基于主动感知机制的行为识别方法、装置、设备及介质
本发明涉及行为识别,尤其涉及一种基于主动感知机制的行为识别方法、装置、设备及介质。
背景技术:
1、在视频行为识别领域,如何有效关注视频帧中的重要区域并充分利用时空信息是一个重要的研究课题,近年来,基于深度学习的方法在行为识别方面取得了重大进展,其中,基于3d cnn的方法提出在空间和时间上联合操作卷积,进一步提高了性能。例如,通过将2dcnn的卷积和池化核与额外的时间维度相结合的i3d(inflated 3d),以及分别以高帧率和低帧率对rgb帧进行操作,以捕捉语义和运动信息的slow fast网络框架。然而,现有的基于3d cnn的方法,由于其只在有限的时间间隔内进行时空处理,卷积运算只关注视频中相对短期的上下文,很难对长期的时空依赖性进行建模,而基于slow fast网络框架的方法难以有效关注视频中的关键区域,因此,在行为识别中的应用仍然面临挑战。
2、为了提高对关键区域的关注度,将注意力机制融合到行为识别算法中,可以从视频中成功捕获有效特征,以及基于注意力机制来学习视频中的长期时空关系。但是,目前基于注意力机制的行为识别方法,不具备分析多个时间序列的能力,关注视频中与人体运动相关的关键区域的能力也有待提高,限制了行为识别的性能。
技术实现思路
1、本发明提供一种基于主动感知机制的行为识别方法、装置、设备及介质,用以解决现有的基于注意力机制的行为识别方法不具备分析多个时间序列的能力,且关注人体运动相关的关键区域的能力也有待提高,限制了行为识别性能的缺陷。
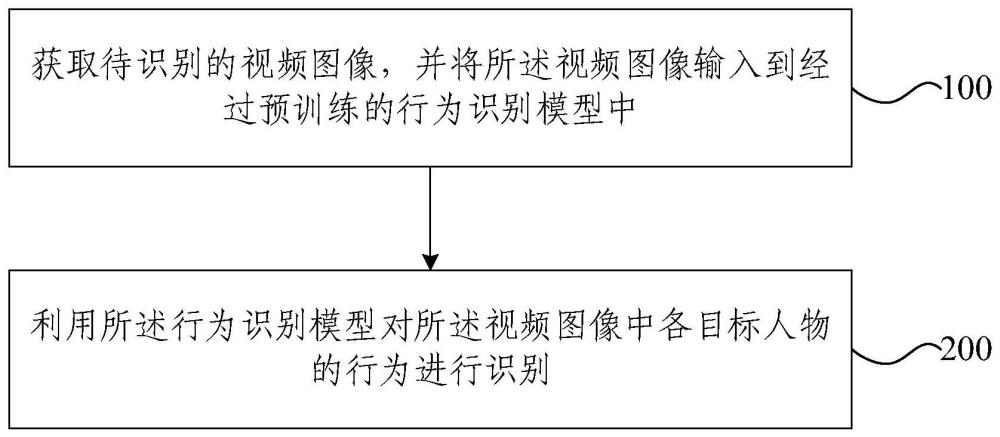
2、本发明提供一种基于主动感知机制的行为识别方法,包括:
3、获取待识别的视频图像,并将所述视频图像输入到经过预训练的行为识别模型中;
4、利用所述行为识别模型对所述视频图像中各目标人物的行为进行识别;
5、其中,所述行为识别模型包括主动感知机制网络和特征融合层,所述主动感知机制网络包括审视分支和浏览分支,所述审视分支用于提取所述视频图像的空间语义信息,所述浏览分支用于提取所述视频图像的运动信息;所述特征融合层用于对所述空间语义信息和所述运动信息进行融合,得到融合特征用于行为识别。
6、根据本发明提供的基于主动感知机制的行为识别方法,所述主动感知机制网络包括数据层、立方体层和时空多尺度结构,所述时空多尺度结构包括多个时空尺度不同的多头池化注意力层;所述数据层包括所述审视分支下的第一子数据层和所述浏览分支下的第二子数据层;所述立方体层包括所述审视分支下的第一子立方体层和所述浏览分支下的第二子立方体层;各所述多头池化注意力层包括所述审视分支下的第一子注意力层和所述浏览分支下的第二子注意力层;
7、所述利用所述行为识别模型对所述视频图像中各目标人物的行为进行识别,包括:
8、利用所述行为识别模型中的数据层对所述视频图像进行下采样,得到所述视频图像的视频帧序列;所述视频帧序列包括所述审视分支下的第一帧序列和所述浏览分支下的第二帧序列;
9、利用所述行为识别模型中的立方体层对所述视频帧序列进行时空立方体投影,以降低所述视频帧序列的时空分辨率,得到目标帧序列;所述目标帧序列包括所述审视分支下的第一目标帧序列和所述浏览分支下的第二目标帧序列;
10、基于所述行为识别模型中的时空多尺度结构,对所述目标帧序列进行基于空间自注意力机制和多层感知机制的空间多尺度特征提取,得到所述目标帧序列的特征信息;所述特征信息包括所述审视分支下的空间语义信息和所述浏览分支下的运动信息;
11、利用所述行为识别模型中的特征融合层对所述空间语义信息和所述运动信息进行融合得到融合特征,并基于所述融合特征对所述视频图像中各目标人物的行为进行识别。
12、根据本发明提供的基于主动感知机制的行为识别方法,所述利用所述行为识别模型中的特征融合层对所述空间语义信息和所述运动信息进行融合得到融合特征,包括:
13、获取所述行为识别模型的第一感知参数β;所述第一感知参数β根据任一所述多头池化注意力层的通道数的第一数量与第二数量的比值确定,所述第一数量为所述多头池化注意力层中的第一子注意力层中的通道数的数量,所述第二数量为所述多头池化注意力层中的第二子注意力层的通道数的数量;
14、利用所述行为识别模块中的特征融合层,基于所述第一感知参数β对所述空间语义信息和所述运动信息进行融合,得到融合特征。
