基于多特征提取的复杂场景火灾检测方法
本发明涉及火灾检测,用于复杂场景下的火灾目标识别,尤其涉及一种基于多特征提取的复杂场景火灾检测方法。
背景技术:
1、近年来,火灾已严重威胁到全世界人民的生命和财产安全,促使人们对火灾检测开展了广泛研究。随着科技水平的进步,火灾燃烧物的类型变得更加多样,火灾的发生场景也更加复杂。一旦发生火灾,它可能会迅速升级,造成广泛的破坏,并导致更高的伤亡。在这些情形下,火灾检测对于精确率和实时性有更高的要求。
2、传统的基于传感器的火灾检测方法通常依赖于对烟雾、温度、光线和气体浓度等参数的检测。然而,在复杂场景中的火灾可能会生成多个需要检测的参数,依靠单一类别的传感器进行火灾检测可能会导致漏检和延迟报警。此外,传感器主要部署在室内环境中,难以满足各种场景的需求。
3、基于传统图像处理的火灾检测方法主要通过对视频图像中的频率、颜色以及几何特征对火灾进行识别与检测,当以上特征大于人为设定的阈值时就会识别为火灾。可是此种方法需要采用人工导入先验信息和设定阈值。尽管研究人员已经尽可能地挖掘了各种火焰特征,但复杂场景中的火焰特征仍难以把握,而模型的检测效果也受到设计特征的局限,存在准确度低、受环境干扰大等缺陷。
4、基于深度学习的火灾检测方法可以根据应用的技术分为分类模型、检测模型、分割模型3大类方法。基于分类任务的火灾检测方法是对于给定的图像,只能判断图像中是否含有火焰或烟雾。基于分割任务的火灾检测方法能够定位、分割并预测输入图像中火灾烟雾的位置、区域和类别,但是像素级标注的数据集需要大量的人力,实际应用时,往往会受到限制。目前基于目标检测技术的火灾检测方法将火灾探测任务作为端到端操作来执行,以提高推理速度,使其更适合实现实时火灾探测。然而,通用的目标检测算法难以满足复杂场景下的火灾探测要求。
5、fire-yolo[1]从三个维度拓展了特征提取网络,使网络对火灾场景中小目标物体的更加敏感,降低了模型的参数,但是其应用场景仅针对森林火灾。
6、light-yolov5[2]设计了一种轻型双向特征金字塔网络以实现模型的轻量化,并集成了全局注意力机制gam来增强骨干网络和全局信息的联系,但是精度有所降低。light-yolov4[3]将主干网络更换为mobilenetv3,并采用了深度可分离卷积,实现了火灾检测模型的轻量化;但是精度低于原始算法。t-yolox[4]在yolox模型的基础上增加了通道混洗模块来增强不同通道的信息交流能力;并集成了vit模块,在复杂场景中实现对火灾、烟雾和人员的检测,但是会显著增加模型的计算量,不利于部署。
7、由于复杂场景中燃烧材料、照明、气流等环境因素的影响,火焰的形状会受到周围环境的影响而发生变化。而许多类似火焰的物体,如灯、橙色衣服等,具有与火焰相似的特性,这会导致现有的火灾检测方法表现出较差的检测效果。此外,复杂场景中的前景障碍物可能会导致火灾目标的遮挡和截断。而在室外空间大、环境因素多样的情况下,摄像头从远处捕捉到的火灾图像的分辨率一般较低,而火灾目标中又往往存在模糊和变形,这些因素增加了准确检测火灾的复杂性和难度。
8、由于火焰的蔓延以及视频监控拍摄的角度和距离并不固定,因此火灾目标的尺度变化较大。常规的目标检测网络在对火灾图像的特征提取的过程中没有针对火焰烟雾的特点进行优化,难以准确地识别火灾区域和背景区域,从而导致漏检。现有的基于深度学习的方法无法准确表达火灾特征,容易受到光线、气流和障碍物的影响。目前火灾探测通常通过复杂的特征融合来提高探测精度。特征金字塔网(fpn)[5]通过上采样将低级和高级特征相结合。路径聚合网络(panet)[6]在fpn的基础上添加了一个自底向上的路径聚合网络。而加权双向特征金字塔网络(bifpn)[7]引入可学习的权重来学习不同输入特征的重要性,同时反复应用自顶向下和自底向上的多尺度特征融合。以上几种特征融合网络虽然能结合多尺度特征以提高火灾检测的精度,但融合过程可能会导致重要信息的丢失或不相关特征的合并。
9、本发明涉及的参考文献包括:
10、[1]l.zhao,l.zhi,c.zhao,and w.zheng,“fire-yolo:a small target objectdetection method for fire inspection,”sustainability,vol.14,no.9,p.4930,2022.
