一种基于大规模语言模型的密集视频检测方法
本发明属于密集视频检测,涉及一种基于大规模语言模型的密集视频检测方法。
背景技术:
1、密集视频检测任务旨在对视频中所有事件进行时间定位。密集视频检测可以有效应用到在线视频中,帮助用户快速定位感兴趣的视频片段,不必观看整个视频,有助于长视频的理解,是非常具有意义的一项任务。
2、传统的密集视频检测任务可以分解为两个子任务:事件定位和片段级视频字幕识别,事件定位中会预测每一个事件的时间边界,并对定位的时间识别视频字幕,通常需要两个不同的底层模型架构。这种两阶段的方式不仅需要更多的人工设计组件,片段级视频字幕的效果严重依赖事件定位的准确度。由于事件定位和片段级视频识别分开进行,缺少了两者之间潜在的交互关系,降低了事件定位和事件内容理解的关联性,同时也影响了定位的准确性。于是一种更简单有效的端到端密集视频检测方法应运而生。
3、端到端密集视频检测任务将事件定位和片段级视频字幕识别同时进行,常用的方式是构建两个并行的预测头——事件定位头和视频字幕识别头,将从视觉编码器中提取的帧图像特征与可学习的事件查询特征在模型中融合,得到中间特征,将其直接解码为具有时间定位和相应字幕的事件集。可学习的事件查询特征通常为固定长度,为了适配不同长度的视频,通常会额外需要一个事件计数器堆叠在解码器顶部,进一步预测最终事件的数量。端到端密集视频检测的模型结构更为简单,同时也能有效解决两阶段任务中事件定位和片段级视频字幕识别缺少潜在关联的问题。
4、大规模语言模型(llm)目前是自然语言处理领域的一大热点,在文本理解、推理等复杂任务中展现了非凡的能力。以大规模语言模型为基座的各领域模型层出不穷,通过利用预训练好的大型语言模型、预训练好的图像编码器和额外的可学习的适配器,在多模态语料的有监督微调下就可以获得多模态大规模语言模型(mllm)。多模态大语言模型不仅继承基座强大的文本内容识别能力,还可以深入理解图像模态的内容,执行复杂的多模态任务(例如图像理解、图像问答等)。近期在多模态领域的研究成果证明,在多模态大语言模型的基础上对广泛的下游任务进行微调可以得到非常可观的效果,如视觉问答、视觉常识推理。基于多模态大语言模型的端到端密集视频检测可以有效发挥大语言模型的视觉内容理解的能力,增强事件定位的准确性。
5、密集视频检测任务需要模型具备理解复杂视频内容的能力,传统的密集视频检测模型参数量少、结构简单、训练的数据量不足,导致模型对于视频的理解不够全面、分段不准确。而以大规模语言模型为基座的多模态大语言模型已展现了强大的视觉理解能力,为密集视频检测任务提供了新的解决思路,但是密集视频检测任务的数据量不足,无法达到训练多模态大语言模型的条件,现有的解决技术是提取视频的音频,将音频转录成文本进行数据增强,但存在操作复杂、转录的文本中有效内容较少、音频内容与视频内容不符等问题。
技术实现思路
