一种基于目标检测和级联匹配的人流量统计方法与流程
本发明涉及行人检测与跟踪,具体为一种基于目标检测和级联匹配的人流量统计方法。
背景技术:
1、人员密集且人员流动大的公共场所常常面临着安全隐患。以地铁车站为例,在高峰时段或紧急情况下,车站内人满为患,可能导致乘客的情绪紧张和焦虑。这种情况下,人群聚集在狭小有限的空间中,容易引发拥挤、踩踏等混乱现象,对人们的安全出行带来了极大影响。因此,采用人流管理和安全预警系统对于减轻拥挤和应对突发事件至关重要。
2、地铁车站的安全管理需要综合考虑各种潜在风险,采用现代技术和监控系统,可以提高乘客出行的安全系数。这不仅关乎地铁系统的正常运营和城市的交通安全,还关系到乘客的生命安全。因此,安全管理是地铁运营的重要组成部分,需要不断改进和完善。随着计算机视觉技术的不断进步,目标检测和跟踪方法在工业生产领域得到了广泛的应用。在过去,人流量统计主要采用背景差、帧差、光流法和方向梯度直方图等传统技术来检测行人流量,然后利用颜色、形状等特征进行行人的重新识别。然而,随着深度学习技术的崛起,目标检测和跟踪方法逐渐转向了基于深度神经网络的检测算法。这种变革使得目标检测和跟踪方法更加准确且具有更高的稳健性。
3、深度神经网络能够提取更为丰富和高级的特征表示,从而实现更精确的目标检测和跟踪。它能够学习到大数据中的复杂模式和特征,有效区分目标和背景,从而可显著提高检测的准确性。目前,常用于图像和视频的目标检测和跟踪方法包括r-cnn、fast r-cnn、yolo、fairmot、transtrack、bytetrack等。然而,为了进一步提高行人检测和跟踪的精度,并解决目标检测算法可能导致的行人漏检问题,以及关联匹配策略中存在的缺陷,如当前行人与历史行人轨迹错误匹配的问题,有必要提出一种基于目标检测和级联匹配的人流量统计方法,将有效改进人流量统计的准确性和可靠性,对于地铁车站等人流密集场所的安保具有重要意义。
技术实现思路
1、针对现有技术中人流密集场所行人检测和跟踪的误差大、并存在行人遮挡等,目标检测算法可能导致的行人漏检问题以及关联匹配策略中存在的当前行人与历史行人轨迹错误匹配等不足,本发明要解决的技术问题是提供一种基于目标检测和级联匹配的人流量统计方法,以应对采用传统方法统计人流量时所存在的一系列由于人流量过大,行人遮挡带来的人流量统计误差问题。
2、为解决上述技术问题,本发明采用的技术方案是:
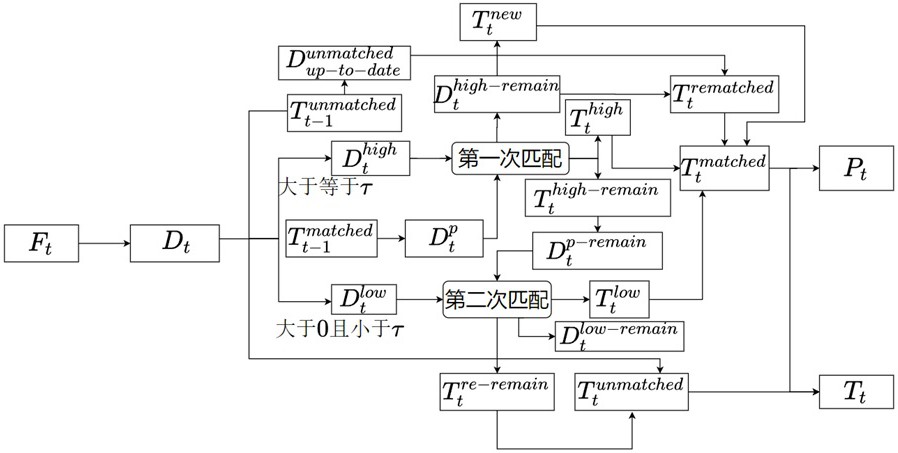
3、s1、从监控视频流中提取连续图像帧 f t;
4、s2、对图像帧 f t进行图像预处理操作后,送入目标检测器中,得到边界框预测和类别预测;
5、s3、根据边界框预测和类别预测,结合阈值筛选和非极大值抑制技术,去除重复的行人检测结果和非行人类别结果,并输出有效的行人检测结果,包括检测行人边界框集合 d t和对应的置信度集合 s t;
6、s4、级联匹配准备过程,以设定的边界框置信度阈值为标准,以置信度为划分依据,将步骤s3得到的检测行人边界框集合 d t划分为高分检测行人边界框集合和低分检测行人边界框集合;
7、s5、以前一帧的活跃轨迹集合作为输入,利用运动状态估计器得到预测行人边界框集合;
