一种基于TRIE树的文本快速匹配方法与流程
本发明涉及一种基于trie树的文本快速匹配方法。
背景技术:
1、随着互联网技术的发展,各种社交系统和电商系统也应运而生,方便了用户的沟通和购物,但同时也产生了海量的用户数据。因此处理和检索大量文本数据已成为一个重要的挑战。
2、现有的传统文本匹配算法普遍基于正则表达式和字符串匹配算法。正则表达式功能虽然强大,但是对于模式匹配会变得比较负责,而且难以理解和维护,在处理大规模文本是效率比较低下,耗时也较长。传统的字符串匹配算法(如kmp)在大规模数据集匹配效率较高,但是对于模糊匹配或多模式匹配等复杂场景可能不够高效。
技术实现思路
1、本发明要解决的技术问题是为了解决传统的文本匹配算法效率逐渐低下、耗时加长的问题,提供一种基于trie树的文本快速匹配方法。
2、本发明是通过下述技术方案来解决上述技术问题:
3、本发明提供一种基于trie树的文本快速匹配方法,所述trie树的文本快速匹配方法包括如下操作步骤:
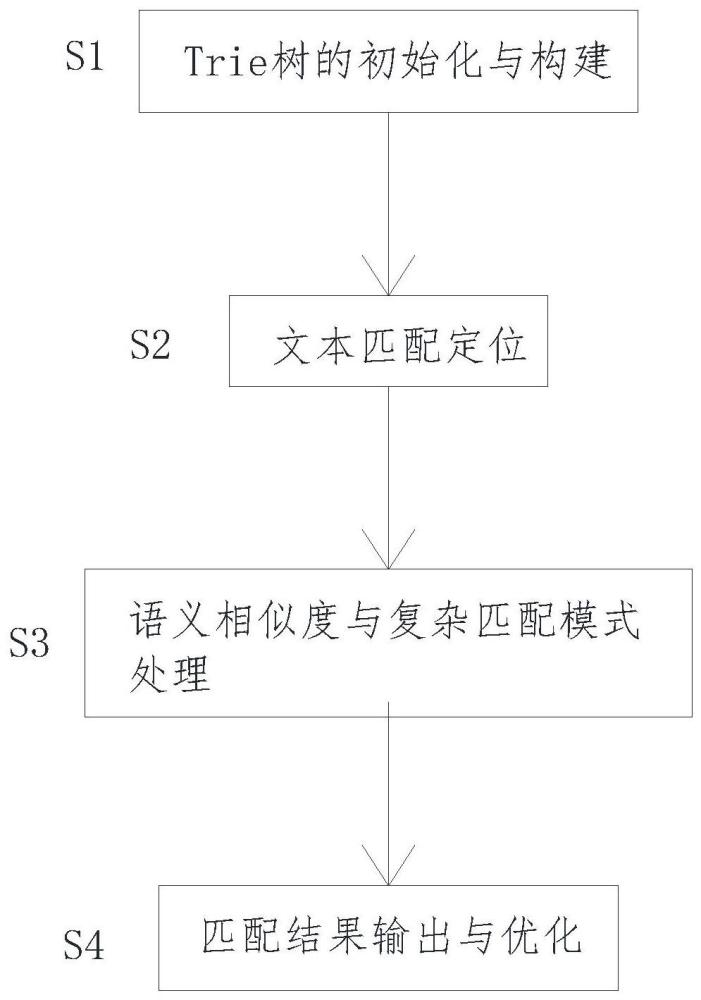
4、s1、trie树的初始化与构建,对输入的文本数据集进行预处理,并建立起trie树的数据结构;
5、s2、文本匹配定位,利用trie树快速导航的特性,实现了对输入查询文本的快速定位和匹配;
6、s3、语义相似度与复杂匹配模式处理,在匹配过程中加入了对语义的考量和对复杂模式的支持,以实现更灵活准确的匹配策略;
7、s4、匹配结果输出与优化,向用户提供匹配结果,并根据匹配操作的历史进行性能优化。
8、所述s1步骤中是通过对数据的预处理,对trie树中的每个唯一词或字符序列建立基础节点。
9、所述s1步骤中具体流程为:
10、步骤一:收集文本数据:在收集的文本数据集中提取所有唯一的词汇,并明确数据集合的输入格式,确保数据可以被正确的处理。
11、步骤二:数据降噪处理:将步骤一的词汇数据进行降噪和标准化处理,主要是去除标点符号、停用词和非标准符,规范化文本的输入。
12、步骤三:创建树根节点:该步骤主要是创建一个根节点,作为trie树的起始点,同时trie树每个节点定义数据结构,包括字符值、子节点链接和节点结束标记。
13、步骤四:连接树根各节点:将步骤三每个字符的节点按序链接起来,形成词汇路径,同时将数据集中的第一个单词或字符插入trie树中。
14、步骤五:合并相通前缀:该步骤主要是合并相同前缀的词汇节点,形成分支,依次将其他单词或字符序列加入trie树,复用共同前缀。
15、步骤六:设置终止符:该步骤在每个字符串的末尾字符的节点上设置终止标志,表示一个字符串在此结束。
16、步骤七:优化树:该步骤主要是对trie树结构进行内存优化,为trie树中的节点创建索引以加快检索速度。
17、步骤八:测试树的正确性:测试trie树以确保所有词汇都已正确插入。
18、步骤九:结束。
19、在本技术方案中,文本前缀进行优先匹配的方法,由于不需要遍历整个数据集进行搜索匹配,本方法减少了cpu周期的使用,同时少用了内存,因搜索过程中只交互了路径上的节点,减少了资源消耗。
20、所述s2步骤中具体流程为:
21、步骤一:查询处理:输入查询处理,标准化输入查询以匹配trie树的格式。
22、步骤二:定位根节点:根节点定位计算,定位到trie树的根节点开始匹配进程。
23、步骤三:匹配目标值:字符匹配,逐字符匹配查询字符串。
24、步骤四:是否匹配:出现分支选择时,选择与查询字符串匹配的分支。
25、所步骤四中当查询的分支与字符串不匹配时,流程为:
26、步骤五:进行回溯以寻找其他可能的匹配路径。