1、本发明的目的是针对密集视频检测的模型结构简单、分段不准确、视觉理解不足的问题,提出一种基于大规模语言模型的密集视频检测方法。
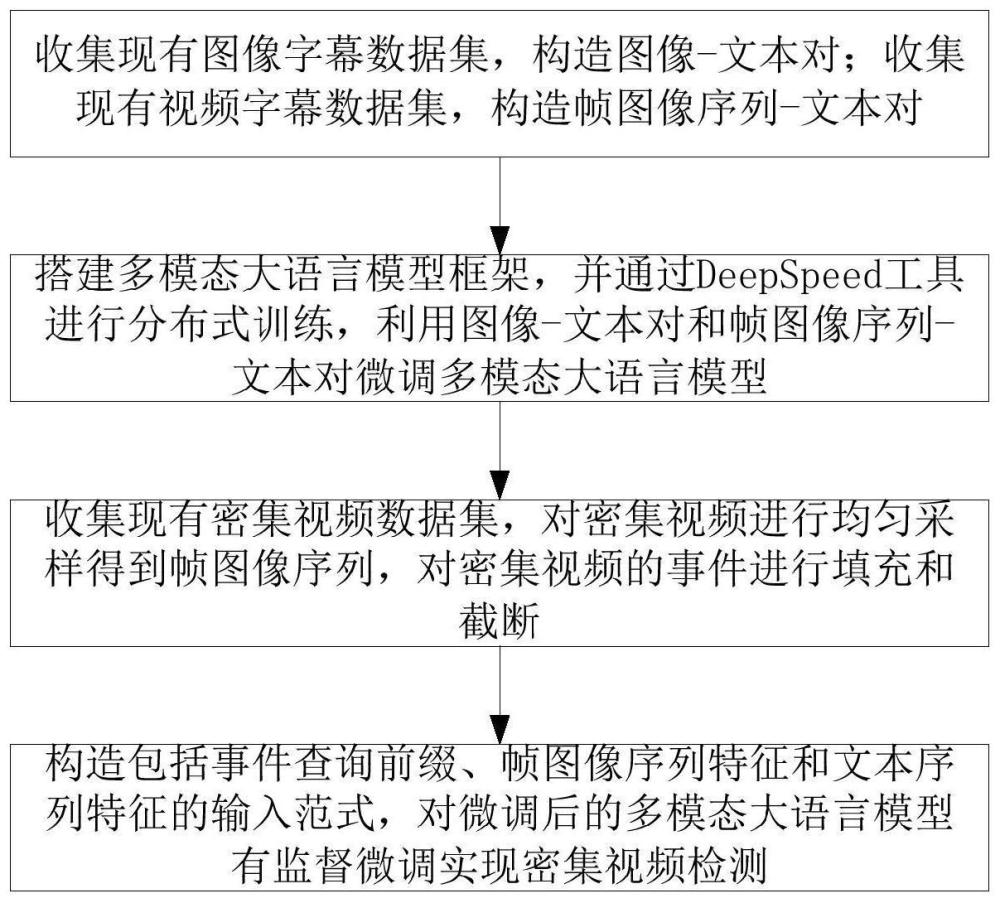
2、本发明提供一种基于大规模语言模型的密集视频检测方法,包括:
3、步骤1:收集现有图像字幕数据集,构造图像-文本对;收集现有视频字幕数据集,构造帧图像序列-文本对;
4、步骤2:搭建多模态大语言模型框架,并通过deepspeed工具进行分布式训练,利用图像-文本对和帧图像序列-文本对微调多模态大语言模型;
5、步骤3:收集现有密集视频数据集,对密集视频进行均匀采样得到帧图像序列,对密集视频的事件进行填充和截断;
6、步骤4:构造模型输入范式,包括事件查询前缀、帧图像序列特征和文本序列特征,对步骤2微调后的多模态大语言模型有监督微调实现密集视频检测。
7、进一步的,所述步骤1具体为:
8、步骤1.1:收集图像字幕任务的公开数据集,构造图像-文本对;
9、步骤1.2:收集视频字幕任务的视频文本对,对视频均匀采样得到帧图像序列,构造帧图像序列-文本对。
10、进一步的,所述步骤2具体为:
11、步骤2.1:搭建多模态大语言模型框架,包含图像编码器、多模态adapter和大规模语言模型;
12、步骤2.2:利用deepspeed工具搭建分布式训练环境,训练方式采用zero-3数据并行;
13、步骤2.3:冻结图像编码器参数,利用图像-文本对和帧图像序列-文本对全参数微调多模态adapter和大语言模型。
14、进一步的,所述步骤2.1中图像编码器使用预训练好的clip模型中的vit模型,多模态adapter采用mlp模型,大规模语言模型选用llama2-7b模型;通过vit模型对图像单模态编码,再通过多模态adapter将图像特征映射到llm的文本表示空间上,在训练的过程中冻结vit模型,在多模态adapter和llm中进行多模态对齐。
15、进一步的,所述步骤3具体为:
16、步骤3.1:收集密集视频检测任务的公开数据集,对密集视频均匀采样得到帧图像序列并将事件定位的时间与帧序列对齐;
17、步骤3.2:统计密集视频数据集中每个视频的事件数量,选择事件数量最大值n,对事件数量少于n的视频用{0,0}将事件数量填充到n,其中{0,0}表示所填充事件的事件起始帧号和终止帧号都为0,对事件数量超过事件最大值n的视频采取事件截断操作,删除多余的事件。
18、进一步的,所述步骤3.1中对视频均匀采样出100帧图像,删除少于100帧的视频。
19、进一步的,所述步骤3.2中事件数量最大值n的选择依据是密集视频数据集中事件数量小于等于n的视频占比向下取整为90%;事件定位任务的难点在于对事件起始时间和终止时间的预测,需要将事件起始时间和终止时间的预测转换为事件起始帧号和终止帧号的预测。
20、进一步的,所述步骤4具体为:
21、步骤4.1:训练开始时将帧图像序列通过图像编码器获得帧图像序列特征;将每个事件对应的文本通过大规模语言模型的embedding层得到文本序列特征;
22、步骤4.2:随机初始化事件查询前缀,事件查询前缀由一组可学习向量表示,将事件查询前缀与步骤4.1得到的帧图像序列特征和文本序列特征拼接构成模型输入范式,将输入范式输入到多模态大语言模型;
23、步骤4.3:用可学习的事件查询前缀一对一地预测事件的起始帧号和终止帧号,将事件定位转换为集合预测任务,计算模型训练的损失。
24、进一步的,所述步骤4.2中的模型输入范式中帧图像序列通过特殊字符[sep]分割;文本序列通过特殊字符[event]分割。
25、进一步的,所述步骤4.3中模型的loss函数的表达式为:
26、loss=eventce+eventgiou+captionce
27、其中,loss表示模型的损失函数,eventce表示预测的事件起始帧号和终止帧号与真实的事件起始帧号和终止帧号的交叉熵损失;eventgiou表示预测的事件范围与真实的事件范围的giou损失;captionce表示预测的文本序列与真实的文本序列之间的交叉熵损失;视频中真实的事件起始帧号和终止帧号表示为视频中真实的文本序列表示为[x1,x2…xn],其中1≤n≤n,c表示帧图像序列中的图像数量,n表示视频中的事件数量,s表示起始帧,e表示终止帧;事件查询前缀特征的长度为2n,通过大语言模型后,经过事件定位头映射到帧数的表示空间,得到对应到c+1帧的预测概率其中0≤k≤c;
28、根据下式利用交叉熵损失计算预测的事件起始帧号、终止帧号与真实的事件起始帧号、终止帧号的差距:
29、
30、其中,uk表示帧号为i的onehot表示;表示事件n的起始帧号为k的概率,表示事件n的终止帧号为k的概率。
31、根据下式利用giou损失来约束计算预测的事件范围与真实的事件范围:
32、
33、其中,a表示预测的事件范围,b表示真实的事件范围,d表示能够包含a和b的最小范围;
34、根据下式利用交叉熵损失计算预测的文本序列与真实的文本序列之间的差距:
35、
36、其中,l表示文本长度,p(ynh|xn,yn)表示事件n的字幕在预测第h个词时的概率,xn是真实的文本,yn是预测的文本,ynh是预测的文本的第h个词,yn,<h是预测的文本的前h-1个词。
37、本发明的一种基于大规模语言模型的密集视频检测方法,至少具有以下有益效果:
38、1、本发明利用图像字幕任务和视频字幕任务的数据集有监督微调多模态大语言模型,让模型具备理解图像-文本对和帧图像序列-文本对的对齐关系的能力,并有效缓解密集视频数据量不足的问题。
39、2、本发明将密集视频检测任务与多模态大语言模型相结合,有效利用了多模态大语言模型的视觉理解能力,展示了将密集视频检测等复杂任务集成到大规模预训练模型中的可行性。
- 还没有人留言评论。精彩留言会获得点赞!