一种无监督视频对象分割方法
本发明属于深度学习与计算机视觉领域,具体涉及一种无监督视频对象分割方法。
背景技术:
1、视频对象分割可以被定义为将前景对象与背景区域进行分离的二值标记问题。由于其在监控视频事件提取、动作识别、视频摘要、视频编辑和自动驾驶等实际应用中的强大适用性,它被广泛应用于许多视觉系统中。许多解决视频对象分割任务的工作以半监督形式存在,即给出待分割对象的一帧或者多帧人工标注,逐帧预测待分割对象的掩码。然而,半监督的形式不利于实际的部署和应用。因此,越来越多的研究人员将研究重心转向完全无监督的视频对象分割方法中。
2、早期的无监督视频对象分割模型依赖于手工制作的特征进行启发式分割推断,例如长稀疏点轨迹、背景减法以及超像素光流等。然而,由于缺乏语义信息和对深层特征的理解,这些传统模型在动态和复杂的场景中表现出有限的泛化能力和较低的精度。最近,一些基于深度学习的方法利用了视频的时空一致性,采用全局共同注意机制捕捉频繁出现的显著对象,进行视频对象分割。尽管这些方法取得了性能提高,但仍存在以下问题。首先,这些方法过度依赖于从视频帧对应的光流图像中提取运动特征。然而,公共数据集中的大多数光流图像是通过模型生成的,不可避免存在误差,因此低质量的光流图像对网络的稳定性有较大影响。其次,现有方法忽视了深度信息,而深度信息在rgb-d显著性目标检测等领域被广泛采用以增强模型在复杂场景下提取目标的能力。最后,现有的特征融合方法大多采用元素加或者拼接的方式,不可避免地受到不同模态噪声的干扰。
技术实现思路
1、本发明提出一种无监督视频对象分割方法来解决现有方法存在的上述问题。
2、为实现上述目的,本发明的技术方案为:
3、一种无监督视频对象分割方法,其特征在于包括以下步骤:
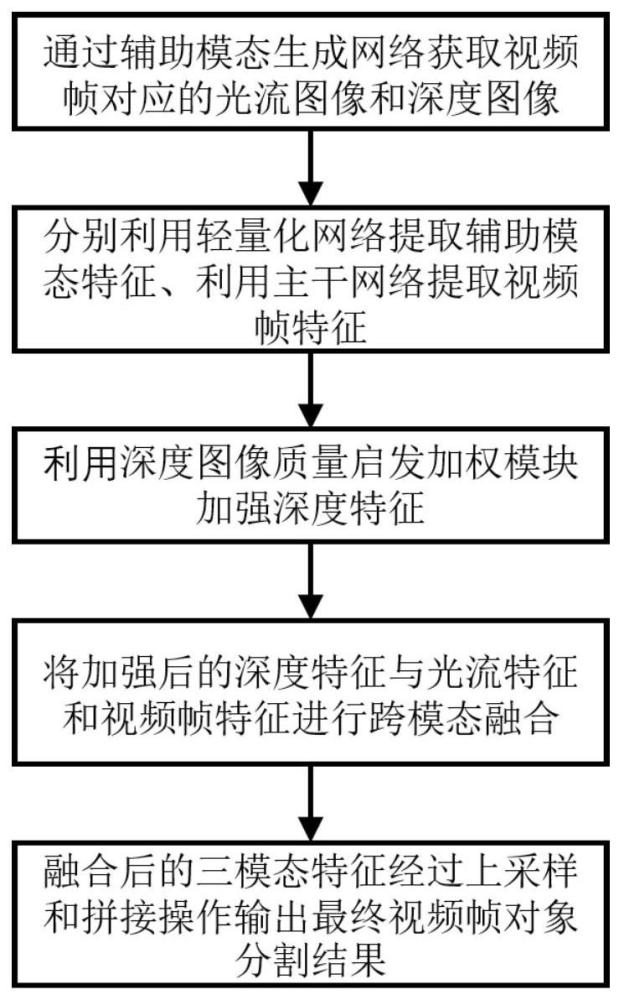
4、s1:获取待分割的视频帧序列,并将其输入到深度图像提取网络megadepth以及光流图像提取网络raft中获取视频帧对应的深度和光流图像;
5、s2:将待分割的视频帧和对应的光流图像以及深度图像输入到训练好的视频对象分割网络中;
6、s3:将resnet-34的前四个残差模块以及一个空洞空间金字塔池化模块的组合作为三流网络权重独立的特征编码器,从视频帧中提取图像特征,并单独设计了针对光流图像和深度图像的辅助模态轻量化特征提取网络,高效提取光流图像特征和深度图像特征;
7、s4:通过深度图像质量启发的跨模态特征加权模块,加强提取到的深度图像特征;
8、s5:将加强后的深度图像特征同视频帧特征和光流图像特征一起传入三模态特征对齐融合模块中,融合三模态特征,过滤背景干扰,生成无监督视频对象分割需要的上下文信息;
9、s6:将融合后的三模态特征不断进行上采样和拼接操作,最终将解码器最后一层输出的t1上采样至原始视频帧大小,作为当前视频帧最终的对象分割结果。
10、进一步的技术方案在于,所述辅助模态轻量化特征提取网络提取五个层级的深度图像特征和光流图像特征,分别记为和所述三流网络权重独立的特征编码器提取五个层级的视频帧特征记为所述辅助模态轻量化特征提取网络在双向残差瓶颈块的基础上构建了一个具有较少堆叠块和较少通道数的主干网络;所述主干网络包含五层,每一层的输入图像大小、输出图像大小、双向残差瓶颈块、输出通道数、瓶颈块重复次数、层次步长分别为:[448×448×1、256×256×1、3、16、1、2],[256×256×16、128×128×24、3、24、3、2],[128×128×24、64×64×32、3、32、7、2],[64×64×32、32×32×96、2、96、3、2],[32×32×96、32×32×320、2、320、1、1]。
