一种基于多FPGA的大规模卷积神经网络加速与部署器实现方法
本发明设计属于fpga硬件加速器,提出一种在多fpga系统上实现卷积神经网络的方法,具体是一种基于多fpga的大规模卷积神经网络加速与部署器实现方法。
背景技术:
1、近年来,fpga在神经网络硬件加速领域受到了极大的关注。在硬件上实现卷积神经网络(cnn)时,传统的方法通常是在cpu以及gpu上训练并且推理的,但是fpga可以提供独特的优势。首先,fpga可以并行化地处理数据。虽然gpu可以利用多个处理器来加速一批数据,但是其计算模式是串行的,也就是说,在处理一张特征图时,其无法保证低延迟。与之相比,fpga可以利用可重构的电路特性提供并行的计算方式,同时支持流水线计算,提供可控的、低延迟的输出。其次,cpu与gpu的能量使用效率较低,使其无法部署到能源受限的环境中,而fpga由于工作的时钟频率较低,具有很低的功耗。综上所述,fpga被认为是cnn加速器部署的高效平台。
2、然而,目前使用fpga加速cnn仍然存在挑战,近年来,cnn被用于处理更多复杂的问题,虽然仍能够保证很高的准确度,但是其网络的复杂性极大程度地增加了。网络规模的增加要求fpga有更高的资源,如内存,带宽和逻辑单元,以实现低延迟和高吞吐量的计算。然而,即使是非常先进的fpga,如intel stratix 10,每个时钟周期能够实现5000次的乘加操作,依然少于典型的cnn(如vgg-16或resnet)中单层操作的总数。这导致了哪怕是这种高端的fpga,在处理大规模的卷积神经网络时,也没有办法实现低延迟(10ms)或高吞吐量(超过60张图片每秒)。而这种要求在当今的各种应用场景下,尤其是视频流的处理中,是较为常见的。因此,提高大规模cnn部署在fpga上时的性能是十分必要的。
3、在现有的研究中,在单个fpga上实现大规模卷积神经网络依然是主流。为了提高计算速度,大部分的研究聚焦在fpga上对数据进行量化,减少数据的位宽,使得计算效率提高,但是这种做法往往会导致精度的下降(2022年发表于ieee transactions oncomputer-aided design of integrated circuits and systems的mlognet:alogarithmic quantization-based accelerator for depthwise separableconvolution)。此外,有一部分研究尝试将大规模的cnn网络部署到多个fpga上,但是在处理多个fpga的计算映射没有正确地平衡fpga的工作负载,导致推理过程中部分fpga的闲置,计算效率下降(2021年发表于acm journal on emerging technologies in computingsystems的toward multi-fpga acceleration of the neural networks)。
技术实现思路
1、为了解决大规模卷积神经网络在fpga上部署时,性能有限,速度较慢的问题,本发明提出了一种通用的基于多fpga的大规模卷积神经网络加速与部署的实现方法。可以将大规模的cnn网络部署在由多个fpga组成的系统上,并且保证所有的fpga在工作负载平衡的同时尽可能减少闲置的时间。
2、本发明的技术方案:
3、一种基于多fpga的大规模卷积神经网络加速与部署器实现方法,步骤如下:
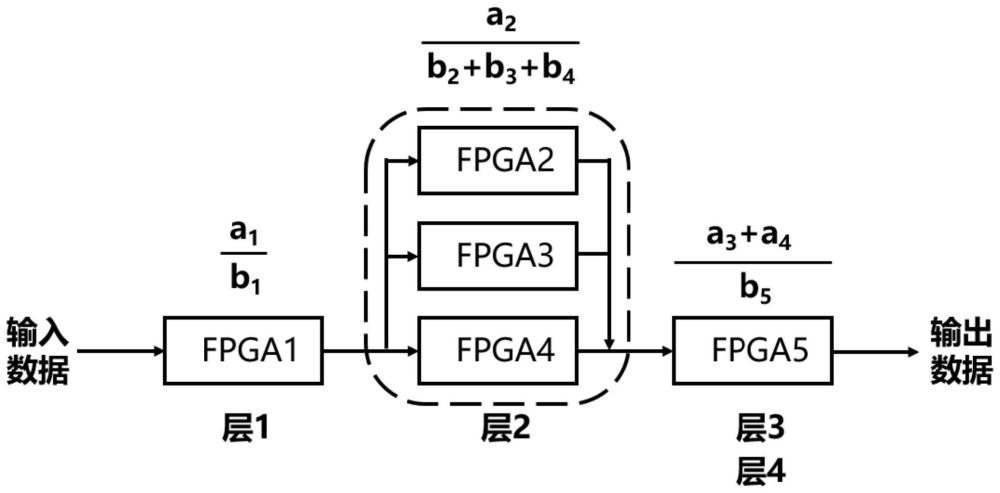
4、步骤1:根据需要部署的卷积神经网络与fpga的数量进行时间配平
5、步骤1.1:确定需要部署的卷积神经网络的层数与计算量
6、确定层数和计算量仅考虑计算密集型的操作,包括卷积层和全连接层,不考虑池化层;确定计算量时只考虑乘法计算,即处理该层时需要多少次乘法;确定需要部署的卷积神经网络为n层,每层计算量分别为a1,a2…an;