8、s6、进行第一次级联匹配,将步骤s5得到的预测行人边界框集合与高分检测行人边界框集合进行运动预测相似度和视觉特征向量相似度计算,并利用运动状态估计器得到高分匹配轨迹集合、剩余高分检测行人边界框集合以及剩余活跃轨迹集合;
9、s7、将剩余高分检测行人边界框集合与 f t-1帧的未激活轨迹集合最近时刻匹配行人边界框集合中的元素逐个进行视觉特征向量相似度计算,满足视觉特征向量相似度要求进行轨迹重匹配的轨迹离开 f t-1 帧的未激活轨迹集合,并进入重激活轨迹集合,否则对剩余高分检测行人边界框集合中的行人边界框进行初始化生成新轨迹集合;
10、s8、进行第二次级联匹配,将低分检测行人边界框集合与剩余活跃轨迹集合通过运动状态估计器得到的剩余预测行人边界框集合,利用组合优化算法得到低分匹配轨迹集合、剩余低分检测行人边界框集合以及二次剩余活跃轨迹集合;
11、s9、将剩余低分检测行人边界框集合视为背景,从检测行人边界框集合 d t中删除;
12、s10、将二次剩余活跃轨迹集合与 f t-1帧的未激活轨迹集合进行合并成为 f t帧的未激活轨迹集合; f t帧的未激活轨迹集合中每个轨迹的未匹配计数加1,若未匹配计数超过未匹配计数阈值n,则从 f t帧的未激活轨迹集合中将对应轨迹删除;高分匹配轨迹集合、低分匹配轨迹集合、重激活轨迹集合和新轨迹集合中每个轨迹的未匹配计数置为0,合并高分匹配轨迹集合、低分匹配轨迹集合、重激活轨迹集合、新轨迹集合得到图像帧 f t的活跃轨迹集合;合并图像帧 f t的活跃轨迹集合、 f t帧的未激活轨迹集合得到图像帧 f t的全部轨迹集合 t t;对图像帧 f t的活跃轨迹集合中包含的轨迹数量进行统计,得到t时刻的人流量信息 p t; t代表当前时刻;
13、s11、初始化目标检测器、运动状态估计器以及组合优化算法,重复步骤s2至步骤s11,得到每个图像帧 f t 的轨迹集合 t t 和人流量信息 p t。
14、所述监控视频流为实时获取的被监控区域的视频监控数据;所述目标检测器负责处理采集到的视频监控数据,输出相应的目标检测结果;所述级联匹配是通过跟踪目标检测结果,并根据行人出现顺序和行人轨迹的编号分配行人id,对人流量信息进行统计。
15、目标检测器通过非极大值抑制和阈值筛选去除干扰目标,得到检测行人边界框集合 d t与置信度集合 s t;目标检测器得到行人边界框坐标信息det=(x ,y ,w ,h),x为检测行人边界框左上角的横坐标,y为检测行人边界框左上角的纵坐标,w为检测行人边界框的宽度,h为检测行人边界框的高度。
16、步骤s4中,以行人的边界框置信度阈值作为分类标准,将置信度大于等于的检测行人边界框划分为高分检测行人边界框,将置信度大于等于最小置信度并小于边界框置信度阈值的检测行人边界框划分为低分检测行人边界框,置信度小于的检测行人边界框通过阈值筛选操作去除。
17、步骤s5中,以前一帧的活跃轨迹集合作为输入,利用卡尔曼滤波器得到预测行人边界框集合,其中需要预测的状态是:
18、 x k =[ x c( k), y c( k) , w( k) , h( k), d[ x c( k)], d[ y c( k)] , d[ w( k)] , d[ h( k)] ]t (1)