11、[2]h.xu,b.li,and f.zhong,“light-yolov5:a lightweight algorithm forimproved yolov5 in complex fire scenarios,”applied sciences,vol.12,no.23,p.12312,2022.
12、[3]y.wang,c.hua,w.ding,and r.wu,“real-time detection offlame andsmoke using an improved yolov4 network,”signal,image and video processing,vol.16,no.4,pp.1109–1116,2022.
13、[4]j.zhang,s.ke,and others,“improved yolox fire scenario detectionmethod,”wireless communications and mobile computing,vol.2022,2022.
14、[5]t.-y.lin,p.dollár,r.girshick,k.he,b.hariharan,and s.belongie,“feature pyramid networks for object detection,”in proceedings ofthe ieeeconference on computer vision and pattern recognition,2017,pp.2117–2125.
15、[6]s.liu,l.qi,h.qin,j.shi,and j.jia,“path aggregation network forinstance segmentation,”in proceedings of the ieee conference on computervision and pattern recognition,2018,pp.8759–8768.
16、[7]m.tan,r.pang,and q.v.le,“efficientdet:scalable and efficientobject detection,”in proceedings ofthe ieee/cvf conference on computer visionand pattern recognition,2020,pp.10781–10790.
17、[8]zhu x,hu h,lin s,et al.deformable convnets v2:more deformable,better results[c]//proceedings of the ieee/cvf conference on computer visionand pattern recognition.2019:9308-9316.
18、[9]j.hu,l.shen,and g.sun,“squeeze-and-excitation networks,”inproceedings of the ieee conference on computer vision and patternrecognition,2018,pp.7132–7141.
19、[10]c.li et al.,“yolov6:a single-stage object detection framework forindustrial applications,”arxiv preprint arxiv:2209.02976,2022.
