基于资源引用关系模型实现低代码全量资源的重构方法与流程
本发明涉及应用程序开发,尤其涉及基于资源引用关系模型实现低代码全量资源的重构方法。
背景技术:
1、低代码开发平台是一种允许开发人员使用图形化界面来创建软件应用程序的软件平台,通过将构建软件抽象为数据实体、业务逻辑动作、页面树形、图形化配置的dsl(domain specific language,领域专用语言)资源,代替部分传统纯文本代码以实现开发效率的提升。为保证开发效率,低代码平台需要提供与ide(integrated developmentenvironment,集成开发环境)类似的功能,例如缺失依赖提醒、查找引用、重构(重命名、移动)。
2、重构功能可以帮助开发人员在保持软件功能不变的情况下,对软件代码进行优化,提高软件的可维护性和可扩展性。传统ide对纯文本代码提供包(package)、类(class)、方法(method)、变量(variable)的重构功能。相比之下,低代码的资源类型要多得多,相互关系也更加复杂,很多低代码平台干脆直接禁止修改已创建的资源名称,试图避免此问题。但是随着开发版本的不断迭代,维护人员会越来越难以忍受这种不合理的限制,因此我们需要设计一套全新的解决方案满足这些需求。
技术实现思路
1、为了克服上述缺点,本发明提供基于资源引用关系模型实现低代码全量资源的重构方法。
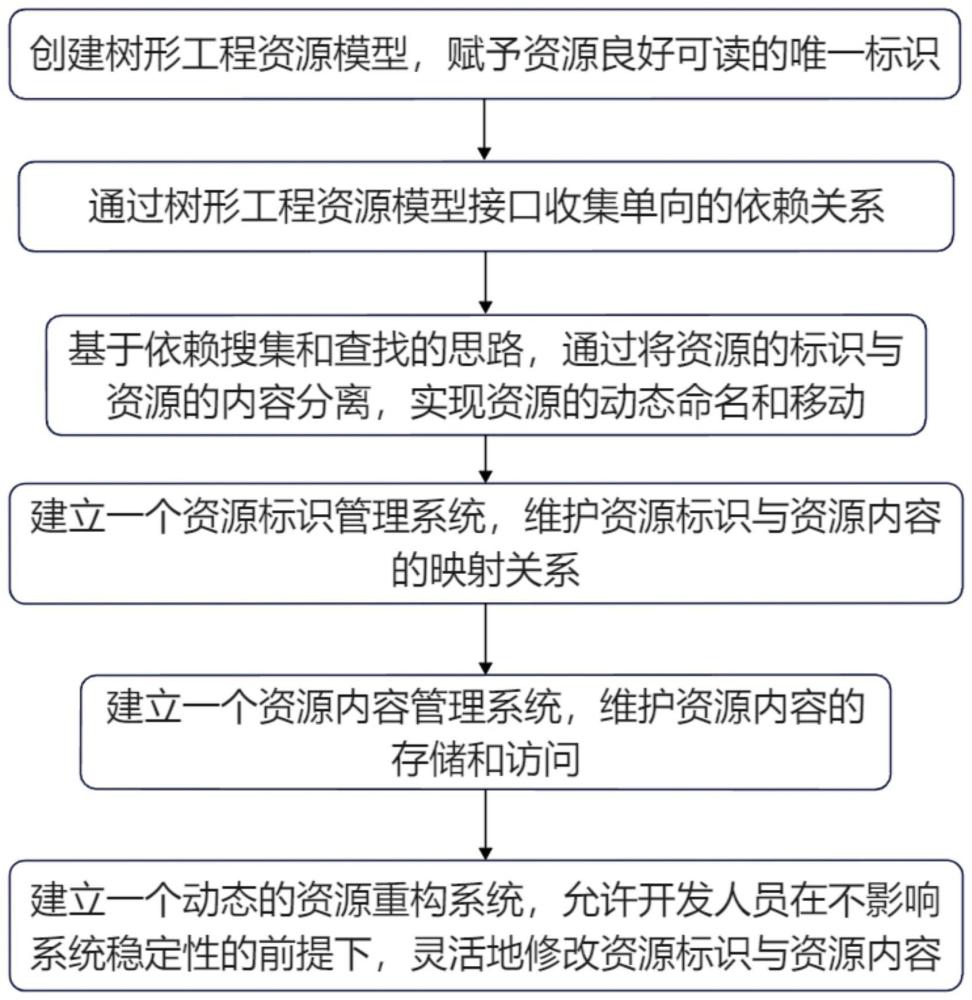
2、技术方案是:基于资源引用关系模型实现低代码全量资源的重构方法,包括以下阶段:
3、阶段一、构建树形工程资源模型
4、以树形工程资源模型为载体,赋予资源良好可读的唯一标识(例如:模块名.实体名)。树形工程资源模型支持多种资源类型,如函数、变量、组件,每种资源类型都有自己的属性和方法。具体流程如下:
5、定义资源类型的元数据,包括资源类型的名称、描述、属性、方法、事件。
6、定义资源间的关系类型的元数据,包括关系类型的名称、描述、源资源类型、目标资源类型、关系特征、关系约束。
7、采用低代码平台自身的编程语言及工具,来实现资源模型的数据结构和功能接口。
8、设计树形工程资源模型的数据结构,以便存储和操作资源及其关系。
9、设计树形工程资源模型的功能接口,包括创建、删除、修改、查询、导入、导出、复制、粘贴、拖拽操作,以及收集、查找、更新、同步依赖关系的操作。
10、优选地,所述树形工程资源模型还支持资源的动态加载和卸载,即在运行时可以根据需要增加或删除资源,而不影响其他资源的正常运行。具体流程如下:
11、设计树形工程资源模型的加载和卸载接口,包括添加、删除、启用、禁用操作,以及相应的事件和回调函数。
12、实现树形工程资源模型的加载和卸载逻辑,采用懒加载、预加载、缓存策略,以提高性能和节省内存。
13、调用树形工程资源模型的依赖分析接口,检查资源的加载和卸载是否会影响其他资源的正常运行,如果有,提醒用户并给出解决方案。
14、提供一个用户界面,展示树形工程资源模型的当前状态,以及可用的加载和卸载操作,让用户可以灵活地控制资源的生命周期。