11、进一步的技术方案在于,所述深度图像质量启发的跨模态特征加权模块对从深度图像提取的特征进行强化;该模块由跨模态图像质量启发加权子模块和跨模态全局特征加权子模块组成,它们分别产生加权系数λi和加权矩阵βi,其中λi是标量,用于确定深度模态对整体特征的贡献,βi是空间注意力图,明确了深度图像的重要特征区域。
12、进一步地,所述跨模态图像质量启发加权子模块通过步长为4的最大池化法对第一层的三模态特征进行下采样,分别得到和再经由1×1卷积对第一层的三模态特征及下采样后的三个特征进行加强,以捕捉更多和边缘相关的信息;所述第一层的三模态特征分别为:深度图像特征光流图像特征和视频帧特征
13、进一步地,通过预设的相似度计算方法分别对和和和和四组特征进行相似度计算,得到四个相似度向量mr,d、mr,f、mr,f′和mr,d′,再经由通道重组、多层感知机mlp和分离函数fsplit得到五个层级的图像质量启发加权系数λi;所述预设的相似度计算方法首先获取需要计算相似度的两个特征矩阵,接着经过全局平均池化gap、矩阵逐元素相乘、相加以及乘方运算处理,最后利用3×3卷积处理通道;其具体计算过程如下,其中a和b表示需要计算相似度的两个特征矩阵,[.]代表通道重组,bconv表示带有归一化的卷积操作,λi表示五个层级的加权系数:
14、
15、λi=fsplit(mlp[mr,f,mr,d,mr,f′,mr,d′])。
16、进一步地,所述跨模态全局特征加权子模块通过深度分支的深层特征粗略定位显著区域,形成初步监督;为了便于整体注意力计算,通过1×1卷积和四倍上采样操作将上采样至与同样维度大小,并分别利用1×1卷积对三模态的第一层特征和进行边缘激活;其计算过程如下,表示上采样后的特征:
17、
18、进一步地,分别在和和两两之间进行矩阵乘积运算,得到相似矩阵md,r和mf,r;将上采样后的与mf,r相加,模拟低级辅助特征对高级深度信息的第一次校正过程,接着通过步长为1,扩张速率为2的3×3扩张卷积快速扩大感受野,并通过双线性插值实现两倍的上采样和下采样操作得到第一次校正后的特征fef1;紧接着,利用所述第一次校正后的特征fef1与md,r相加,再经由扩张卷积和双线性插值得到第二次校正后的特征fef2;最后,利用3×3卷积操作将上采样后的与第二次校正后的fef2特征融合,得β1,将β1分别进行对应尺度下采样后得到其余空间注意力图;公式表达如下,其中dconv表示扩张卷积,bconv表示带有归一化的卷积操作:
19、
20、
21、
22、进一步的技术方案在于,利用所述三模态特征对齐融合模块将经过增强的深度图像特征与视频帧特征及光流特征进行跨模态融合;所述融合过程旨在减少深度图像特征和光流图像特征之间的噪声,从而通过校正后的深度图像特征和光流图像特征为视频帧特征提供更准确的信息,实现相互增强的效果;所述三模态特征对齐融合模块包含三模态特征对齐子模块和三模态特征融合子模块,它们分别在通道和空间上进行特征对齐并在三模态融合过程中利用不同模态的公共信息来抑制噪声对三模态特征融合的干扰。
23、进一步地,三模态特征对齐子模块包括通道注意力引导的特征融合过程和空间注意力引导的特征融合过程;
