一种基于HTML文档利用图数据库实现快速检索的方法与流程
本发明属于数据检索和信息抽取方法,尤其涉及一种基于html文档利用图数据库实现快速检索的方法。
背景技术:
1、随着信息技术的发展,各行各业都有从海量数据中精确抽取所需数据及重要信息的需求。近年来,随着信息、数据、文本的存储格式越来越丰富多样,也催生出了各类信息抽取技术,其中,基于长文本的信息抽取,一直以来都是信息抽取中的重难点,原因有以下两点:其一是因为文本数据量大,非结构化数据占数据总量的80%以上,而其中文本数据又占前者的一半以上;其二是因为不同于结构化数据,基于长文本的信息抽取更难准确定位到待抽取内容。
2、目前,大部分基于长文本的信息抽取,都是依靠自然语言处理算法,根据上下文的语境和语义,实体、关系等目标词汇,抽取出与问题、描述相似的内容。但是,该方法必须对语言模型进行微调训练,需要大量的算力以及算法工程师和标注工程师的参与,不仅要耗费大量的人力和时间,而且准确率也不易得到保证。
技术实现思路
1、为了克服现有基于长文本的信息抽取方法耗时耗力、准确率低的缺陷,本发明提出了一种新的基于html文档利用图数据库实现快速检索的方法。
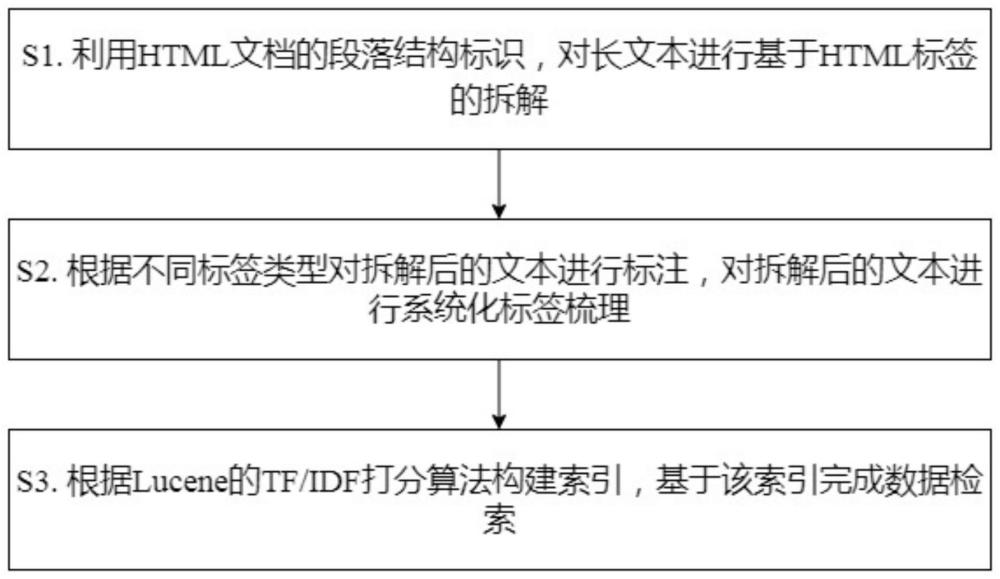
2、具体地,本发明提供了一种基于html文档利用图数据库实现快速检索的方法,本方法包括:
3、s1.利用html文档的段落结构标识,对长文本进行基于html标签的拆解;
4、s2.根据不同标签类型对拆解后的文本进行标注,对拆解后的文本进行系统化标签梳理;
5、s3.根据lucene的tf/idf打分算法构建索引,基于该索引完成数据检索。
6、进一步地,本发明基于html文档利用图数据库实现快速检索的方法步骤s1中还包括:利用markdown文档的段落结构标识,对长文本进行基于markdown标签的拆解。
7、进一步地,本发明基于html文档利用图数据库实现快速检索的方法步骤s1中所述的对长文本进行基于html标签的拆解,拆解后的文本需满足以下三点要求:
8、(1)内容不可重复;
9、(2)文本单元字数符合预设的单元字数范围;
10、(3)文本单元内容具有完整性。
11、进一步地,上述基于html文档利用图数据库实现快速检索的方法(3)中所述的文本单元内容具有完整性是指以句号作为拆解切分的节点。
12、进一步地,本发明基于html文档利用图数据库实现快速检索的方法步骤s3中所述的lucene的tf/idf打分算法,其包含的打分因子包括文档权重、域权重、调整因子、逆文档频率、长度归一化、词频和归一化因子。
13、进一步地,本发明基于html文档利用图数据库实现快速检索的方法步骤s3中所述的根据lucene的tf/idf打分算法构建索引,基于该索引完成数据检索,包括:对需要进行检索的短语进行分词,得出分词项后,将每个分词项和每个索引中的文档根据tf/idf进行词频出现的评分计算,然后将每个分词项的得分相加,即得到当前检索对应的文档得分。
14、另外,本发明还提供了一种计算机可读存储介质,所述存储介质上存储有计算机程序,所述程序被处理器执行时实现上述的基于html文档利用图数据库实现快速检索的方法的步骤。
15、另一方面,本发明还提供了一种基于html文档利用图数据库实现快速检索的系统,本系统包括:
16、文本拆解模块:利用html文档的段落结构标识,对长文本进行基于html标签的拆解;
17、标签梳理模块:根据不同标签类型对拆解后的文本进行标注,对拆解后的文本进行系统化标签梳理;
