一种分布式搜索计算引擎的制作方法
本发明属于数据处理,具体涉及一种分布式搜索计算引擎。
背景技术:
1、伴随着互联网技术的高速发展,互联网数据呈爆炸性的增长趋势,为了快速搜索定位信息,对搜索计算引擎的性能要求也越来越高。目前常用的搜索引擎在进行数据存储时没有考虑搜索集群物理节点数量以及索引数据量,导致索引性能低下和集群性能降低,而且无法满足用户可能的扩容要求。且现有的搜索引擎在索引设置时没有考虑集群中各节点的性能,会使得某些节点比较繁忙或比较空闲,会导致一定的负载均衡的问题,无法充分发挥集群性能,且无法根据用户的使用需求进行针对性的优化。
技术实现思路
1、鉴于上述的分析,本发明旨在公开一种分布式搜索计算引擎,解决了现有技术中的搜索计算引擎没有考虑集群节点的性能和索引数据量,导致索引性能和集群性能受限的问题。
2、本发明的目的主要是通过以下技术方案实现的:
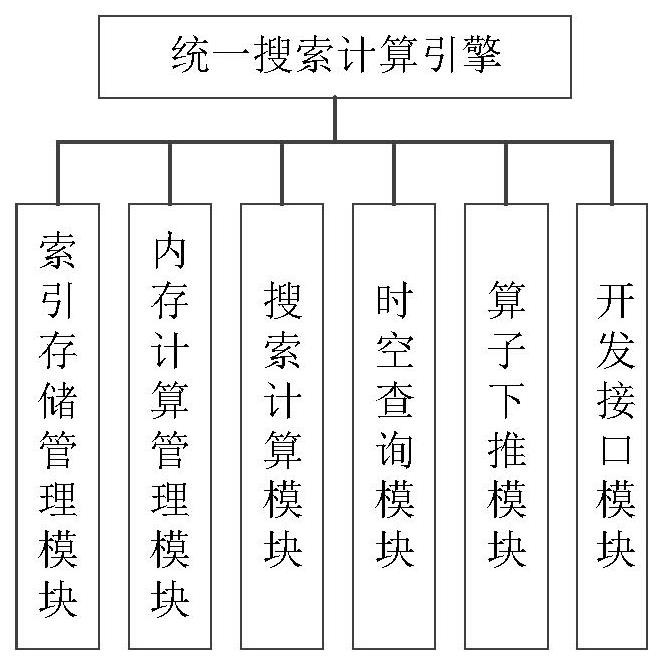
3、一方面,本发明公开了一种分布式搜索计算引擎,包括:索引存储管理模块和搜索计算模块,其中:
4、所述索引存储管理模块用于基于文档数据创建索引,将所述索引分为多个索引分片分散存储在多个物理分片上,所述物理分片上还存储有该索引分片对应的文档数据;所述物理分片的数量基于搜索集群各物理节点的性能和所述索引的数据量计算得到;
5、所述搜索计算模块用于基于客户端输入的搜索关键词,通过查询操作在各个索引分片中进行关键词匹配及匹配度计算,得到多个匹配文档的文档id;并通过取值操作,基于所述文档id和路由公式,从对应的物理分片中获取得到匹配文档。
6、进一步的,基于文档数据创建的所述索引为倒排索引,所述倒排索引包括单词词典和倒排列表;
7、所述单词词典包括所有文档数据中出现过的单词以及指向所述倒排列表中对应单词的指针;
8、所述倒排列表包括所述单词词典中每个单词出现过的所有文档的文档id、在文档中出现的位置信息和出现频率。
9、进一步的,所述查询操作包括:通过轮询的方式选择一个物理分片作为协调节点,并发送搜索请求;所述协调节点广播所述搜索请求到每一个物理分片;各个所述索引分片基于对应的倒排索引数据进行关键词匹配并进行匹配度计算,得到匹配结果并发送至协调节点,所述匹配结果包括每个匹配文档的文档id和匹配度;所述协调节点对接收到的所有匹配结果进行全局排序,得到所有匹配文档的总的排序结果;
10、所述取值操作包括:基于所述排序结果和预设的搜索结果数量,通过所述协调节点确定需要返回的文档id,并向含有该文档数据的索引分片发送get请求,对应的所述索引分片基于路由公式,从物理分片中获取得到对应的文档数据返回给协调节点,并通过所述协调节点将搜索得到的文档数据返回给客户端。
11、进一步的,通过下述方法得到所述物理分片的数量:
12、根据所述索引的数据量计算得到初步物理分片数量sn1;其中,d为索引的数据量,通过对集群中的索引进行数据统计得到。
13、对所述集群中各物理节点进行性能校验,得到通过校验的物理节点数量sn2;
14、对sn1和sn2进行加权求和,得到符合索引数据量和节点性能的分片数量shardnum。
15、进一步的,所述对所述搜索集群中各物理节点进行性能校验,得到通过校验的物理节点数量sn2,包括:
16、校验各物理节点的磁盘使用率和各物理节点已有的物理分片的数量,若所述物理节点的磁盘使用率dsrii不超过90%,且所述物理节点已有的物理分片数量不超过预设阈值,则判定所述物理节点通过校验;
