基于知识图谱的大语言模型训练方法与流程
本发明涉及数字数据处理,具体涉及基于知识图谱的大语言模型训练方法。
背景技术:
1、目前,大语言模型广泛应用在文本生成、机器翻译、知识问答、智能对话系统等多个领域中。大语言模型训练集的有效性决定了大语言模型的性能的优劣。由于大语言模型训练时需要较多的数据才能达到一定的准确率,因此,现阶段通常采用数据融合的方法对多源数据进行数据融合,通过数据融合的结果训练大语言模型。
2、多种数据融合时,不同数据中的实体表达形式可能是不同的,导致在不同来源数据构建的知识图谱中相同实体构建的三元组有所不同,这就会导致后续训练大语言模型时造成学习到语义歧义的样本。知识图谱融合的目的是将各领域中来自不同构建者的知识图谱中实体和关系对应匹配,以获得更完整、更丰富的知识图谱。然而,由于知识图谱构建者的主观性和知识的不唯一性,导致不同知识图谱中常常存在表示不同但含义相同的实体,影响大语言模型的训练集的有效性。
技术实现思路
1、本发明提供基于知识图谱的大语言模型训练方法,以解决语义歧义造成的知识图谱实体不对齐,导致训练的大语言模型进行知识问答时性能弱的问题,所采用的技术方案具体如下:
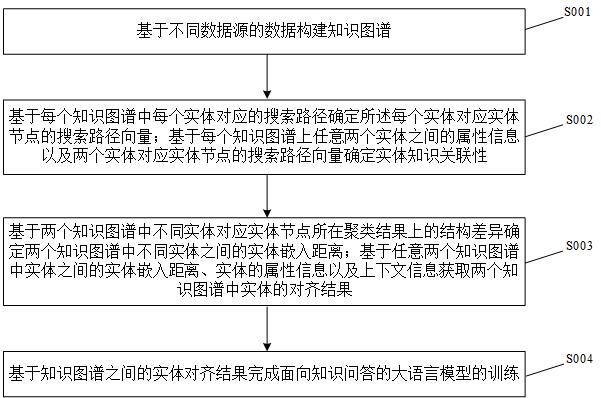
2、本发明一个实施例基于知识图谱的大语言模型训练方法,该方法包括以下步骤:
3、基于不同数据源的数据构建知识图谱;
4、利用深度优先搜索算法基于每个知识图谱中每个实体对应的搜索路径确定所述每个实体对应实体节点的搜索路径向量;基于每个知识图谱上任意两个实体之间的属性信息以及两个实体对应实体节点的搜索路径向量确定实体知识关联性;
5、采用聚类算法基于每个知识图谱的加权实体关联图获取每个知识图谱中实体对应实体节点的聚类结果;
6、基于两个知识图谱中不同实体对应实体节点所在聚类结果上的结构差异确定两个知识图谱中不同实体之间的实体嵌入距离;采用图卷积神经网络基于任意两个知识图谱中实体之间的实体嵌入距离、实体的属性信息以及上下文信息获取两个知识图谱中实体的对齐结果;
7、基于所有知识图谱中实体的对齐结果完成面向知识问答的大语言模型的训练。
8、优选的,所述基于不同数据源的数据构建知识图谱的方法为:
9、利用不同的数据采集方式获取不同来源的文本数据;
10、将每种来源的文本数据作为一类原始数据,采用实体命名识别技术、关系抽取技术对每类原始数据进行处理得到预设数量个三元组,基于预设数量个三元组构建每类原始数据的知识图谱。
11、优选的,所述利用深度优先搜索算法基于每个知识图谱中每个实体对应的搜索路径确定所述每个实体对应实体节点的搜索路径向量的方法为:
12、抽取每个知识图谱中同一层级中的所有实体,将所述同一层级中每个实体作为一个实体节点,将任意存在关系的两个实体进行连线,将利用同一层级中的所有实体构建的无向图作为每个知识图谱的同类实体关联图;
13、将每个知识图谱的同类实体关联图作为输入,依次将每个实体节点作为起始节点,采用深度优先搜索算法确定每个实体节点的搜索路径;
14、统计每个实体节点的搜索路径上节点的数量,通过按照位置顺序递减、递减尺度为1的方式对所述搜索路径上的每个节点的位置权重进行赋值,将所述节点的数量作为所述搜索路径上第一个节点的位置权重,将所述搜索路径上最后一个节点的位置权重赋值为1;
15、将所述搜索路径上每个节点对应的词向量作为数组中的第一个元素,将所述搜索路径上每个节点的位置权重作为数组中的第二个元素,将所述搜索路径上每个节点对应的词向量、位置权重组成的数组作为所述搜索路径上每个节点的特征数组;
16、将所有所述节点的特征数组按照距离每个实体节点由近到远的顺序组成的向量作为每个实体节点的搜索路径向量。
17、优选的,所述基于每个知识图谱上任意两个实体之间的属性信息以及两个实体对应实体节点的搜索路径向量确定实体知识关联性的方法为:
18、基于每个知识图谱中两个实体之间属性信息的差异确定两个实体之间的属性相似度;
19、将两个实体之间的属性相似度的相反数与两个实体对应实体节点的搜索路径向量之间的度量距离之和作为第一计算因子;将第一计算因子的数据映射结果作为两个实体之间的实体知识关联性。
20、优选的,所述基于每个知识图谱中两个实体之间属性信息的差异确定两个实体之间的属性相似度的方法为:
21、将每个知识图谱上的每个实体作为一个目标实体,将每个目标实体与其余任意一个实体在目标实体每个属性上属性值差值的绝对值作为第一组成因子;将第一组成因子与每个知识图谱中具有目标实体每个属性的实体数量的乘积作为第一累加因子;