7、步骤1.2:确定可使用的fpga数量与每个fpga的dsp数量
8、确定一个fpga上的dsp数量时,以一个fpga上可用dsp数量的80%为准;确定可以使用的fpga数量为m,每个fpga上的dsp数量分别为b1,b2…bm;
9、步骤1.3:使用步骤1.1与步骤1.2获得的计算量和dsp数量进行时间配平
10、配平的具体方式:确定若干个分式,分式的分母为b1,b2…bm中任意数量个数据的加法,分式的分子为a1,a2…an中任意数量个数据的加法,使得确定的这些分式的方差最小;需保证每个数据仅可使用一次,并且一个分式的分子、分母之中只能存在一个加法组合;进行加法组合时,如果是代表计算量的数据,数据下标必须是连续的,如果是代表dsp数量的数据则没有限制;
11、步骤2:将全连接计算视为特殊的卷积计算,为步骤1.1中确定的层在fpga上设计相应的卷积计算结构
12、步骤2.1:根据步骤1.3中确定的分式,提取出需要在一个fpga上实现的计算,为每一个分式单独设计硬件结构;并且根据分式情况的不同,采用步骤2.2到2.4中的不同方法;设计卷积计算结构时,所有的权重保存在fpga的pl端;
13、步骤2.2:如果分式的分子和分母都仅有一个数据,则一个fpga计算一层的卷积;使用如图1所示的脉动阵列进行卷积计算;该脉动阵列根据卷积窗口的大小确定宽度,在此基础上长度尽可能长,确保一次计算能计算尽可能多的输入通道;
14、步骤2.3:如果分式的分母是多个数据的加法组合,分子是一个数据,则多个fpga计算一层的卷积;此时根据分母中多个数据的比值划分该层的输出通道数,每个fpga计算一部分输出通道;在每个fpga上设计卷积计算结构时,按照步骤2.2的方法设计;
15、步骤2.4:如果分式的分子是多个数据的加法组合,分母是一个数据,则一个fpga计算多层的卷积;此时根据分子中的多个数据的比值划分fpga中的dsp,使用被划分的dsp设计卷积计算结构处理一层的计算,之后按照分子中数据的下标顺序将其级联,形成流水线;单层计算按照步骤2.2的方法设计;
16、步骤3:级联fpga,完成部署
17、步骤3.1:补充非计算密集型的硬件设计:在对应的fpga中对输出数据增加激活、池化和softmax的计算;
18、步骤3.2:将步骤1.3中得到的分式按照分子的数据下标排序,之后将分母数据的对应的fpga按照该顺序级联,存在多个fpga计算一层的情况时,先将输出结果合并到一个fpga上再级联;
19、步骤3.3:将级联的第一个fpga连接到输入数据流,级联的最后一个fpga连接到接收数据的设备,完成多fpga的卷积神经网络流水线部署。
20、本发明的有益效果:
21、本发明提出的基于多fpga的大规模神经网络加速与部署方法,可以将大规模的卷积神经网络部署在由多个fpga组成的系统上,实现均衡的流水线设计,从而提高加速器的计算效率。
技术特征:
1.一种基于多fpga的大规模卷积神经网络加速与部署器实现方法,其特征在于,步骤如下:
技术总结
本发明设计属于FPGA硬件加速器技术领域,公开了一种基于多FPGA的大规模卷积神经网络加速与部署器实现方法,步骤如下:步骤1:根据需要部署的卷积神经网络与FPGA的数量进行时间配平;步骤2:将全连接计算视为特殊的卷积计算,为确定的层在FPGA上设计相应的卷积计算结构;步骤3:级联FPGA,完成部署。本发明提出的基于多FPGA的大规模神经网络加速与部署方法,可以将大规模的卷积神经网络部署在由多个FPGA组成的系统上,实现均衡的流水线设计,从而提高加速器的计算效率。
技术研发人员:马艳华,宋泽睿,徐琪灿
受保护的技术使用者:大连理工大学
技术研发日:
技术公布日:2024/3/17
- 还没有人留言评论。精彩留言会获得点赞!