19、其中, x k为第 k个预测行人边界框的运动状态, x c( k)为第 k个预测行人边界框左上角的横坐标, y c( k)为第 k个预测行人边界框左上角的纵坐标, w( k)为第 k个预测行人边界框宽, h( k)为第 k个预测行人边界框的高, d[ x c( k)]为 x c( k)的微分, d[ y c( k)]为 y c( k)的微分, d[ w( k)]为 w( k)的微分, d[ h( k)]为 h( k)的微分, k代表当前预测行人边界框在集合内的序号; c为二维平面的预测基准点。
20、步骤s6中预测行人边界框集合与高分检测行人边界框集合进行运动预测相似度计算,具体为:
21、计算自适应扩展交并比,若行人运动的速度超过画面内所有行人平均运动速度,则将其视为快速移动的行人,对其使用扩展交并比系数进行相似度计算;否则扩展交并比系数设置为0,通过自适应扩展交并比,得到运动预测相似度。
22、步骤s6中,视觉特征向量相似度计算是分别对当前检测到的高分检测行人边界框集合和预测行人边界框集合分别生成高分行人边界框视觉特征向量 y high和预测行人边界框视觉特征向量 y p;
23、应用图像切片技术和特征提取注意机制的提取方法对输入行人边界框图像切片;
24、应用骨干网络resnet-18来提取行人边界框的视觉特征,将行人边界框的视觉特征图分成数量为s×e的切片 s i∈ r n×s×e,其中n为特征图的通道数量,s为横向切片数量,e为纵向切片数量, s i为第i个切片, r n×s×e为切片所在的坐标空间;
25、向每个切片添加一个一维位置嵌入 e p,假设目前s、e均为2,每个切片表示为:
26、 s i= s i+ e p (2)
27、其中, i=a,b,c,d; e p =1,2,3,4;a为行人边界框的左上部分, b为行人边界框的右上部分, c为行人边界框的左下部分, d为行人边界框的右下部分; e p代表 a~d位置对应关系;
28、应用特征切片序列 s={ s a ~s d}作为注意力模块的输入,利用深度神经网络中的注意力机制通过将查询内容输入到矩阵q中来计算注意力函数,同时将匹配条件和匹配的内容分别输入到矩阵k和矩阵v中,q-k-v注意力模块的计算表示为:
29、 (3)
30、 q、 k、 v分别代表query矩阵、key矩阵和value矩阵;
31、其中 d k是关键向量的维度,每个切片在通过 q-k-v 注意力模块后都有一个输出 s i;将通过 q-k-v 注意力模块的每个特征切片序列 s={ s a ~s d}的输出表示为以下等式:
32、 s a =sa( q s1 ,k s1 ,v s1) +ca( q s1 ,k s2 ,v s2) +ca( q s1 ,k s3 ,v s3) +ca( q s1 ,k s4 ,v s4)
33、 s b =sa( q s2 ,k s2 ,v s2) +ca( q s2 ,k s1 ,v s1) +ca( q s2 ,k s3 ,v s3) +ca( q s2 ,k s4 ,v s4)
34、 s c =sa( q s3 ,k s3 ,v s3) +ca( q s3 ,k s1, v s1) +ca( q s3 ,k s2 ,v s2) +ca( q s3 ,k s4 ,v s4)
35、 s d =sa( q s4 ,k s4 ,v s4)+ ca( q s4 ,k s1 ,v s1) +ca( q s4 ,k s2 ,v s2) +ca( q s4 ,k s3 ,v s3) (4)