15、根据本发明提供的基于主动感知机制的行为识别方法,所述利用所述行为识别模型中的数据层对所述视频图像进行下采样,得到所述视频图像的视频帧序列,包括:
16、获取所述视频图像的帧序列长度,根据所述帧序列长度确定所述行为识别模型的第二感知参数α;
17、根据所述第二感知参数α确定下采样率,并利用所述行为识别模型中的数据层根据所述下采样率对所述视频图像进行下采样,得到所述视频图像的视频帧序列。
18、根据本发明提供的基于主动感知机制的行为识别方法,所述将所述视频图像输入到经过预训练的行为识别模型中之前,还包括:
19、获取样本视频图像构建初始训练样本;所述初始训练样本包含所述样本视频图像中各样本人物的行为标签;
20、对所述初始训练样本进行增广处理,得到目标训练样本;
21、利用所述目标训练样本对预设的基础行为识别模型进行迭代训练,得到经过预训练的行为识别模型。
22、根据本发明提供的基于主动感知机制的行为识别方法,所述对所述初始训练样本进行增广处理,得到目标训练样本,包括:
23、对所述初始训练样本进行视频帧采样,得到样本帧序列对所述初始训练样本进行增广处理,得到第一训练样本;
24、基于空间变换算法,对所述第一训练样本中的视频帧序列进行空间变换,以对所述第一训练样本进行序列增广处理,得到第二训练样本;所述空间变换算法是从预设的多个空间变换算法中随机选取的,所述空间算法的参数值是随机选择的;所述空间变换算法包括翻转变换、色彩抖动、平移变换、对比度变换、噪声扰动、旋转变换和反射变换中的至少一种;
25、从所述第二训练样本中选取多个视频帧序列作为目标样本帧序列;
26、基于预设的融合系数,对所述目标样本帧序列进行融合,生成融合视频帧序列,并对各所述目标样本帧序列的行为标签进行标签融合,生成所述融合视频帧序列的标签数据;
27、利用所述融合视频帧序列对所述第二训练样本进行增广处理,得到目标训练样本。
28、根据本发明提供的基于主动感知机制的行为识别方法,所述对所述初始训练样本进行视频帧采样,得到样本帧序列对所述初始训练样本进行增广处理,得到第一训练样本,包括:
29、基于所述初始训练样本中的任一目标视频帧序列,随机选取所述目标视频帧序列中的一帧作为起始帧;
30、基于所述起始帧从所述目标视频帧序列中选取nf个连续的视频帧生成样本帧序列;和/或,
31、将所述目标视频帧序列平均划分为k个视频片段,并从各所述视频片段中分别随机选取nf/k个视频帧;
32、将选取的nf个视频帧按照时间顺序进行叠加,生成样本帧序列;
33、基于所述样本帧序列对所述初始训练样本进行增广处理,得到第一训练样本。
34、本发明还提供一种基于主动感知机制的行为识别装置,包括:
35、数据采集模块,用于获取待识别的视频图像,并将所述视频图像输入到经过预训练的行为识别模型中;
36、行为识别模块,用于利用所述行为识别模型对所述视频图像中各目标人物的行为进行识别;
37、其中,所述行为识别模型包括主动感知机制网络和特征融合层,所述主动感知机制网络包括审视分支和浏览分支,所述审视分支用于提取所述视频图像的空间语义信息,所述浏览分支用于提取所述视频图像的运动信息;所述特征融合层用于对所述空间语义信息和所述运动信息进行融合,得到融合特征用于行为识别。
38、本发明还提供一种电子设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现如上述任一种所述基于主动感知机制的行为识别方法的步骤。
39、本发明还提供一种非暂态计算机可读存储介质,其上存储有计算机程序,该计算机程序被处理器执行时实现如上述任一种所述基于主动感知机制的行为识别方法的步骤。
40、本发明还提供一种计算机程序产品,包括计算机程序,所述计算机程序被处理器执行时实现如上述任一种所述基于主动感知机制的行为识别方法的步骤。
41、本发明提供的基于主动感知机制的行为识别方法、装置、设备及介质,利用由主动感知机制网络和特征融合层构成的行为识别模型,对待识别的视频图像进行处理,对视频图像中各目标人物的行为进行识别,其中,主动感知机制网络是由包括审视分支和浏览分支的多分支网络结构,审视分支和浏览分支等不同分支网络。通过引入多分支网络和时空自注意力机制,分别用于提取视频图像的空间语义信息和运动信息等不同的特征信息,并通过特征融合层进行特征融合,使得模型具备对多个时间序列信息的分析能力,同时能够提高对视频图像中关键区域的关注能力,从而提高对视频图像中人物行为的识别性能。
- 还没有人留言评论。精彩留言会获得点赞!