22、将第一累加因子在目标实体所有属性上的累加结果与预设参数之和的倒数作为每个目标实体与其余任意一个实体之间的属性相似度。
23、优选的,所述采用聚类算法基于每个知识图谱的加权实体关联图获取每个知识图谱中实体对应实体节点的聚类结果的方法为:
24、将每个知识图谱上任意两个实体之间的实体知识关联性作为每个知识图谱的同类实体关联图中相应两个实体节点之间的连线权重;每个知识图谱的同类实体关联图添加所有所述连线权重后的结果作为每个知识图谱的加权实体关联图;
25、将每个知识图谱的加权实体关联图作为输入,采用普利姆prim算法得到每个知识图谱对应的最小生成树;将每个知识图谱对应的最小生成树作为输入,采用最小生成树算法得到每个知识图谱的加权实体关联图上每个实体节点所在的子树。
26、优选的,所述基于两个知识图谱中不同实体对应实体节点所在聚类结果上的结构差异确定两个知识图谱中不同实体之间的实体嵌入距离的方法为:
27、将每个子树上每个节点与其余任意一个节点之间的连线的距离作为分子;将每个子树上每个节点与其余任意一个节点对应词向量之间的相似性度量与预设参数之和作为分母;将分子分母的比值作为每个子树上每个节点与其余任意一个节点之间的簇内结构距离;
28、将每个子树上每个节点与其余所有节点之间的簇内结构距离组成的向量作为每个子树上每个节点对应实体的簇内距离向量;
29、基于两个知识图谱中两个实体的簇内距离向量以及两个实体所在子树的相似程度确定所述两个实体之间的实体嵌入距离。
30、优选的,所述基于两个知识图谱中两个实体的簇内距离向量以及两个实体所在子树的相似程度确定所述两个实体之间的实体嵌入距离的方法为:
31、获取任意两个子树之间的最大公共子树,将所述最大公共子树上节点的数量与两个子树上节点数量中最大值的比值作为两个子树之间的树相似度;并将每个子树上任意一个不在所述最大公共子树上的节点标记为每个子树上的一个欺诈节点;
32、将两个知识图谱中两个实体的簇内距离向量之间的度量距离作为第一乘积因子;将两个知识图谱中两个实体对应实体节点所在子树上欺诈节点数量之和的数据映射结果作为第二乘积因子;将第一乘积因子与第二乘积因子的乘积与预设参数之和作为分母;
33、将两个知识图谱中两个实体对应实体节点所在子树之间的树相似度与分母的比值作为所述两个实体之间的实体嵌入距离。
34、优选的,所述采用图卷积神经网络基于任意两个知识图谱中实体之间的实体嵌入距离、实体的属性信息以及上下文信息获取两个知识图谱中实体的对齐结果的方法为:
35、获取每个知识图谱中每个实体与其余每个知识图谱中每个实体之间的实体嵌入距离,将每个知识图谱中每个实体与其余任意一个知识图谱中所有实体之间的实体嵌入距离组成的向量作为一个行向量;
36、将每个知识图谱中每个实体对应的所有行向量构建的矩阵作为每个知识图谱中每个实体的邻接矩阵;
37、将两个知识图谱中每个实体的邻接矩阵、属性信息、上下文信息、关系信息作为输入,利用图卷积神经网络得到两个知识图谱中的实体对齐结果。
38、优选的,所述基于所有知识图谱中实体的对齐结果完成面向知识问答的大语言模型的训练的方法为:
39、获取任意两个知识图谱之间的实体对齐结果,将每个知识图谱上每个实体与其对齐实体进行等价链接,遍历所有知识图谱得到融合知识图谱;
40、从融合知识图谱中抽取每个实体以及对齐实体,采用实体链接技术将每个实体以及对齐实体映射到原始数据中的文本片段,将所有实体及其对齐实体映射的文本片段组成的数据库作为训练语料库,基于训练语料库训练面向知识问答的大语言模型。
41、本发明的有益效果是:本发明通过每个知识图谱中每个实体与周围实体之间的关联性得到每个实体的搜索路径以及搜索路径向量,其次基于搜索路径向量以及同类实体之间的属性信息确定实体之间的实体知识关联性,并基于实体知识关联性构建加权实体关联图,提高了后续进行实体对齐时构建邻接矩阵的有效性;其次根据不同加权实体关联图的聚类结果确定不同知识图谱中实体的实体嵌入距离,其有益效果在于通过度量每个实体节点所在子树之间的结构相似性和语义信息能够准确反映实体作为三元组中尾实体被后续神经网络模型中嵌入向量替换的概率,提高了实体对齐效果;其次基于实体对齐效果进行知识图谱的融合补全,避免原始数据中的语义歧义以及噪声的干扰,提高了后续大语言模型训练集的有效性,增强了大语言模型的回复性能。
- 还没有人留言评论。精彩留言会获得点赞!