18、索引构建模块:根据lucene的tf/idf打分算法构建索引;
19、数据检索模块:基于索引完成数据检索;
20、上述各模块按照前述的基于html文档利用图数据库实现快速检索的方法实施运行。
21、综上,本发明基于html文档利用图数据库实现快速检索的方法具有以下优点:
22、(1)通过本方法完成搜索数据库构建后,可支持不同颗粒度的内容查询及信息抽取工作,使用者可根据实际应用需求选择相应颗粒度的标签范围进行检索,增强了检索的目的性和针对性,减少了无效的检索工作,显著提高了数据查询和信息抽取的速度和效率,同时提升了检索的准确性,根据本发明方法的实践结果,百万级别节点量级的知识库,单位内容段落长度在300字以内的,全图查询时间不超过1秒。
23、(2)本方法无需算法工程师对语言模型进行微调训练,节省了大量的人力和时间,同时避免了人为介入引入的不可控性,一定程度上提高了信息抽取的准确率。
技术特征:
1.一种基于html文档利用图数据库实现快速检索的方法,其特征在于,所述方法包括:
2.根据权利要求1所述的基于html文档利用图数据库实现快速检索的方法,其特征在于,步骤s1中还包括:利用markdown文档的段落结构标识,对长文本进行基于markdown标签的拆解。
3.根据权利要求1所述的基于html文档利用图数据库实现快速检索的方法,其特征在于,步骤s1中所述的对长文本进行基于html标签的拆解,拆解后的文本需满足以下三点要求:
4.根据权利要求3所述的基于html文档利用图数据库实现快速检索的方法,其特征在于,(3)中所述的文本单元内容具有完整性是指以句号作为拆解切分的节点。
5.根据权利要求1所述的基于html文档利用图数据库实现快速检索的方法,其特征在于,步骤s3中所述的lucene的tf/idf打分算法,其包含的打分因子包括文档权重、域权重、调整因子、逆文档频率、长度归一化、词频和归一化因子。
6.根据权利要求1所述的基于html文档利用图数据库实现快速检索的方法,其特征在于,步骤s3中所述的根据lucene的tf/idf打分算法构建索引,基于该索引完成数据检索,包括:对需要进行检索的短语进行分词,得出分词项后,将每个分词项和每个索引中的文档根据tf/idf进行词频出现的评分计算,然后将每个分词项的得分相加,即得到当前检索对应的文档得分。
7.一种计算机可读存储介质,所述存储介质上存储有计算机程序,所述程序被处理器执行时实现权利要求1-6任一项所述的基于html文档利用图数据库实现快速检索的方法的步骤。
8.一种基于html文档利用图数据库实现快速检索的系统,其特征在于,所述系统包括:
技术总结
本发明涉及一种基于HTML文档利用图数据库实现快速检索的方法。本方法包括:利用HTML文档的段落结构标识,对长文本进行基于HTML标签的拆解;根据不同标签类型对拆解后的文本进行标注,对拆解后的文本进行系统化标签梳理;根据Lucene的TF/IDF打分算法构建索引,基于该索引完成数据检索。本方法支持不同颗粒度的内容查询及信息抽取工作,使用者可根据实际应用需求选择相应颗粒度的标签范围进行检索,提升了检索的准确性,减少了无效的检索工作,显著提高了数据查询和信息抽取的速度和效率。本方法无需算法工程师对语言模型进行微调训练,节省了人力和时间,同时避免了人为介入引入的不可控性,提高了信息抽取的准确率。
技术研发人员:陆志鹏,韩光,郑曦,王晓亮,国丽,刘国栋,范国浩,唐超,王欢,张婧莹
受保护的技术使用者:中电数据产业有限公司
技术研发日:
技术公布日:2024/3/31
- 还没有人留言评论。精彩留言会获得点赞!