24、通道注意力引导的融合过程首先将各个层次的深度图像特征光流图像特征和视频帧特征分别通过全局最大池化gmp和全局平均池化gap操作后,沿通道维度拼接,得到通道对齐特征向量ac1和ac2;随后,将通道对齐特征向量ac1和ac2送入带有sigmoid层的多层感知机mlp中,再经由分离函数fsplit得到基于通道的对齐特征权重矩阵和进一步地,将光流和深度特征与对齐特征权重矩阵进行交错相乘,得到通道注意力引导的对齐特征和计算过程如下:
25、
26、
27、
28、
29、
30、
31、
32、空间注意力引导的融合过程首先对深度图像特征光流图像特征和视频帧特征进行级联空间嵌入,先后通过两个带有relu函数的1×1卷积得到空间对齐特征向量as1和as2,而后将空间对齐特征向量as1和as2依次通过激活函数sigmoid和分离函数fsplit得到基于空间的对齐特征权重矩阵和进一步地,将光流和深度特征与对齐特征权重矩阵进行交错相乘,得到空间注意力引导的对齐特征和计算过程如下:
33、
34、
35、
36、
37、
38、进一步地,将每个层次的深度图像特征和光流图像特征分别与空间注意力引导的对齐特征和通道注意力引导的对齐特征累加,得到初步对齐特征和其具体计算过程如下:
39、
40、
41、进一步地,所述三模态特征融合子模块通过3×3大小的卷积操作对初步对齐的深度图像特征光流图像特征和视频帧特征进行通道调整,得到对齐特征和
42、进一步地通过矩阵相乘获取和以及和之间公共信息,并将公共信息添加回原始特征和中以减少背景噪声,得到计算过程如下:
43、
44、
45、
46、进一步地,通过通道嵌入和1×1卷积融合三模态信息并引入了大小为3×3的深度可分离卷积dwconv和线性归一化层ln来实现从输入到输出端的跳跃连接,输出结果用于最终视频帧对象分割;其具体计算过程如下,其中merge表示通道嵌入,fmerge表示输出结果:
47、
48、进一步的技术方案在于,训练好的视频对象分割网络的训练步骤包括:
49、构建视频对象分割网络;
50、构建训练集,所述训练集为原始视频帧序列及每一帧图像所对应的光流图像和深度图像;
51、将训练集输入到视频对象分割网络中,进行训练;
52、视频对象分割网络输出当前帧对象分割结果的掩码预测;
53、计算当前帧对象分割结果和真实掩码之间的损失;
54、当损失值达到最小时,模型收敛,停止训练,得到训练好的视频对象分割网络。
55、采用上述技术方案产生的有益效果在于:本发明提供了一种深度图像质量启发的跨模态特征加权模块,利用深度特征对辅助模态信息的获取比例进行加权,减少辅助模态图像生成的质量对整体网络稳定性的影响;本发明开发了一种三模态特征对齐融合模块,减少深度图像特征和光流图像特征之间的噪声,通过校正后的辅助模态特征为视频帧特征提供更准确的信息,实现相互增强的效果,提高了时空特征的融合效率;本发明设计了一种轻量化特征提取网络,具有较少堆叠块和较少通道数的同时可以高效提取辅助模态的特征,减少模型参数量,方便模型进行实时推理,提高视频对象分割的效率。所采用的两个模块和一种轻量化网络均集成在所提模型中,充分解决了辅助模态质量参差不齐对网络稳定性的影响,同时整合深度信息使模型在复杂背景下可以更好地分割目标,大幅度提高了视频分割的精度,体现了所提技术方案的优势。
- 还没有人留言评论。精彩留言会获得点赞!