的数据定价方法和相应的基于强化学习的数据定价装置、计算设备和计算机存储介质。
2、根据本发明的一个方面,提供了一种基于强化学习的数据定价方法,所述方法包括:
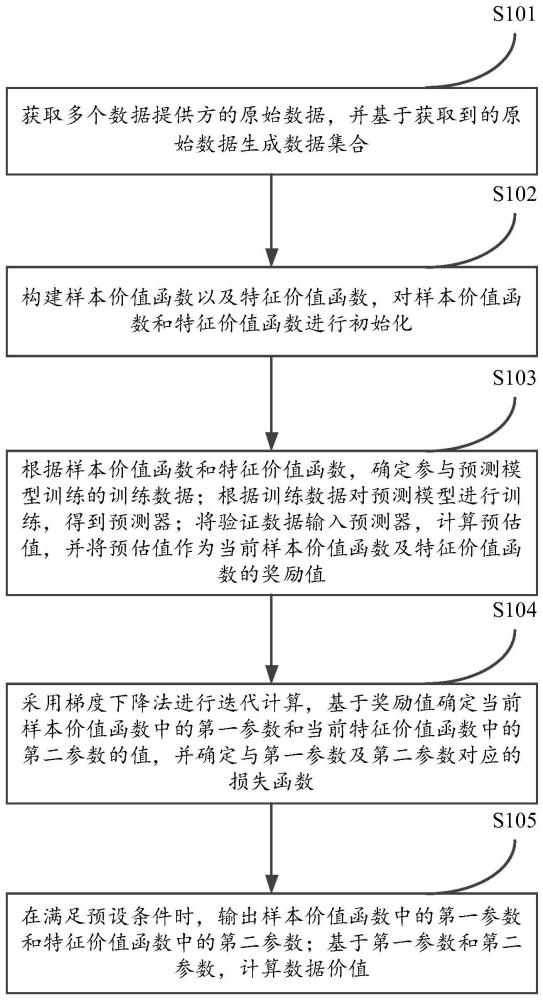
3、获取多个数据提供方的原始数据,并基于获取到的原始数据生成数据集合;
4、构建样本价值函数以及特征价值函数,对样本价值函数和特征价值函数进行初始化;
5、根据样本价值函数和特征价值函数,确定参与预测模型训练的训练数据;根据训练数据对预测模型进行训练,得到预测器;将验证数据输入预测器,计算预估值,并将预估值作为当前样本价值函数及特征价值函数的奖励值;
6、采用梯度下降法进行迭代计算,基于奖励值确定当前样本价值函数中的第一参数和当前特征价值函数中的第二参数的值,并确定与第一参数及第二参数对应的损失函数;
7、在满足预设条件时,输出样本价值函数中的第一参数和特征价值函数中的第二参数;基于第一参数和第二参数,计算数据价值。
8、上述方案中,所述获取多个数据提供方的原始数据,并基于获取到的原始数据生成数据集合,进一步包括:
9、获取多个数据提供方的原始数据;
10、将原始数据基于样本维度和特征维度进行划分;
11、基于划分结果和原始数据,生成矩阵形式的数据集合。
12、上述方案中,所述构建样本价值函数以及特征价值函数,对样本价值函数和特征价值函数进行初始化,进一步包括:
13、样本价值函数中包含第一参数,所述第一参数为一个n×1的向量,其中,n为数据集合中样本的个数,也是数据集合的行数;
14、特征价值函数中包含第二参数,所述第二参数为一个m×1的向量,其中,m为数据集合中特征的个数,也是数据集合的列数。
15、上述方案中,所述根据样本价值函数和特征价值函数,确定参与预测模型训练的训练数据;根据训练数据对预测模型进行训练,得到预测器,进一步包括:
16、根据样本价值函数,筛选出参与预测模型训练的训练样本;
17、根据特征价值函数,筛选出参与预测模型训练的训练特征;
18、基于训练样本和训练特征确定出参与预测模型训练的训练数据;根据训练数据对预测模型进行训练,得到预测器。
19、上述方案中,所述验证数据由场景使用方确定,或者,从数据集合中进行抽样得到验证数据。
20、上述方案中,所述采用梯度下降法进行迭代计算,基于奖励值确定当前样本价值函数中的第一参数和当前特征价值函数中的第二参数的值,并确定与第一参数及第二参数对应的损失函数,进一步包括:
21、基于梯度下降法,多次重复训练数据的确定过程和奖励值的计算,得到多个奖励值,确定每次迭代时的第一参数及第二参数对应的损失函数;其中,所述损失函数为:
22、j(w1,w2)=p1(t1(1)|w1)p2(t2(1)|w2)r(1)
23、+p1(t1(2)|w1)p2(t2(2)|w2)r(2)+…
24、+p1(t1(k)|w1)p2(t2(k)|w2)r(k)
25、其中,w1为第一参数;w2为第二参数;r(k)为第k次的奖励值;t1(k)为n×1的向量,取值为0或1,若取值为0,则表示本次采样未选取该样本,若取值为1,则表示本次采样选取了该样本;t2(k)为m×1的向量,取值为0或1,若取值为0,则表示本次采样未选取该特征,若取值为1,则表示本次采样选取了该特征;p1(t1(k)|w1)表示在当前参数为w1时,采样的向量为t1(k)的概率;p2(t2(k)|w2)表示在当前参数为w2时,采样的向量为t2(k)的概率;并且,
26、(w1,w2)=(w1,w2)+γ·grad(j(w1,w2))