36、其中 q si是 s i得到的query矩阵, k si是 s i得到的key矩阵, v si是 s i得到的value矩阵, sa代表自注意力机制, ca代表交叉注意力机制;
37、在得到特征切片序列 s={ s a ~s d}后,使用连接机制将 s a ~s d拼接,以保留输入图像的特征;
38、在得到当前检测到的高分行人边界框视觉特征向量 y high和预测行人边界框视觉特征向量 y p后,通过全连接层对 y high和 y p进行特征修正得到修正视觉特征向量,并通过余弦相似度对 y high和 y p的修正视觉特征向量进行相似度计算,最后通过归一化操作获得便于计算的视觉特征向量相似度 m v;将运动预测相似度 m k和视觉特征向量相似度 m v通过以下公式得到代价矩阵:
39、 c high =m k( m,l) -( 1-m v( m,l)) (5)
40、其中 m k( m, l)是第 m个轨迹和第 l个检测行人边界框之间的运动预测相似度,由运动状态估计器生成, m v( m, l)是第 m个轨迹和第 l个检测行人边界框之间的视觉特征向量相似度,由视觉特征向量相似度计算方法生成;最后在级联匹配的第一次匹配中使用代价矩阵 c high通过匈牙利算法完成匹配。
41、步骤s7中,对剩余高分检测行人边界框集合中的轨迹计算视觉特征向量,并依次与 f t-1帧的未激活轨迹集合所对应的视觉特征向量计算视觉特征向量相似度 m v,如果出现视觉特征向量相似度 m v大于等于及格线的视觉特征向量,则将剩余高分检测行人边界框集合与 f t-1帧的未激活轨迹集合进行匹配,并将匹配后的轨迹放置于重激活轨迹集合中,并且将未匹配数置0;若出现两个及两个以上视觉特征向量相似度 m v大于等于及格线,则以视觉特征向量相似度最高匹配轨迹为准,并对行人离开和进入监控视野的行为进行记录;若视觉特征向量相似度 m v均小于及格线,则将剩余高分检测行人边界框集合中的检测行人边界框初始化为新轨迹集合中轨迹的第一帧图像。
42、步骤s10中,将步骤s8中二次剩余活跃轨迹集合与 f t-1帧的未激活轨迹集合进行合并得到 f t帧的未激活轨迹集合,若 f t帧的未激活轨迹集合中任一轨迹的未匹配数达到未匹配计数阈值n,则视该轨迹所属的行人从监控视野中消失,在 t时刻从 f t帧的未激活轨迹集合中删除轨迹。
43、与现有技术相比,本发明具有以下有益技术效果及优点:
44、1.本发明基于目标检测和级联匹配的人流量统计方法,使用一种多模态的特征融合机制,基于卡尔曼滤波器的运动预测算法和基于注意力机制的视觉特征向量提取方法,能提高有效信息来源广度和深度,对常规的运动预测进行必要的信息补充,缓解由于视觉特征缺少造成的行人id切换问题;
45、2. 本发明方法使用自适应扩展交并比,能有效提高卡尔曼滤波器的稳健性,针对快速运动的行人能够有效的进行运动预测。
46、3. 本发明方法使用级联匹配算法,对不同置信度的行人边界框分类进行操作,提高当前行人与历史行人轨迹匹配的精准度;
47、4.本发明方法对一定时间内出现过的行人的视觉特征向量和轨迹进行记录保存,当某行人在一定时间内重复出现时,可对其历史轨迹进行匹配,减少同一行人的重复轨迹,有效提高人流量统计的准确性。
- 还没有人留言评论。精彩留言会获得点赞!