20、[11]wang c y,bochkovskiy a,liao h y m.yolov7:trainable bag-of-freebies sets new state-of-the-art for real-time object detectors[c]//proceedings of the ieee/cvf conference on computer vision and patternrecognition.2023:7464-7475.
21、[12]z.zheng,p.wang,w.liu,j.li,r.ye,and d.ren,“distance-iou loss:faster and better learning for bounding box regression,”in proceedings of theaaai conference on artificial intelligence,2020,pp.12993–13000.
22、[13]z.gevorgyan,“siou loss:more powerful learning for bounding boxregression,”arxiv preprint arxiv:2205.12740,2022。
技术实现思路
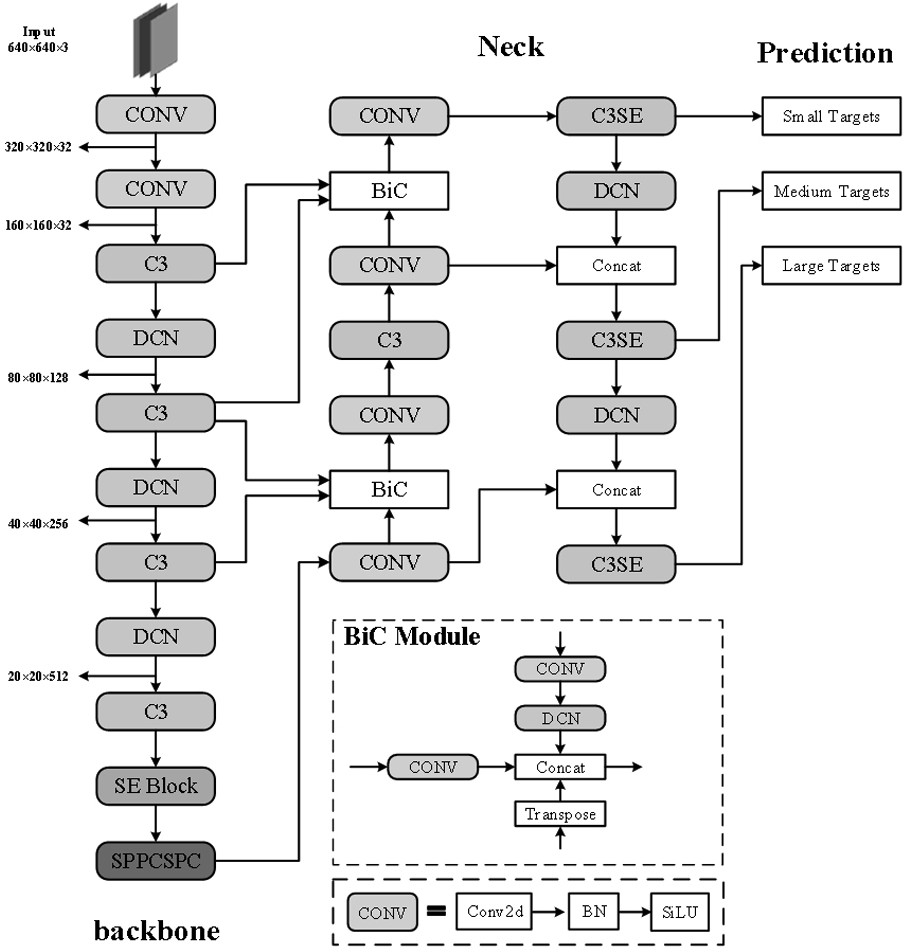
1、针对现有技术存在的缺陷和不足,本发明的目的在于提供一种基于多特征提取的复杂场景火灾检测方法,该方法的模型基于yolov5s的结构。首先,应用可变形卷积来增强火灾的视觉表现,并使用这个新模块重建主干网络。其次,在网络中嵌入了压缩与激励注意力模块,强调了火灾相关的特征,减少了不相关信息的融合。第三,修改neck结构以完全融合不同的特征图,并用sppcpc块代替sppf块以扩大感受野,增强网络对小火灾目标的识别能力。同时使用siou损失函数进行训练,以提高模型的收敛速度和精度。
2、本发明具体采用以下技术方案:
3、一种基于多特征提取的复杂场景火灾检测方法,采用的检测模型基于yolov5s结构;针对火灾目标由视角和火焰扩散引起目标的几何形状变化,采用可变形卷积重构主干网络,以提升模型的特征提取能力;同时引入注意力机制,在主干网络的最后一层和颈部结构添加se注意力模块,以提升对火灾识别的精确率;采用改进的bifusion neck结构,以提升网络对小火灾目标的定位识别能力;并采用siou边框回归损失函数对模型的损失函数进行调整。
4、进一步地,通过骨干网络提取的特征图在进入颈部结构进行特征融合之前经过se块以减少火灾探测时来自复杂环境中类火物体的干扰;并将se块纳入颈部结构中的三个检测分支内,形成包括三个卷积块和一个se块构成的c3se结构。
5、进一步地,在原始的特征金字塔中添加一路来自更低级别的额外特征图,以保留更精确的小火灾信息;浅层的特征经过下采样与深层特征的尺度相匹配;使用通道连接将三个特征连接在一起,以增加特征中包含的信息量。
6、进一步地,采用sppcspc块代替sppf块,以增强网络的特征表达能力。
7、以及,一种基于多特征提取的复杂场景火灾检测系统,其特征在于,包括存储器、处理器以及存储于存储器上并能够被处理器运行的计算机程序指令,当处理器运行该计算机程序指令时,能够实现如上所述的方法步骤。
8、针对现有火灾检测方法难以满足复杂场景中的速度和精度要求,本发明及其优选方案在yolov5的基础上提出了一种基于多特征提取的复杂场景火灾检测方法。针对火灾目标由视角和火焰扩散引起目标的几何形状变化,采用可变形卷积重构主干网络,提升模型的特征提取能力。同时引入注意力机制,在主干网络的最后一层和颈部结构添加了se注意力模块,提升对火灾识别的精确率。采用改进的bifusion neck结构,提升网络对小火灾目标的定位识别能力。并采用siou边框回归损失函数对模型的损失函数进行调整。
- 还没有人留言评论。精彩留言会获得点赞!