27、其中,γ为学习率;grad(j(w1,w2))为梯度。
28、上述方案中,所述预设条件为迭代次数超过次数阈值,或者,第一参数和第二参数的更新幅度小于幅度阈值;
29、所述基于第一参数和第二参数,计算数据价值,进一步包括:
30、将第一参数代入样本价值函数,第二参数代入特征价值函数,得到样本价值函数的样本输出结果以及特征价值函数的特征输出结果;
31、将样本输出结果与特征输出结果相乘,得到数据价值。
32、根据本发明的另一方面,提供了一种基于强化学习的数据定价装置,包括:获取模块、初始化模块、训练预估模块、迭代模块以及价值计算模块;其中,
33、所述获取模块,用于获取多个数据提供方的原始数据,并基于获取到的原始数据生成数据集合;
34、所述初始化模块,用于构建样本价值函数以及特征价值函数,对样本价值函数和特征价值函数进行初始化;
35、所述训练预估模块,用于根据样本价值函数和特征价值函数,确定参与预测模型训练的训练数据;根据训练数据对预测模型进行训练,得到预测器;将验证数据输入预测器,计算预估值,并将预估值作为当前样本价值函数及特征价值函数的奖励值;
36、所述迭代模块,用于采用梯度下降法进行迭代计算,基于奖励值确定当前样本价值函数中的第一参数和当前特征价值函数中的第二参数的值,并确定与第一参数及第二参数对应的损失函数;
37、所述价值计算模块,用于在满足预设条件时,输出样本价值函数中的第一参数和特征价值函数中的第二参数;基于第一参数和第二参数,计算数据价值。
38、根据本发明的又一方面,提供了一种计算设备,包括:处理器、存储器、通信接口和通信总线,所述处理器、所述存储器和所述通信接口通过所述通信总线完成相互间的通信;
39、所述存储器用于存放至少一可执行指令,所述可执行指令使所述处理器执行如上述的基于强化学习的数据定价方法对应的操作。
40、根据本发明的再一方面,提供了一种计算机存储介质,所述存储介质中存储有至少一可执行指令,所述可执行指令使处理器执行如上述的基于强化学习的数据定价方法对应的操作。
41、根据本发明提供的技术方案,获取多个数据提供方的原始数据,并基于获取到的原始数据生成数据集合;构建样本价值函数以及特征价值函数,对样本价值函数和特征价值函数进行初始化;根据样本价值函数和特征价值函数,确定参与预测模型训练的训练数据;根据训练数据对预测模型进行训练,得到预测器;将验证数据输入预测器,计算预估值,并将预估值作为当前样本价值函数及特征价值函数的奖励值;采用梯度下降法进行迭代计算,基于奖励值确定当前样本价值函数中的第一参数和当前特征价值函数中的第二参数的值,并确定与第一参数及第二参数对应的损失函数;在满足预设条件时,输出样本价值函数中的第一参数和特征价值函数中的第二参数;基于第一参数和第二参数,计算数据价值。通过样本和特征两个维度来整理原始数据,依据样本价值函数和特征价值函数,基于数据点被选择的概率来表征数据点的价值,其计算复杂度不依赖于训练集的大小,十分简洁且准确,使本方法可以扩展到大型数据集以及复杂数据模型;之后,通过梯度下降法对两种价值函数中的参数值进行迭代计算,并得到最小化的损失函数,基于此确定出该参数,计算出对应的样本价值和特征价值,并最终得到更为合理的数据价值。
42、本发明的其它特征和优点将在随后的说明书中阐述,并且,部分地从说明书中变得显而易见,或者通过实施本发明而了解。本发明的目的和其他优点可通过在所写的说明书、权利要求书、以及附图中所特别指出的结构来实现和获得。
43、下面通过附图和实施例,对本发明的技术方案做进一步的详细描述。
- 还没有人留言评论。精彩留言会获得点赞!