基于多源监测数据驱动的堆石坝变形分析模型的更新方法
本技术涉及水利工程及岩土工程的,尤其涉及基于多源监测数据驱动的堆石坝变形分析模型的更新方法。
背景技术:
1、监测技术和数据采集平台的快速发展引领着大数据时代的到来。堆石监测已经从过去的稀疏测点和少量监测仪器及技术的监测布局,逐渐演变为各种新型和常规监测技术的协同合作,形成了全方位及全时段的监测布局。高精度的传感器、复杂的信号调节装置、光学和无线网络、全球定位系统和其他技术有助于发展更精确、成本效益更高的监测系统。
2、然而,相关技术中数据采集的便利性也导致了显著的“数据洪水”现象。在堆石坝所积累的海量多源监测数据背景之下,用于更新堆石坝计算模型的方法在多源监测数据的筛选和有效利用方面等面临挑战,这可能导致在更新过程中使用的监测信息质量不均匀,信息冗余和数据利用不充分等问题,从而最终降低分析模型的模拟精度。
技术实现思路
1、有鉴于此,本技术提供基于多源监测数据驱动的堆石坝变形分析模型的更新方法,提高分析模型的模拟精度。
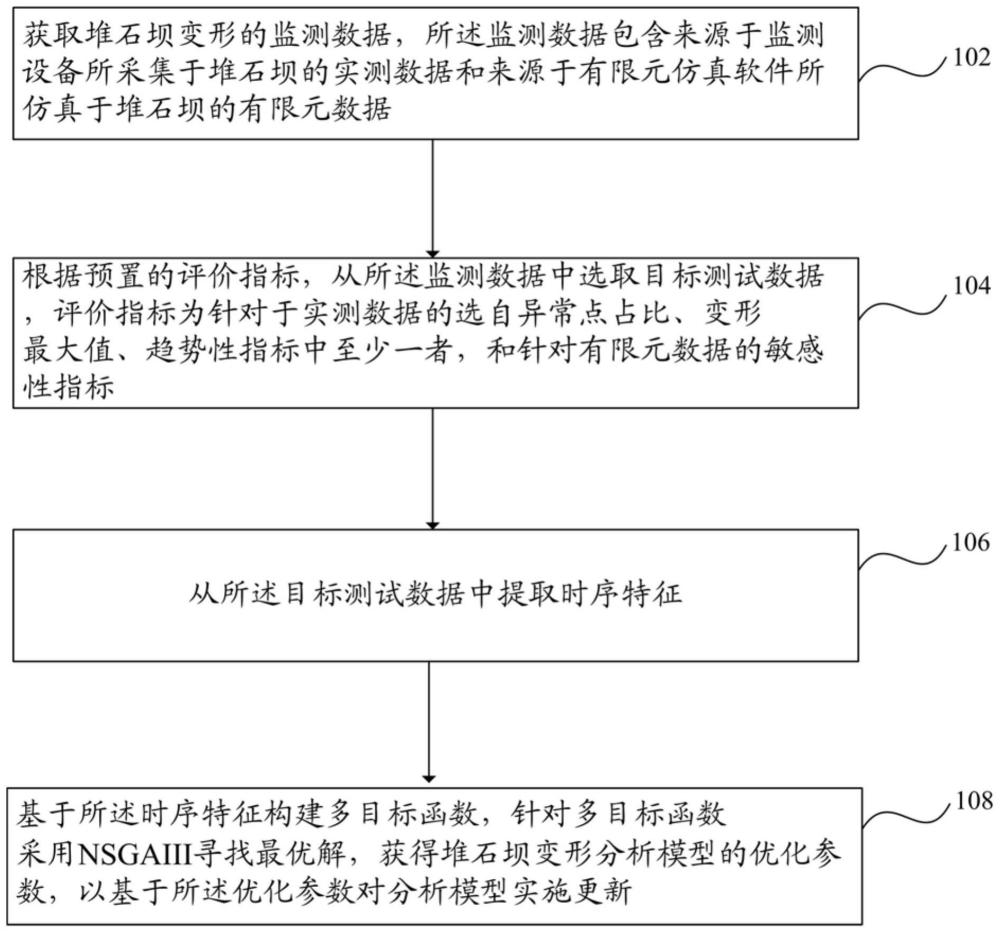
2、本技术提供一种基于多源监测数据驱动的堆石坝变形分析模型的更新方法,包括:
3、获取堆石坝变形的监测数据,所述监测数据包含来源于监测设备所采集于堆石坝的实测数据和来源于有限元仿真软件所仿真于堆石坝的有限元数据;
4、根据预置的评价指标,从所述监测数据中选取目标测试数据,所述评价指标为针对于实测数据的选自异常点占比、变形最大值、趋势性指标中至少一者,和针对有限元数据的敏感性指标;
5、从所述目标测试数据中提取时序特征;
6、基于所述时序特征构建多目标函数,针对多目标函数采用nsga-iii寻找最优解,获得堆石坝变形分析模型的优化参数,以基于所述优化参数对分析模型执行更新。
7、可选地,根据预置的评价指标,从所述监测数据中选取目标测试数据,具体包括:
8、构建云模型,并根据所述云模型分别获得各所述评价指标的隶属度;
9、根据critic法获得所述评价指标的指标权重;
10、由所述指标权重、所述隶属度获得评价指标的综合隶属度;
11、基于所述综合隶属度,获取目标测试数据。
12、可选地,寻找最优解采用集成代理模型来执行。
13、可选地,所述异常点占比的预置,包括:
14、将单测点的实测数据进行stl分解,采用加法模型,将实测数据分解为趋势项t,季节性分量s以及残差项r,如式(1),
15、sti(x(t))=t+s+r (1),
16、其中,该式中,stl(x(t))为进行stl分解后的各分项时间序列;
17、对s+r进行grubbs异常值检测,获取异常点数量n,如式(2),
18、n=grubbs(s+r) (2);
19、将异常点数量除以测点的测值总数n,获得异常点占比or,如式(3),
20、
21、所述变形最大值的预置,通过式(4)来执行,
22、md=max(x(t)) (4);
23、式中,x(t)为监测数据时间序列;
24、所述趋势性指标的预置,通过式(5)和(6)来执行,
25、lg(r/s)m=h lg n+lgθ (5);
26、ti=h (6);
27、式中,r/s代表时间尺度为m时的重新缩放范围,h为hurst指数,γ为表征时间序列固有属性的常数,ti为趋势性指标;
28、所述敏感性指标的预置,通过式(7)和(8)来执行,
29、
30、si=∑μj (8);
31、式中,μj为敏感性因子,q为模型运行的次数,yi代表从第i次模型运行中获得的测量点计算变形值,y0是由具有初始参数的模型计算得到的输出值,pi为第i次模型运行的参数值,p0是初始参数,si为敏感性指标。
32、可选地,根据critic法获得所述评价指标的指标权重,包括:
33、通过如式9获得各评价指标经过正向归一化处理后的原始指标数据矩阵:
34、