15、阶段二、收集依赖关系
16、通过树形工程资源模型的功能接口,执行时,从树的根节点开始,深度遍历至叶子节点。通过资源类型和唯一标识可以定位唯一的资源,通过树形工程资源模型接口收集单向的依赖关系。采用线性数据结构作为容器,内容包含:(资源类型、资源标识、被依赖资源类型、被依赖资源标识、依赖方式)。具体流程如下:
17、遍历树形工程资源模型的树形结构或图形结构,从根节点开始,深度优先或广度优先地访问每个资源节点。
18、对于每个访问的资源节点,调用树形工程资源模型的功能接口,获取该资源节点的所有依赖关系,包括被依赖的资源类型、资源标识、依赖方式信息。
19、将每个资源节点的依赖关系存储在一个线性数据结构中,如数组、列表、队列。
20、对于每个需要查找的资源节点,根据其资源标识,在线性数据结构中进行线性查找,返回其依赖关系的信息。
21、阶段三、资源标识与资源内容的分离与管理
22、基于依赖搜集和查找的思路,使用数据结构来存储和管理资源间的依赖关系:首先通过将资源的标识(如名称、路径)与资源的内容(如属性、方法、依赖)分离,实现资源的动态命名和移动,而不影响资源的功能和关系。然后,建立一个资源标识管理系统,维护资源标识与资源内容的映射关系,实现资源标识的统一管理和查询,以及资源标识的变更和同步。再建立一个资源内容管理系统,维护资源内容的存储和访问,实现资源内容的增删改查,以及资源内容的版本控制和回滚。具体流程如下:
23、将资源的标识(如名称、路径)与资源的内容(如属性、方法、依赖)分离,采用两个不同的数据结构来存储,如一个树形结构存储资源标识,一个哈希表存储资源内容。
24、创建一个资源标识管理系统,维护资源标识与资源内容的映射关系,使用一个哈希表,以资源标识为键,资源内容的哈希值为值。
25、创建一个资源内容管理系统,维护资源内容的存储和访问,使用关系型数据库mysql,并选择键值对数据模型,将资源内容作为一个不透明的对象,用一个唯一的键来标识和访问。
26、优选地,所述资源标识管理系统的创建流程如下:
27、定义一个哈希表类,使用一个数组作为底层存储结构,数组的长度为一个合适的素数,如17,以减少哈希冲突的概率。
28、定义一个哈希函数,根据资源标识的类型和值,计算出一个整数,然后对数组的长度取模,得到哈希值,作为数组的下标。
29、定义一个节点类,包含资源标识和资源内容的哈希值两个属性,以及一个指向下一个节点的指针,作为数组的元素类型。
30、在哈希表类中,实现插入、删除、修改、查询操作,如果发生哈希冲突,采用链地址法解决,即将冲突的节点链接在同一个数组下标的链表中。
31、在哈希表类中,实现导入、导出、复制、粘贴、拖拽操作,如果涉及到资源标识的变更,需要同步更新哈希表中的节点位置和资源内容的哈希值。
32、在哈希表类中,实现映射关系的变更和同步操作,如果资源内容的哈希值发生变化,需要通知资源标识管理系统,更新对应的节点属性。
33、优选地,所述资源内容管理系统的创建流程如下:
34、根据硬件和软件环境,安装和配置好my sql数据库引擎和相关的工具和服务。
35、由于资源内容是非结构化的,选择键值对模型,将资源内容作为一个不透明的对象,用一个唯一的键来标识和访问。
36、选择一个合适的键值数据库,如mongodb、redis、cassandra,安装和配置好数据库引擎和相关的工具和服务。
37、设计数据库的名称和文件组,根据数据的逻辑划分和物理存储,指定文件组的大小、增长、位置属性。
38、设计数据库的文件,根据文件组的划分,指定文件的大小、增长、位置属性。
39、设计数据库的键值对存储,根据键值对模型的特点,指定键值对的格式、编码、压缩、过期、排序规则、恢复模式属性。
40、使用my sql management studio或其他工具,创建的数据库和数据库对象;并在my sql数据库引擎中执行。
41、测试的数据库和数据库对象,确保它们能够正确地存储和访问的资源内容,以及满足的性能和安全要求。
42、阶段四、动态资源重构
43、建立一个动态的资源重构系统,允许开发人员在不影响系统稳定性的前提下,灵活地修改资源标识与资源内容。具体流程如下:
44、设计一个动态资源重构系统,接收参数(资源类型,原资源标识,新资源标识),根据参数判断如果本资源受到影响,则对自身做相应调整、收集预览更改信息和可能存在的问题,当用户确认修改后再做持久化处理。
45、设计动态资源重构系统的功能逻辑,采用面向对象的编程语言,如java、c#、python,或者使用低代码平台自身的编程语言或工具。
46、调用资源标识管理系统和资源内容管理系统的功能接口,实现资源标识与资源内容的修改、查询、同步、版本控制、回滚操作。
47、调用资源模型的功能接口,实现资源及其依赖关系的更新、同步操作。
48、提供一个用户界面,展示资源重构的预览效果和问题提示,以及确认和取消的选项。
49、优选地,还包括有阶段五、依赖缺失提醒与引用查找:
50、在资源标识管理系统中,使用线性查找功能,遍历资源模型中的每个资源节点,检查其哈希表中是否有缺失的资源标识的哈希值,如果有,将其标记为错误,并在用户界面中显示错误信息和建议的修复方法。
51、在资源内容管理系统中,使用搜索功能,输入要查找资源内容的关联资源,查询其在资源库中的位置和状态,以及与其相关联的其他资源,如果有,将其高亮显示,并在用户界面中显示相关信息和操作选项。
52、有益效果:1、通过构建树形工程资源模型以及资源标识与资源内容的分离与管理,提高了低代码开发平台的资源管理效率和质量,使开发人员可以更快地构建和修改应用程序,减少了错误和冲突的风险影响。
53、2、缺失依赖提醒功能可以帮助开发人员快速发现和定位错误;资源内容的引用查找功能可以协助开发人员理解软件结构、判断修改影响范围。
54、3、优化了低代码开发平台资源重构的用户体验和交互,使开发人员可以更直观地查看和控制资源及其关系,提供了丰富的功能接口和用户界面,提高了用户的满意度和信任度。
- 还没有人留言评论。精彩留言会获得点赞!