17、若所述物理节点通过校验,将对应的校验结果nodearri元素置为1,否则置为0,并将校验结果保存于数组nodearr[];
18、通过下式得到通过校验的物理节点数量sn2,
19、进一步的,通过下述公式得到符合索引数据量和节点性能的分片数量shardnum:
20、shardnum=[(e*sn1+k*sn2)*(1+θ)]+t;
21、其中,θ为扩展系数,e、k为权重系数,t为冗余分片数量,1≤t≤4。
22、进一步的,若得到物理分片数量shardnum大于当前可用的物理节点数量,则通过下述公式调整在同一个物理节点上的物理分片的数量上限x:
23、
24、若shardnum不超过当前可用的物理节点数量,则以当前可用的物理节点数量设置物理分片数量,即每个所述物理节点设置一个物理分片。
25、进一步的,所述预设的索引分片放置策略,包括:
26、所述预设的索引分片放置策略,包括:
27、采用线性加权法,通过下述公式对搜索集群中个物理节点进行性能评估:
28、qi=a×lai+s×sni+b×dsri;
29、其中,qi值代表i物理节点的性能值;lai表示物理节点i的平均负载;sni表示物理节点i的已有分片数量;dsri表示物理节点i的磁盘使用率;a、s和b为权重系数;
30、基于索引分片数量shardnum,按各物理节点的性能值由高到低的顺序,对索引分片进行分片放置。
31、进一步的,所述索引分片包括主分片和副本分片;所述主分片用于为文档数据建立倒排索引并进行数据存储,并向副本分片进行数据写入;所述副本分片用于备份所述主分片发送的数据;所述主分片和对应的副本分片分别设置在所述搜索集群中不同的物理节点上。
32、进一步的,所述搜索计算引擎通过下述步骤写入数据:
33、java客户端根据配置的搜索集群信息得到物理节点列表,并将用户输入的数据和索引信息封装为tcp请求,通过轮询的方式选择一个物理分片作为协调节点,并向所述协同节点发送写请求;
34、所述协调节点根据所述索引信息加载对应的索引元数据,所述索引元数据包括索引的mapping结构信息;
35、所述协调节点检查传入的数据是否指定了doc id,若没有指定,则为该数据生成doc id;并检查是否指定了路由值,如果没有指定,则使用doc id作为该文档数据的路由值,并通过路由公式计算出对应的物理分片的序号值;
36、协调节点获取该索引对应的主分片信息及对应的主分片节点的ip地址信息,并向该ip对应的物理节点发送远程请求;
37、所述物理节点得到数据后,首先进行内容路由写一致性检查,若检查通过,则进行写分片操作;
38、写入完成后,循环发送写请求到副本分片,所述副本分片写入成功后,通过所述协调节点向客户端返回写入成功信息。
39、本发明至少可实现以下有益效果之一:
40、1.本发明的搜索计算引擎在创建索引时,基于搜索集群各物理节点的性能和所述索引的数据量计算得到物理分片的数量,对索引数据进行分片放置,能够根据用户的需求和硬件资源进行优化设置,提高了硬件资源的利用率和搜索计算引擎的性能。
41、2.本发明在进行索引分片前,首先校验各物理节点的磁盘使用率和各物理节点已有的物理分片的数量,若物理节点的磁盘使用率dsrii不超过90%,且物理节点已有的物理分片数量不超过预设阈值,则判定物理节点通过校验,可以用于索引分片数计算,有效避免了分片不合理导致某些节点比较繁忙或比较空闲,引起负载均衡的问题。
- 还没有人留言评论。精彩留言会获得点赞!