35、通过分别计算各指标的均值与标准差sj获得各评价指标变异性,如式(10)所表示,
36、
37、式中,mi,j表示第j个评价指标对应的第i个测点指标值,n表示对应指标中所包含的测点个数;
38、计算指标冲突性rj,即用指标之间的相关系数rij来表示,再与指标变异性相乘sj,获得指标中包含的信息量cj,如式11、式12所表示,
39、rj=∑(1-rij) (11);
40、cj=sj∑i(1-rij)=sj·rj (12)。
41、根据信息量cj计算各指标客观权重wj,如式13所示,
42、
43、可选地,构建云模型,包括:
44、将监测数据根据归一化后的指标进行排序,选取监测数据作为对应指标mj的可选点集合{x1jfea,x2jfea,...,xnjfea},接下来的num(para)个监测数据作为模糊点集合{x1jblu,x2jblu,...,xnjblu},剩余点作为粗糙点集合{x1jrou,x2jrou,...,xnjrou};
45、通过逆向云发生器,计算每个集合的云模型指标(ex,en,he),如公式14,15与16所示,
46、
47、
48、
49、式中,下标i表示集合中的第i个测点,j表示第j个评价指标,s为测点指标方差,n为集合中测点个数;
50、根据云模型指标(ex,en,he)生成正态模糊云模型,并用高斯模糊隶属度计算各个指标下单一测点属于各评价等级的隶属度,并结合客观权重得到综合隶属度,如公式17、18所示,
51、
52、
53、式中,μ(x)表示测点的综合隶属度,ωj表示不同评价指标的客观权重,μj(x)表示第j个指标的隶属度。
54、可选地,由所述指标权重、所述隶属度获得评价指标的综合隶属度,具体为:
55、根据单测点的隶属度矩阵与客观权重相乘计算,可得综合隶属度,如式19所示,
56、
57、可选地,所述时间序列特征包括变异系数vc、自相关系数acf和极差r,提取时序特征包括:
58、通过式(20)获得变异系数,
59、
60、式中,x(t)表示变形时间序列,表示序列中的变形值的均值;
61、通过式(21)获得自相关系数,
62、
63、式中,l表示滞后长度,σ表示序列中变形数据的标准差;
64、通过式(22)获得极差,
65、r=max(x(t))-min(x(t)) (22);
66、式中,max(x(t))与min(x(t))分别表示变形时间序列中的最大及最小值。
67、可选地,采用集成代理模型来执行,具体为:
68、采用集成代理模型所采用的集成方法为堆叠法;
69、通过采用xgboost,gpr与mlp作为基模型,gbdt作为终模型,并通过采用随机搜索方式进行超参数优化,使所述集成代理模型进行参数组合与时间序列的回归训练。
70、可选地,所述多目标函数通过式(23)来执行,
71、
72、式中,u(μ)为多目标函数;f(1),f(2),...,f(a)为对应于不同材料区域的目标函数;n(i)为第i个材料区域拥有的时序特征的数量,包括vc,acf和r;和分别为第j个特征的监测值和有限元值;λ(i)为第i个材料区域的参数组合。
73、与相关技术相比,本技术具有以下有益效果:
74、1)提出一个基于堆石坝的各阶段的变形监测数据的测点筛选模型构建方法。该模型将预先选定的测点分类为可行点、模糊点和粗糙点,从而筛选出用于模型更新的高质量测点,该方法能为同类计算分析模型更新的测点质量提升问题提供方法及思路;
75、2)提出一个基于筛选后测点的参数识别方法。本发明采用时序特征来表征堆石坝的变形,反映复杂的填筑、蓄水和运行过程对堆石坝变形时空分布与演化的影响,提升数据的利用率;同时构建基于材料分区及时序特征的目标函数,保证堆石坝的整体与各个分区的协调统一。采用集成学习代理模型与nsga-iii算法,保证整个模型更新流程的准确性。为堆石坝的变形分析模型更新做出贡献。
- 还没有人留言评论。精彩留言会获得点赞!