27、所步骤四中当查询的分支与字符串匹配时,流程为:
28、步骤六:终止节点检测:检测是否到达词汇的终止节点,确认完全匹配。
29、步骤七:确保匹配完整性:根上下文检验,对于找到的匹配项,检查其上下文以确保完整匹配。
30、步骤八:部分匹配记录,即记录部分匹配结果供后续步骤使用。
31、步骤九:结果缓存:将匹配结果存入缓存以提高后续查询效率。
32、步骤十:返回匹配信息:结果反馈,将匹配结果反馈给用户或后续处理模块。
33、步骤十一:结束。
34、在本技术方案中,在trie树的每个节点处可以保存与文本段相关的额外信息(例如词频),从而提供了更为精确的上下文和语义匹配,增强了匹配结果的准确性。相比传统的文本搜索方法,这显著减少了搜索时间。
35、所述s3步骤中具体的架构流程为;
36、步骤一:语义分析器配置:配置语义分析器用于解析输入字符串及trie树中字符串的语义关系。
37、步骤二:模式匹配器定义:定义支持复杂匹配模式的规则,如通配符、字符类别等。
38、步骤三:扩展查询:将简单查询转化为多可能性查询,以适配语义模糊和模式匹配。
39、步骤四:字符串语义标注:对trie树中的字符串进行语义标注,以支持基于语义的搜索。
40、步骤五:语义匹配:根据预定义的语义规则和用户查询进行匹配,寻找语义上接近的词或短语。
41、步骤六:模式识别:运用模式匹配器识别用户查询中的特殊字符和模式。
42、步骤七:递归匹配实现:实现递归匹配,以处理嵌套或复合的查询模式。
43、步骤八:概率权重计算:为模糊匹配结果计算权重,以确定最佳匹配。
44、步骤九:语义补偿机制:当遇到无法完全匹配的情况,通过语义补偿来找到最接近的匹配项。
45、步骤十:结果综合输出:将语义相似度和复杂匹配模式处理的结果整合输出,提供详尽的匹配信息。
46、步骤十一:结束。
47、所述s4步骤中具体流程为:
48、步骤一:输出格式定义:定义匹配结果的输出格式。
49、步骤二:结果提取:从匹配定位模块提取匹配结果和必要的上下文信息。
50、步骤三:性能数据收集:记录匹配过程中的性能数据。
51、步骤四:优化策略制定:根据收集的性能数据制定trie树的动态优化策略。
52、步骤五:节点重排:根据查询频率和模式,对trie树的节点进行重排优化。
53、步骤六:树修剪:移除trie树中长期未被访问的节点或分支,以释放资源。
54、步骤七:索引更新:保持trie树索引的实时更新,以匹配新的数据集更改。
55、步骤八:缓存机制实现:实现缓存机制,以提高常见查询的响应速度。
56、步骤九:结果输出测试:定期测试输出功能,确保结果的准确性和格式的标准化。
57、步骤时:结束。
58、所述步骤一中的输出格式为纯文本、json、或xml。
59、所述步骤三中的记录的性能数据为检索时间和检索次数。
60、在符合本领域常识的基础上,上述各优选条件,可任意组合,即得本发明各较佳实例。
61、本发明的积极进步效果在于:
62、1.提出一种根据文本前缀进行优先匹配的方法,由于不需要遍历整个数据集进行搜索匹配,本方法减少了cpu周期的使用,同时少用了内存,因搜索过程中只交互了路径上的节点,减少了资源消耗。
63、2.提出了一种利用节点存储文本的相关信息的方法,在trie树的每个节点处可以保存与文本段相关的额外信息(例如词频),从而提供了更为精确的上下文和语义匹配,增强了匹配结果的准确性。相比传统的文本搜索方法,这显著减少了搜索时间。
64、3.基于定位到匹配文本的速度快的原因,可以为用户提供接近实时的搜索结果反馈,具有很高的实时性。
- 还没有人留言评论。精彩留言会获得点赞!